Ускорение 1С: оптимизация, повышение скорости работы. 1С оптимизация
Ускорение 1С, оптимизация, как ускорить работу 1С
Во многом оптимизация 1С и скорость работы зависит от работы с блокировками, запросами и индексами. Постараемся ответить на вопрос «как ускорить работу 1С» (вопрос, как ускорить запуск 1С, мы рассмотрим в другой статье) и избежать жалоб пользователей на «долгое проведение документов», которое неминуемо сказывается на бизнес-процессах.
1С Управляемые блокировки
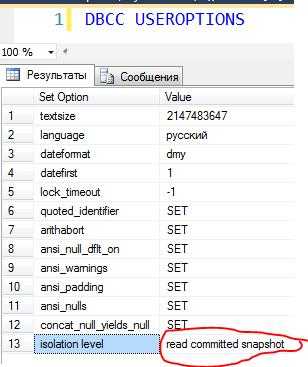
Механизм блокировок был вынесен на сервер 1С, а на уровне СУБД изоляция снизилась до минимума. На MS SQL уровень изоляции был понижен до Read Committed с механизмом разделяемых блокировок на платформе 8.2 и механизмом версионирования строк на платформе 8.3 (так называемый Read Committed Snapshot Isoliation). Точнее, это одноименное свойство базы данных и два режима работы Read Committed, зависящие от этого параметра.
При последнем уровне изоляции (RCSI), механизм позволил не пересекаться на сервере СУБД читающих и пишущих транзакций по одним и тем же ресурсам. Всю основную работу на себя взял сервис блокировки 1С, определяющий на основании родных метаданных, пускать или не пускать транзакции на сервер СУБД, чтобы не происходило нарушений бизнес-логики. Проблемы с блокировками пустых таблиц и приграничных диапазонов ушли в прошлое.
| Автоматические блокировки | |||
| Файловая База Данных | Таблиц | Serializable | Dirty read |
| MS SQL Server | Записей | Repetable Read или Serializable | Dirty read |
| IBM DB2 | Записей | Repetable Read или Serializable | Dirty read |
| PostgreSQL | Таблиц | Serializable | Consistent reading |
| Oracle Database | Таблиц | Serializable | Consistent reading |
| Управляемые блокировки | |||
| Файловая База Данных | Таблиц | Serializable | Dirty read |
| MS SQL Server 2000 | Записей | Read Commited | Dirty read |
| MS SQL Server 2005 и выше | Read Commited Snapshot | Consistent reading | |
| IBM DB2 до версии 9.7 | Записей | Read Commited | Dirty read |
| IBM DB2 версии 9.7 и выше | Записей | Read Commited | Consistent reading |
| PostgreSQL | Записей | Read Commited | Consistent reading |
| Oracle Database | Записей | Read Commited | Consistent reading |
Для того чтобы узнать, в каком режиме блокировок находится база программы 1С, необходимо выполнить следующий запрос из SSMS в контексте нужной базы:
Блокировки 1С. Пользователь не будет ждать на блокировках, произойдет ускорение работы 1С, если придерживаться определенных правил:
- Продолжительность транзакций должна быть максимально сокращена по времени. Проведение в транзакции длительных расчетов в 100% случаев приведет к блокировке при работе на OLTP системе.
- Исключены длительные внешние операции в рамках транзакции, например, отправка и принятие подтверждений по электронной почте, работа с файловой системой и другие дополнительные действия. Все операции должны быть вынесены в отложенные короткие задания.
- Максимально оптимизированы запросы.
- Создание индексов должно производиться только по мере необходимости, для обеспечения оптимальной производительности запросов в пределах приложения.
- Минимизированы включения в кластерный индекс часто обновляемых столбцов. Обновления столбца/ов кластерного ключа индекса требует блокировки, как на кластерном индексе, так и на всех некластеризованных индексах (так как их строка-локатор содержит ключ кластерного индекса).
- По возможности создан и используется покрывающий индекс для сокращения времени выборки данных.
- Использование самого низкого уровня изоляции транзакциями, что потребует перехода на режим управляемых блокировок.
Инструменты для диагностики блокировок:
- Технологический журнал;
- Центр управления производительностью из инструментария 1С;
- Облачные сервисы Гилева;
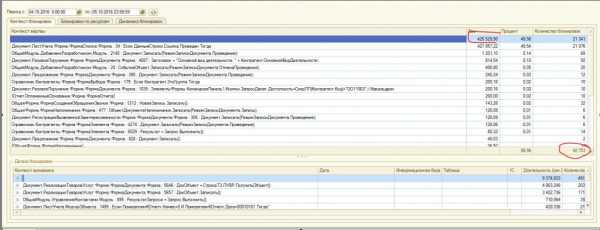
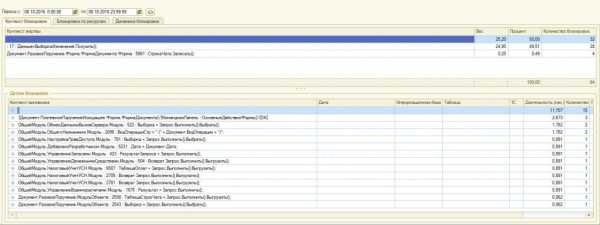
Ниже приведен пример мониторинга системы сервисом Гилева. Общая длительность блокировок ~15 часов. Более 400 активных пользователей. После принятия решений и оптимизации – время таймаутов меньше минуты, а количество блокировок сократилось в ~670раз.
Было:
Стало:
В ситуации, когда «все висит и долго проводиться», а сервисы мониторинга не настроены или не используются совсем, помня принцип Парето, необходимо сосредоточить внимание на коде.
В автоматическом режиме наличие блокировок на сервере можно обнаружить с помощью системной процедуры в контексте нужной базы. Данная хранимая процедура позволяет определить, в каком режиме работают блокировки, их статус, тип и прочее:
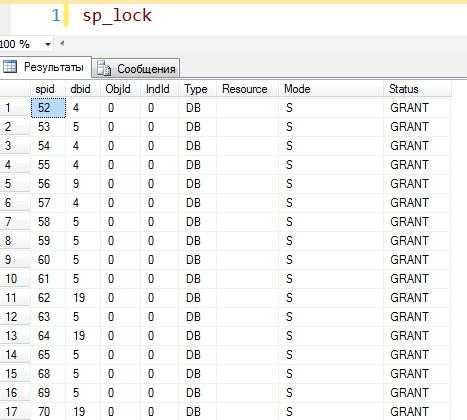
Доработав процедуру под 1С, можно получить наглядную информацию о том, что происходит в данный момент на сервере, с учетом специфики таблиц 1С:
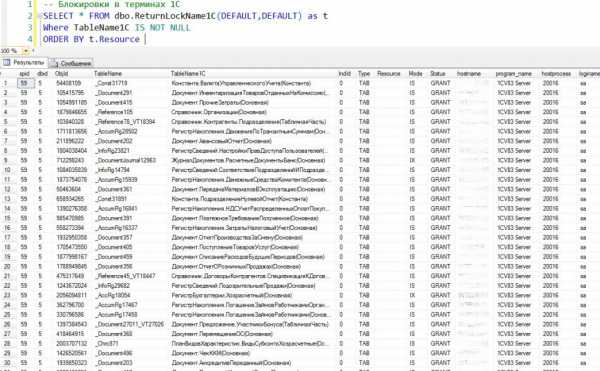
Применение данного механизма позволяет получить полную информацию об имеющихся блокировках на текущий момент. Если в отчете одни S-блокировки, проблема может заключаться в длительном запросе или запросах. Для установления причины и места их появления в коде можно пойти разными путями: использовать объекты DMO SQL-сервера (но учитываем, что данные из них сбрасываются после перезагрузки сервера) или настроить Data Collector, сохранив данные мониторинга в таблицах на определенное время. Главное, получить тексты проблемных запросов.
Использование индексов и их влияние на качество производительности системы
Очень много написано про индексы, о необходимости их использования и влияние на качество работы системы. Постараемся разобраться в тонкостях «устройства» индексов, вариантах применения и преимуществах перед обычными таблицами.
Индексирование является важной частью ядра СУБД. Отсутствующие индексы, или наоборот, их излишнее количество, влияют на скорость выборки, модификацию, добавление и удаление данных. Рассмотрим индексирование на примере наиболее распространенной СУБД компании Microsoft.
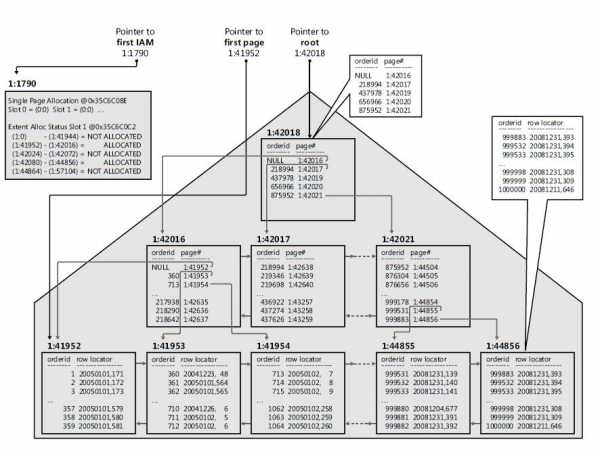
Для общего понимания, как это работает, рассмотрим подробности устройства механизмом хранения данных, которые мы обычно представляем в виде таблицы (например, Excel).
Единицей физического хранения данных является страница — модуль размером в 8 Кбайт, принадлежащий только одному объекту (например, таблице или индексу). Страница является наименьшей единицей для чтения и записи. Страницы собраны в экстенты. Экстент состоит из 8 последовательных страниц. Страницы экстента могут принадлежать как одному, так и нескольким объектам. Если страницы принадлежат нескольким объектам, экстент называется «смешанным».
Заголовок страницы (первые 96 байт) состоит из разных флагов, которые использует в работе ядро СУБД. Ее содержимое можно посмотреть ниже:

Строки с данными (8060 байт):

Таблица смещения (36 байт):

Получив представление, как устроена единица хранения данных на диске, поговорим подробнее о таблицах и индексах.
По умолчанию, если не использовать специальных операторов T-SQL, пустая таблица создается в виде «кучи» – простого набора страниц и экстентов. Данные в «куче» не имеют никакого логического порядка. Ядро SQL Server отслеживает принадлежность страниц и экстентов к определенному объекту с помощью специальных системных страниц, называемых «картами распределения индекса» (Index Allocation Map). Каждая таблица или индекс имеет по крайней мере одну страницу IAM, называемую «первой страницей IAM».
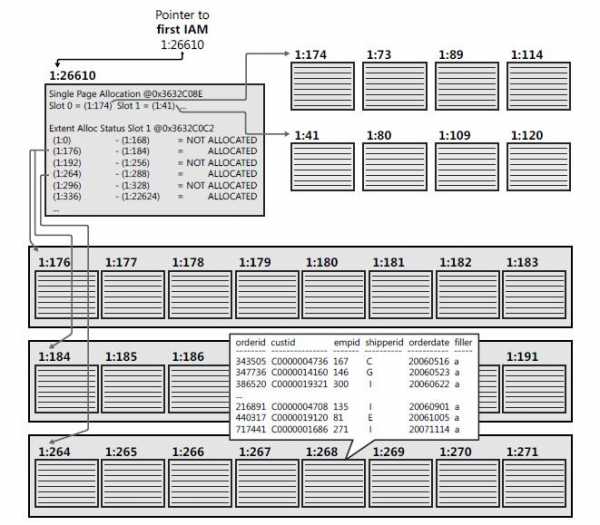
Таким образом, после создания обычной таблицы, по умолчанию, получается хаотичное расположение данных. Посмотреть статус таблицы можно с помощью следующей процедуры:
Основные индексы, которые использует платформа 1С
Мифы и реальность:
Миф первый: кластерные индексы и таблица данных – это две разные сущности, хранящиеся отдельно друг от друга.
Миф второй: кластерных индексов в одной таблице может быть много.
Скачал программу для оптимизации СУБД. Создал рекомендованные индексы. Скорость выборки увеличилась на 50%. Изменение и добавление данных замедлилось в 7раз.
Кластеризованный (кластерный) индекс
Кластеризованные индексы представляют собой набор страниц, которые сортируют и хранят строки данных в таблицах или представлениях на основе их ключевых значений – столбцов, включенных в определение индекса. Существует ограничение на данный вид индексов в 16 столбцов и 900 байт. Для каждой таблицы существует только один кластеризованный индекс, потому что строки данных могут быть отсортированы только в одном порядке. Создание кластеризованного индекса происходит посредством реорганизации таблицы, а не копирования данных, что дает возможность сохранить таблицу в виде сбалансированного дерева.
После добавления кластерного индекса таблица данных трансформируется:
Некластеризованный индекс
Некластеризованные индексы имеют структуру отдельную от строк данных. В некластеризованном индексе содержатся значения ключа кластерного индекса, и каждая запись содержит ключ кластеризованного индекса (не RID, т.к. таблицы 1С не используют кучи, за редким исключением).
Можно добавить неключевые столбцы на конечный уровень некластеризованного индекса и обойти существующее ограничение на ключи индексов (900 байт и 16 ключевых столбцов), выполняя полностью индексированные запросы.
После добавления некластерного индекса, произошло копирование данных, и появился еще один объект:
Схема кластерного индекса после получения его из кучи в виде сбалансированного дерева:
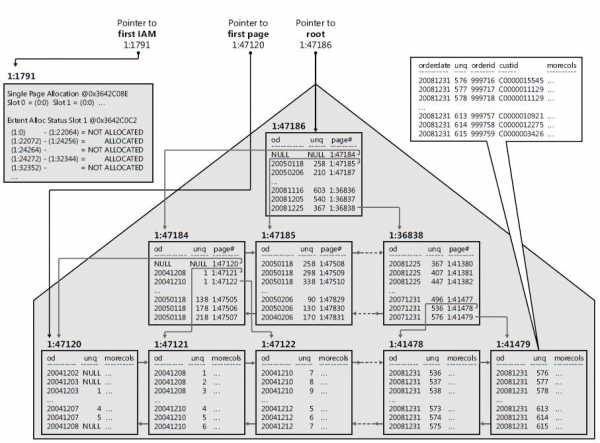
Схема некластерного индекса, полученного из кластерной таблицы (обратите внимание, столбец row locator имеет ключ кластерного индекса):
Влияние индексов на производительность запросов
Оптимизатор запросов, используя индекс, выполняет поиск по ключевым столбцам индекса, находит место хранения запрашиваемых строк и извлекает оттуда совпадающие строки. Поиск по индексу протекает намного быстрее, чем поиск по таблице, так как в отличие от таблицы, индекс часто содержит меньшее количество столбцов в каждой строке, а строки отсортированы по порядку.
Создание множества индексов приводит к тому, что скорость выборки увеличивается, а скорость записи при модификации существенно снижается. Для решения этой проблемы, в первую очередь, необходимо удалить ненужные индексы или предварительно заблокировать их не удаляя, что позволит просто включить их, в случае возникновения такой надобности.
Обратим внимание, что кластерный индекс блокировать ни в коем случае нельзя, т.к. это закроет доступ к данным таблицы. Это относится только к тем индексам, которые вы создали самостоятельно, через T-SQL. Причина создания индексов средствами T-SQL, минуя «1С:Предприятия», связана, в первую очередь, с ограниченными возможностями платформы 1С в части манипуляции индексами и включения в созданный/емый индекс дополнительных полей.
Инструкция T-SQL, которая выполняет действие по блокированию индекса:
Помимо вышеописанных действий, важно создать файловую группу на физическом диске, на котором не располагаются текущие файлы базы данных, и перенести туда некластерные индексы. Это позволит ускорить модификацию данных за счет распараллеливания их записи.
Определение необходимых или лишних индексов для ускорения выполнения запросов
По умолчанию 1С создает определенный базовый набор индексов. Зачастую, их просто не хватает. SQL-сервер имеет механизмы, которые позволяют понять на основании рабочей нагрузки, насколько необходимы имеющиеся индексы.
Помощник по настройке ядра СУБД (Database Engine Tuning Advisor) анализирует базы данных и составляет рекомендации по оптимизации производительности запросов. Его можно использовать для выбора и создания оптимальных наборов индексов, не обладая экспертным уровнем понимания структуры баз данных или внутренних процессов SQL Server. Помощник по настройке ядра СУБД позволяет выполнять следующие задачи:
- Устранение неполадок производительности конкретного проблемного запроса;
- Настройка большого набора запросов в одной или нескольких базах данных.
Объекты DMO (dynamic management objects), к которым относятся динамические административные представления и функции динамического управления. Например, инструкцией T-SQL можно получить все индексы, которые не использовались с момента последнего запуска сервера.
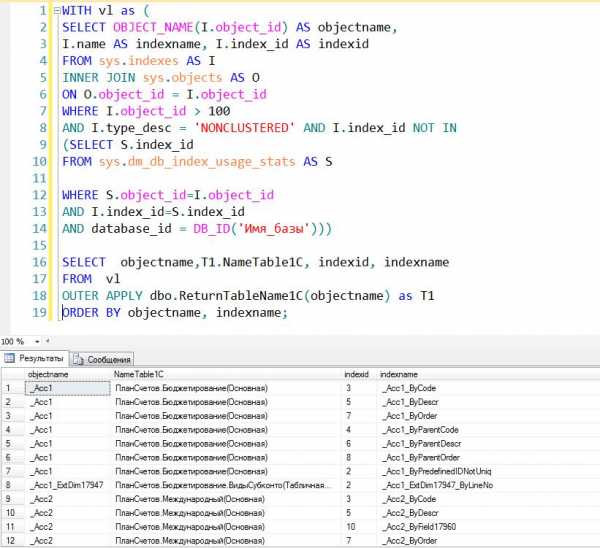
Инструкция, с помощью которой можно создавать необходимые индексы, которые рекомендует ядро СУБД:
Оптимизатор запросов во время генерации плана выполнения запроса выявляет необходимость создания недостающего индекса. Эту информацию он сохраняет в XML ShowPlan. Т.к. планы запросов хешируются и инструкции сохраняются (до следующего перезапуска сервера), то их можно извлечь, обработать и получить готовые инструкции создания необходимых индексов для любого плана выполнения в кэше. Стоит обратить внимание на частоту выполнения запроса: чем она выше, тем более актуальными являются результаты выполнения запроса и, соответственно, собранные показатели. Если запрос выполнялся единожды, его результаты не столь показательны.
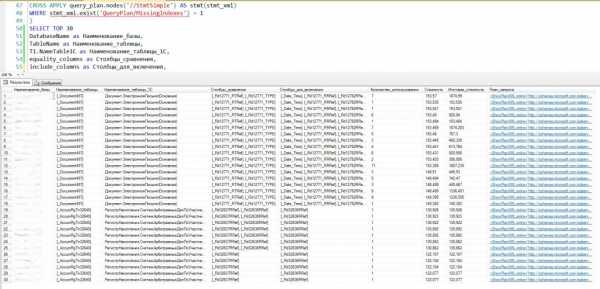
Некоторые особенности индексирования по агрегатным полям и полям сортировки.
Создание индекса на столбцах, указанных в предложении «УПОРЯДОЧИТЬ ПО» (ORDER BY), помогает оптимизатору запроса быстро организовать результирующий набор данных, так как значения столбцов отсортированы в индексе заранее. Внутренняя реализация механизма «СГРУППИРОВАТЬ ПО» (GROUP BY) также сначала сортирует значения столбцов для быстрой группировки необходимых данных.
При использовании типовых рекомендаций стоит проверять результат до и после оптимизации. Приведем пример использования логического объединения «ИЛИ» и его альтернативы (для устранения проблемы типовыми рекомендациями) – методики изменения запроса через синтаксис «ОБЪЕДИНИТЬ ВСЕ».
Сам запрос 1С с «ИЛИ»:
Модификация запроса с «ОБЪЕДИНИТЬ ВСЕ»:

Фактический план запроса (для удобства отображения и сравнения производительности, запросы перехвачены и выполнены в SSMS):
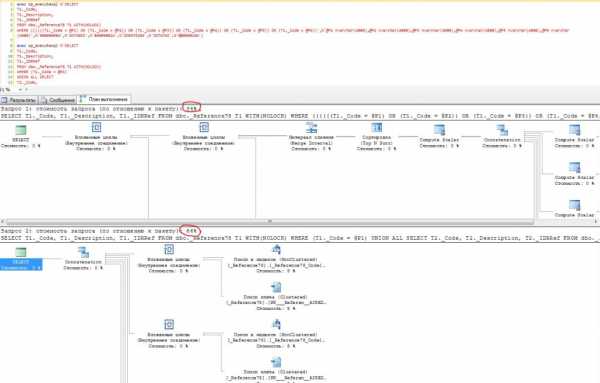
В данном случае, после оптимизации производительность упала в два раза из-за многократного использования оператора Key Lookup, который всегда сопровождается оператором Nested Loops. Поэтому, используя схему по оптимизации запроса, следует замерять целевое время до и после использования доработок. Данный пример показан с целью «доверяй, но проверяй», поскольку между типовыми рекомендациями и практическими задачами может быть несогласованность.
Автор: Ярастов Сергей,
Руководитель направления «Оптимизация высоконагруженных систем» департамента автоматизации «WiseAdvice»
wiseadvice-it.ru
Оптимизация производительности 1С
В большинстве случаев, как только специалисты сталкиваются с проблемой производительности, они начинают действовать наугад. Путём перебора различных вариантов надеются найти правильный в данной ситуации. Естественно это не самый лучший способ и очень часто задаются вопросом с чего начать и что лучше применить? Какова должна быть последовательность действий при возникновении проблем?

Получите 267 видеоуроков по 1С бесплатно:
Статьи по оптимизации производительности 1С для программистов
Методика повышения производительности 1С
Итак, с чего начать и как действовать правильно.
Если есть проблема производительности, первое, что необходимо сделать, нужно зафиксировать с помощью технологии APDEX текущую производительность. Узнать на сколько плохо система стала работать. Особенно это важно, если выполняется оптимизация не для своей компании, где вы являетесь штатным сотрудником, а выступаете в качестве внешнего эксперта.
Далее необходимо посмотреть, выполняется ли сервере СУБД регламентные операции, обновляется ли статистика, есть ли дефрагментация индексов? Если регламентные операции не выполняются, то их выполнение нужно настроить, запустить систему и проанализировать, как изменился APDEX. Оцениваем, изменилась ли производительность.
Следующий этап. Если регламентные операции включены и это не помогло, исследуем, выполняется ли эта операция в однопользовательском режиме, редко применимом на практике, или только в многопользовательском режиме. Если операция выполняется медленно и в однопользовательском режиме, то её довольно легко оптимизировать с помощью замера производительности в конфигураторе 1С. А вот если операция выполняется медленно только в многопользовательском режиме, тогда это очевидно проблемы связанные с параллельной работой. Здесь без посторонних инструментом используя один конфигуратор обойтись гораздо сложнее.
После сбора всех необходимый данных смотрим, можно ли ускорить систему без «апгрейда» оборудования. Как это узнать? Если видно, что есть не оптимальные запросы, ожидания на блокировках, то про «апгрейд» пока можно забыть. Есть ещё запас по оптимизации на уровне программного кода.
Заключительным этапом является регулярный мониторинг производительности. Обязательно должны быть установлены счётчики, которые будут показывать, насколько слажено работает система.
И как можно заметить у этого процесса есть начало, но нет логического конца. Производительность нужно отслеживать постоянно. Не важно, имеются ли в данный момент очевидные проблемы или нет.
К сожалению, мы физически не можем проконсультировать бесплатно всех желающих, но наша команда будет рада оказать услуги по внедрению и обслуживанию 1С. Более подробно о наших услугах можно узнать на странице Услуги 1С или просто позвоните по телефону +7 (499) 350 29 00. Мы работаем в Москве и области.
programmist1s.ru
Методы оптимизации 1С
Иногда что-то в программе может выполняться очень медленно. И тогда открытие документа или запись документа может длиться минуты или даже десятки минут.
Оптимизация – это процесс анализа существующей программы с целью изменения некоторой ее части, чтобы она выполнялась – быстрее, лучше, оптимальней.
Лучший способ оптимизации 1С – взять мега эксперта, гуру, посадить его за компьютер и он быстро во всем разберется и все оптимизирует.
Что делать если эксперта нет под рукой?
Оптимизация 1С программы
Согласно правилу: 20% программы выполняется 80% всего времени выполнения программы.
Поэтому в ходе оптимизации 1С переписывать программу с нуля или исправлять все, что не нравится в тексте программы – ошибочный путь, так как он ведет не к исправлению ошибок, а к написанию новой программы, в которой есть новые ошибки.
Вместо этого для оптимизации 1С нужно найти те самые 20% кода, которые все портят и исправить именно их.
Поиск события 1С
Главная подготовительная задача в проведении оптимизации 1С – найти место в программе (то есть модуль, функцию), которая вызывает впечатление пользователя, что «это долго работает».
Например, с точки зрения пользователя все просто – «это долго открывается». Но какая конкретная часть кода 1С выполняется при открытии?
Вот здесь мы уже обсуждали структуру модулей 1С и события 1С. Соответственно при открытии формы выполняется обработчики события:
- ПередОткрытием()
- ПриОткрытии()
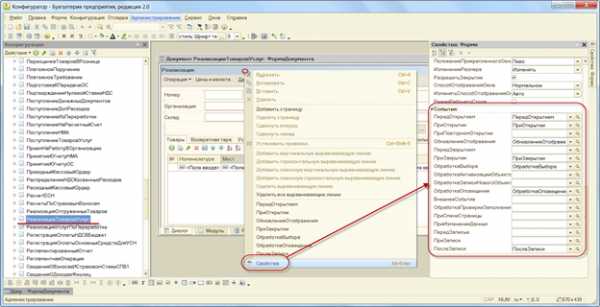
При записи и проведении документа выполняются обработчики в модуле 1С документа:
- ПередЗаписью()
- ПриЗаписи()
- ОбработчикПроведения()
- ПослеЗаписи().
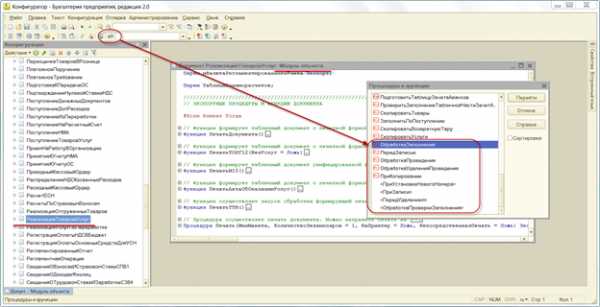
Дополнительно могут вызываться обработчики подписок на события 1С, которые находятся в конфигурации в ветке Общие/Подписки на события.
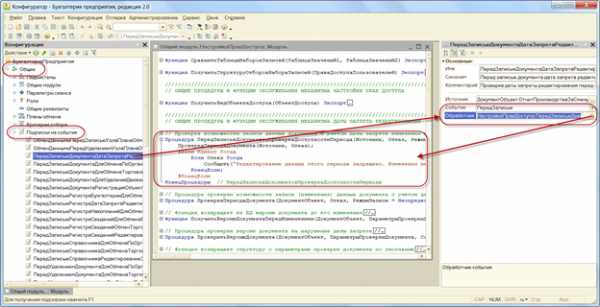
Начало процесса оптимизации 1С — отладка для поиска требуемого участка программы на языке 1С
Запускаем отладчик. Подробно мы рассматривали работу с отладчиком.
Вам необходимо определить нужное Вам событие, найти в модуле требуемую функцию-обработчик, установить точку останова в первой строчке функции обработчика и в последней строчке (то есть итого две точки останова).
После этого заходим в режим Предприятие (подключенный к отладке) и выполняем те действия, которые мы считаем «медленными» и требуют отладки, на события которых мы установили точку останова.
Если Вы правильно вычислили обработчик и установили точку останова, то выполнение программы остановится в начале функции.
Теперь необходимо включить – замер времени выполнения. Для этого выберите пункт меню Отладка/Замер производительности. Данный пункт после нажатия будет отмечен как «нажатый» и более ничего не произойдет. Не смущайтесь – переключайтесь снова в режим Предприятие и продолжайте работу до тех пор, пока программа снова не остановится – теперь уже на второй точке останова, в конце функции обработчика события.
Теперь необходимо выключить замер времени выполнения. Для этого нажмите на тот же пункт меню. Данный пункт будет отмечен как не нажатый.
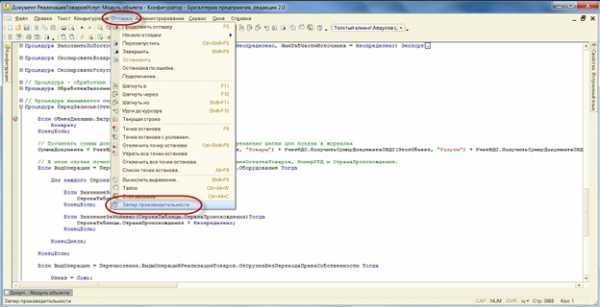
После отключения замера времени откроется окно результатов.
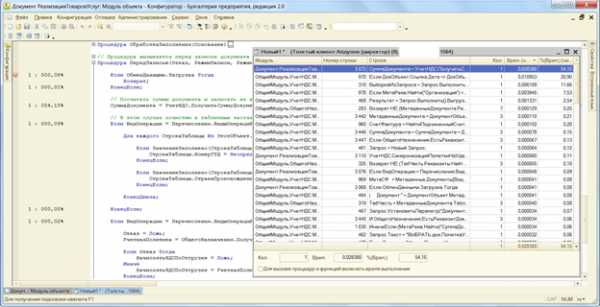
Продолжение оптимизации 1С — анализ участка кода 1С при помощи измерения времени выполнения
Результаты измерения времени в отладчике показывают:
- какие строчки кода выполнялись (как в этом модуле и этой функции, так и в других)
- сколько раз выполнялась одна и та же строчка кода (например в цикле)
- сколько времени было потрачено на ее выполнение.
Вы можете отсортировать строчки по времени выполнения или по количеству раз выполнения.
Ваша цель для оптимизации 1С:
- найти одну-три строчки, которые выполняются 20% от общего времени
- найти строчки, которые выполняются исключительно большое количество раз.
И наконец сама оптимизация 1С состоит в том, чтобы внести изменения в код так, чтобы время выполнения найденных строчек существенно уменьшилось.
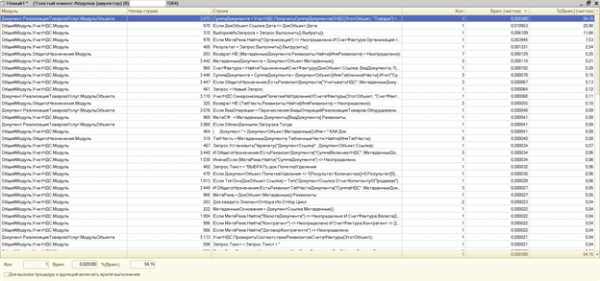
howknow1c.ru
Оптимизация 1С 8.3 (8.2) - повышение производительности базы
Оптимизация 1С — это ряд мер для увеличения производительности информационной системы. Рассмотрим основные шаги для анализа ошибок производительности и увеличения скорости 1С 8.3 (8.2).

Как оценить оптимизацию 1С?
Очень сложно оценивать производительность базы данных по ощущениям пользователей. Например, один пользователь говорит, что 1С «тормозит», второй говорит: «нормально» — ему нравятся перерывы на кофе. Эксперты в этой области стали искать выход из сложившейся ситуации — как объективно оценить качество эксплуатации информационной системы?
Для этого была придумана методика цифровой оценки скорости системы — APDEX. С помощью этой методики можно объективно оценить скорость до оптимизации 1С и после.
Проверка «железа»
Первым шагом на пути к оптимизации эксплуатации 1С является выявление узкого места в оборудовании. Очень часто, найдя загруженное место в оборудовании, можно быстро понять первопричину — ошибки в настройке сервера, недостаточная производительность аппаратной части или же ошибки в коде программы.
Однако если Вы думаете, что можно увеличить производительность 1С путем простого апгрейда оборудования, Вы глубоко заблуждаетесь. Существуют такие ошибки в настройке системы, которые будут «съедать» все ресурсы оборудования, несмотря ни на что.
Мониторинг и анализ производительности 1С специальным софтом — ЦУП
С помощью специальной разработки 1С — Центра управления производительностью для оптимизации 1С следует установить мониторинг на Вашу информационную систему.
Результатом проверки производительности станут узкие места 1С по части производительности, которые послужат указаниями к действиям по оптимизации 1С.
Действия по оптимизации базы 1С
Список действий для увеличения производительности системы 1С достаточно обширный: начиная от внесения изменений в код, устранения ошибок в запросах и оканчивая устранением аппаратных неполадок системы. Подробнее — цикл статей по оптимизации 1С.
Однако если Вы не располагаете временем для анализа и устранения ошибок, Вы можете заказать аудит проблем и их исправление у профессионала в области 1С.
programmist1s.ru
Оптимизация запросов в 1С - полная методика ускорения
Одним из важнейших пунктов в повышении производительности работы 1С 8.3 является оптимизация запросов. Этот пункт также очень важен при сдаче аттестации 1С Эксперт по технологическим вопросам. Ниже пойдет речь о типичных причинах неоптимальной работы запросов и способах их оптимизации.

Отборы в виртуальной таблице с помощью конструкции ГДЕ
Накладывать фильтры на реквизиты виртуальной таблицы необходимо только через параметры ВТ. Ни в коем случае для отбора в виртуальной таблице нельзя использовать конструкцию ГДЕ, это грубейшая ошибка с точки зрения оптимизации. В случае с отбором с помощью ГДЕ по факту система получит ВСЕ записи и только потом отберет нужные.
ПРАВИЛЬНО:
ВЫБРАТЬВзаиморасчетыСДепонентамиОрганизацийОстатки.СуммаОстатокИЗРегистрНакопления.ВзаиморасчетыСДепонентамиОрганизаций.Остатки(,Организация = &ОрганизацияИ Физлицо = &Физлицо) КАК ВзаиморасчетыСДепонентамиОрганизацийОстатки
НЕПРАВИЛЬНО:
ВЫБРАТЬВзаиморасчетыСДепонентамиОрганизацийОстатки.СуммаОстатокИЗРегистрНакопления.ВзаиморасчетыСДепонентамиОрганизаций.Остатки(, ) КАК ВзаиморасчетыСДепонентамиОрганизацийОстаткиГДЕВзаиморасчетыСДепонентамиОрганизацийОстатки.Организация = &ОрганизацияИ ВзаиморасчетыСДепонентамиОрганизацийОстатки.Физлицо = &Физлицо
Получение значения поля составного типа через точку
При получении данных составного типа в запросе через точку система соединяет левым соединением ровно столько таблиц, сколько типов возможно в поле составного типа.
Получите 267 видеоуроков по 1С бесплатно:
Например, крайне нежелательно для оптимизации обращаться к полю записи регистра — регистратор. Регистратор имеет составной тип данных, среди которых все возможные типы документов, которые могут писать данные в регистр.
НЕПРАВИЛЬНО:
ВЫБРАТЬНаборЗаписей.Регистратор.Дата,НаборЗаписей.КоличествоИЗРегистрНакопления.ТоварыOрганизаций КАК НаборЗаписей
Т.е. по факту вот такой запрос будет обращаться не к одной таблице, а к 22 таблицам базы данных ( у этого регистра 21 тип регистратора).
1С рекомендует экспертам в таком случае для оптимизации пожертвовать размером хранимых данных в пользу производительности или универсальностью кода ради производительности:
ПРАВИЛЬНО:
ВЫБРАТЬВЫБОРКОГДА ТоварыОрг.Регистратор ССЫЛКА Документ.РеализацияТоваровУслугТОГДА ВЫРАЗИТЬ(ТоварыОрг.Регистратор КАК Документ.РеализацияТоваровУслуг).ДатаКОГДА ТоварыОрг.Регистратор ССЫЛКА Документ.ПоступлениеТоваровУслугТОГДА ВЫРАЗИТЬ(ТоварыОрг.Регистратор КАК Документ.ПоступлениеТоваровУслуг).ДатаКОНЕЦ КАК Дата,ТоварыОрг.КоличествоИЗРегистрНакопления.ТоварыОрганизаций КАК ТоварыОрг
Либо второй вариант — добавление такой информации в реквизит, например, в нашем случае — добавление даты.
ПРАВИЛЬНО:
ВЫБРАТЬТоварыОрганизаций.Дата,ТоварыОрганизаций.КоличествоИЗРегистрНакопления.ТоварыОрганизаций КАК ТоварыОрганизаций
Подзапросы в условии соединения
Для оптимизации недопустимо использовать подзапросы в условиях соединения, это существенно замедляет работу запроса. Желательно в таких случаях использовать ВТ. Для соединения нужно использовать только объекты метаданных и ВТ, предварительно проиндексировав их по полям соединения.
НЕПРАВИЛЬНО:
ВЫБРАТЬ …ИЗ Документ.РеализацияТоваровУслугЛЕВОЕ СОЕДИНЕНИЕ (ВЫБРАТЬ ИЗ РегистрСведений.ЛимитыГДЕ …СГРУППИРОВАТЬ ПО …) ПО …
ПРАВИЛЬНО:
ВЫБРАТЬ …ПОМЕСТИТЬ ЛимитыИЗ РегистрСведений.ЛимитыГДЕ …СГРУППИРОВАТЬ ПО …ИНДЕКСИРОВАТЬ ПО …;
ВЫБРАТЬ …ИЗ Документ.РеализацияТоваровУслугЛЕВОЕ СОЕДИНЕНИЕ ЛимитыПО …;
Соединение записей с виртуальными таблицами
Бывают ситуации, когда при соединении виртуальной таблицы с другими система работает не оптимально. В таком случае эксперт для оптимизации работы запроса может попробовать поместить виртуальную таблицу во временную, не забыв проиндексировать соединяемые поля в запросе временной таблицы. Связано это с тем, что ВТ часто содержатся в нескольких физических таблицах СУБД, в итоге для их выборки составляется подзапрос, и проблема получается аналогичной предыдущему пункту.
Использование отборов по неиндексируемым полям
Одна из самых распространенных ошибок при составления запросов — использование условий по неиндексируемым полям, это противоречит правилам оптимизации запросов. СУБД не может выполнить запрос оптимально, если в запросе накладывается отбор по неиндексируемым полям. Если же берется временная таблица, также необходимо индексировать поля соединения.
Обязательно для каждого условия должен существовать подходящий индекс. Подходящим является индекс, отвечающий следующим требованиям:
- Индекс содержит все поля, перечисленные в условии.
- Эти поля находятся в самом начале индекса.
- Эти отборы идут подряд, то есть между ними не «вклиниваются» значения, не участвующие в условии запроса.
Если СУБД не подобрал правильные индексы, то будет просканирована таблица полностью. Это очень негативно скажется на производительности и может привести к продолжительной блокировке всего набора записей.
Использование логического ИЛИ в условиях
Настоятельно не рекомендуется злоупотреблять в условиях запросов конструкцией «ИЛИ».
Вот и всё, в данной статье были освещены основные аспекты оптимизации запросов, которые должен знать каждый эксперт 1С.
Отличное видео по разработке и оптимизации запросов 1С 8.3
К сожалению, мы физически не можем проконсультировать бесплатно всех желающих, но наша команда будет рада оказать услуги по внедрению и обслуживанию 1С. Более подробно о наших услугах можно узнать на странице Услуги 1С или просто позвоните по телефону +7 (499) 350 29 00. Мы работаем в Москве и области.
programmist1s.ru
1С 8.3 : Тормозит сервер 1С или компьютер с 1С
Очень часто ко мне обращаются с вопросами вида:
- из-за чего тормозит сервер 1С?
- компьютер с 1С работает очень медленно
- жутко тормозит клиент 1С
Что же делать и как это победить, и так по порядку:
Клиенты очень медленно работают с серверной версией 1С
Кроме медленной работы 1С, так же наблюдается медленная работа с сетевыми файлами. Проблема встречается при обычной работе и при RDP
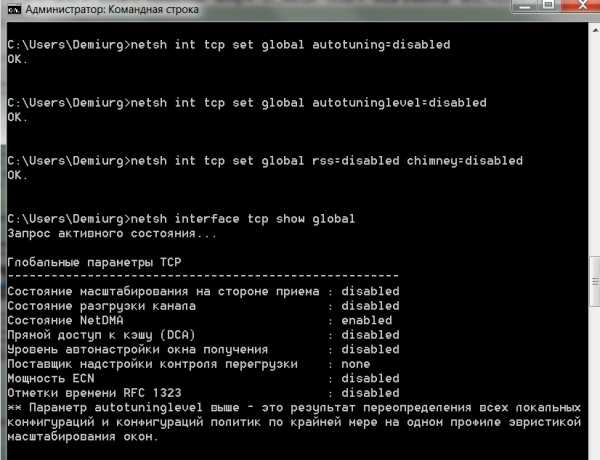
для решения этого, после каждой установки Семерки или 2008-го сервера всегда запускаю
netsh int tcp set global autotuning=disabled
netsh int tcp set global autotuninglevel=disabled
netsh int tcp set global rss=disabled chimney=disabled
и сеть работает без проблем
иногда оптимальным является:
netsh interface tcp set global autotuning= HighlyRestricted
вот как выглядит установка
Далее посмотрите настройки брандмауэра Windows
Настроить брандмауэр Антивируса или Windows
Как настроить брандмауэр Антивируса или Windows для работы сервера 1С (связка из Сервера 1С: Предприятие и MS SQL 2008, например).
Добавьте правила:
- Если сервер SQL принимает подключения на стандартный порт TCP 1433, то разрешаем его.
- Если порт SQL динамический, то необходимо разрешить подключения к приложению %ProgramFiles%\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\Binn\sqlservr.exe.
- Сервер 1С работает на портах 1541, кластер 1540 и диапазоне 1560-1591. По совершенно мистическим причинам иногда такой список открытых портов все равно не позволяет выполнять подключения к серверу. Чтобы заработало наверняка, разрешите диапазон 1540-1591.
Настройка производительности Сервера / Компьютера
Для того чтобы компьютер работал с максимальной производительностью - нужно настроить его на это:
1. Настройки BIOS
- В BIOS сервера отключаем все настройки по экономии электропитания процессора.
- Если есть «C1E» & обязательно ОТКЛЮЧАЕМ!!
- Для некоторых не очень параллельных задач также рекомендуется выключить гипертрейдинг в биосе
- В некоторых случаях (особенно для HP!) надо зайти в BIOS сервера, и ВЫКЛЮЧИТЬ там пункты, в названии которых есть EIST, Intel SpeedStep и C1E.
- Взамен надо там же найти пункты, связанные с процессором, в названии которых есть Turbo Boost, и ВКЛЮЧИТЬ их.
- Если в биосе есть общее указание режима энергосбережения & включить его в режим максимальной производительности (он ещё может называться «агрессивный»)
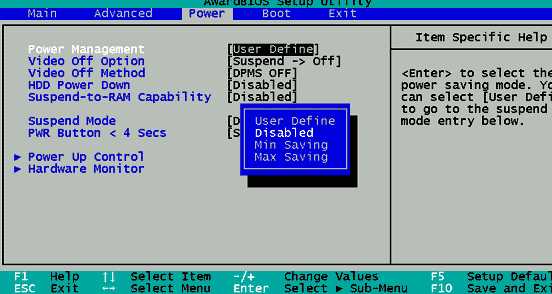
2. Настройки схемы в операционной системе - Высокая производительность
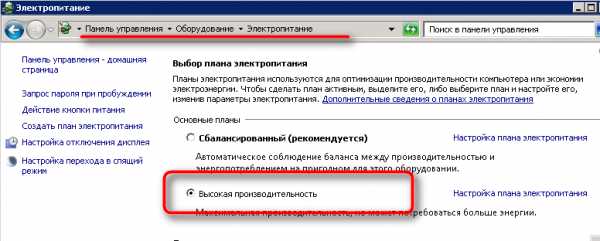
Сервера с архитектурой Intel Sandy Bridge умеют динамически менять частоты процессора.
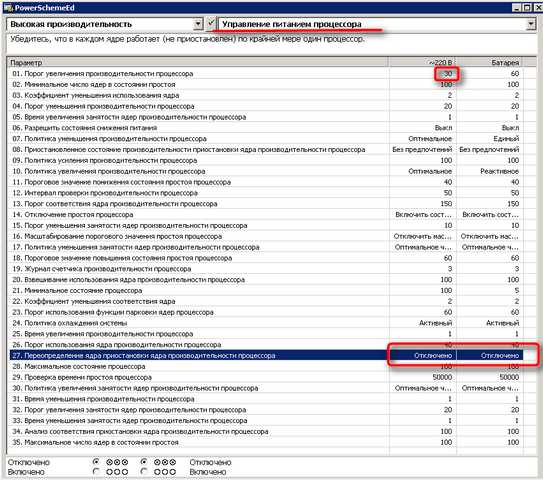
Скачайте утилиту PowerSchemeEd.7z , распакуйте с помощь 7zip и запустите PowerSchemeEd.exe
Выберите раздел Управление питанием процессора и выставите параметры 01. Порог при питании от сети 30% и отключите 27. Переопределение ядра... как на картинке.
3. На серверах 1С и MS SQL Server использование антивирусов (даже сам факт инсталяции без включения) будет приводить к снижению производительности в виде периодических массовых замедлений и подвисаний интерфейса.
4. Совмещение ролей сервера 1С и сервера MS SQL Server дает большую производительность, особенно если использовать протокол обмена данных напрямую через память «Shared Memory».
Очень многие не недооценивают важность настройки сервера, когда роли сервера 1С и сервера СУБД совмещены на одном физическом компьютере.
Убедиться, что к примеру используется протокол Shared Memory можно следующим образом:
Код SQL select program_name,net_transport from sys.dm_exec_sessions as t1 left join sys.dm_exec_connections AS t2 ON t1.session_id=t2.session_id where not t1.program_name is null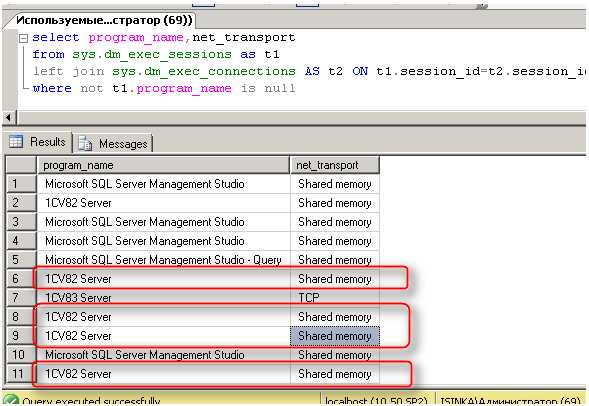
Обратите внимание, что в версиях платформы некоторые релизы «переключались» на протокол «именнованых каналов».
Для работы 1С Предприятие в режиме Shared Memory с SQL Server 2012 должен быть установлен NativeClient от SQL Server 2008 (backward compatibility connectivity components из дистрибутива SQL Server 2012 или отдельный пакет)
5. Отключение ненужных служб Виндовс
Одним из самых действенных способов ускорения компьютера является отключение неиспользуемых (ненужных) служб операционной системы. У ОС Windows по умолчанию включено огромное количество служб, на работу которых требуется большое количество ресурсов системы. Многие из них можно отключить без потери функциональности и снижения безопасности системы.
Какие службы можно отключить для оптимизации Windows:
- Авто настройка WWAN – в том случае, если у Вас нет CDMA или GSM модулей, эту службу можно безболезненно отключить
- Адаптивная регулировка яркости – эта служба регулирует яркость экрана при наличии датчика освещенности, если такой датчик отсутствует – отключаем.
- Брандмауэр Windows – предназначен для защиты компьютера. Рекомендуется пользоваться сторонними приложениями для этих целей (например, Comodo, KIS, DrWEB и т.п.).
- Защитник Windows – отключаем, совершенно ненужная служба!
- Служба помощника по совместимости программ (Program Compatibility Assistant) – эту службу можно отключить, только в случае несовместимости программ нужно будет вручную устанавливать параметры, что бывает не так уж часто.
- Служба автоматического обнаружения веб-прокси WinHTTP – можно отключать.
- Служба политики диагностики (Diagnostic Policy Service) – практически не нужна.
- Смарт-карта – если Вы не пользуетесь такими картами, то отключаем.
- Удаленный реестр (Remote Registry) – обязательно отключаем в целях безопасности.
- Центр обеспечения безопасности (Security Center) – напоминает о различных событиях вроде отсутствия антивируса, устаревших обновлениях и т.п. – отключаем, если не хотите их видеть.
Список, конечно, получился не особо емким, на самом деле служб, которые можно отключить, намного больше. Кроме того, среди стандартных служб появятся дополнительные службы сторонних программ, которые установлены на Вашем ПК, их также можно отключить.
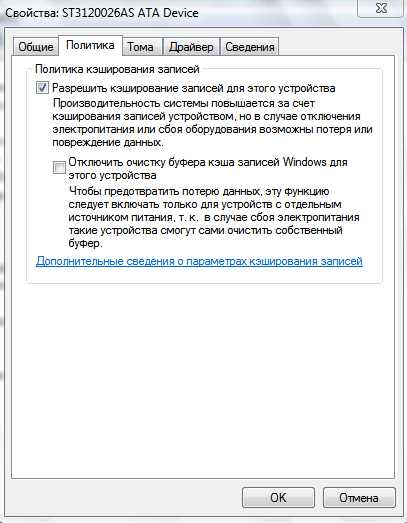
Кэширование записей на дисках в Windows
Кэшированием записей на устройстве хранения называется использование высокоскоростной энергозависимой памяти для накопления команд записи, отправляемых на устройства хранения данных, и их кэширования до тех пор, пока их не обработает более медленный носитель (либо физические диски, либо недорогая флэш-память). Для большинства устройств, использующих кэширование записей, требуется непрерывная подача электропитания.
Для управления кэшированием записей на диске откройте Панель управления - Диспетчер устройств.
В разделе Дисковые устройства дважды щелкните нужный диск.
Перейдите на вкладку Политики
В статье использован личный опыт и cайт Вячеслава Гилева
Буду рад конструктивным комментариям
helpf.pro
Блог предпринимателя. Философия предпринимателя по жизни — человека, который предпринимает.
 Надо сказать, при всей частоте возникновения вопроса «как ускорить работу 1С», мы с вами, всё же, имеем дело с одной из самых продуманных в этом плане платформ. Видал я творчество и на MS Access, и на самописных платформах, где слишком многое отдаётся на откуп разработчику и пришёл к выводу, что 1С:Предприятие, в плане оптимизации скорости предоставляет довольно разнообразные варианты.В прочем, обо всём по порядку. Далее, я поделюсь некоторым своим опытом в данном вопросе.
Надо сказать, при всей частоте возникновения вопроса «как ускорить работу 1С», мы с вами, всё же, имеем дело с одной из самых продуманных в этом плане платформ. Видал я творчество и на MS Access, и на самописных платформах, где слишком многое отдаётся на откуп разработчику и пришёл к выводу, что 1С:Предприятие, в плане оптимизации скорости предоставляет довольно разнообразные варианты.В прочем, обо всём по порядку. Далее, я поделюсь некоторым своим опытом в данном вопросе.
Почему тормозит 1С.
Что ж, у кого-то пользователи жалуются на медленное проведение какого-то часто используемого документа, иногда бывает, что медленно работают какие-то отдельные операции типа построения определённого отчёта или выполнения обмена данными. Где-то 1С «долго открывается», иногда долго обновляется. Проблемы могут быть постоянны или появляться с некоторой внезапностью.
В моей практике попадались разные причины недостаточной производительности 1С:Предприятие, и я могу выделить из них некоторые, не всегда очевидные, но достаточно частые.
- Локальная сеть. Самой частой причиной возникновения тормозов является появление второго, третьего и так далее пользователей, которые влекут за собой необходимость шаринга базы по сети. Есть уникальные сисадмины, которые прокидывают ЛВС через Wi-Fi для работы в 1С — при задержке доступа по Wi-Fi примерно в 10 раз больше, чем через проводную сеть, все обращения к базе замедляются в разы!
- Медленные диски. Система 1С:Предприятие, как и все СУБД, наиболее требовательна к дисковой подсистеме, чем программы другого назначения. Следовательно, организуя сервер для 1С:Предприятие нужно выбирать наиболее быструю и надёжную дисковую подсистему из доступных. Так же, по моим наблюдениям, HDD диски со временем начинают работать медленнее, возможно, вследствие износа магнитного слоя дисков. Это происходит примерно через 3-5 лет использования.
- Недостаток оперативной памяти. Вопрос, вроде бы, довольно легко диагностируется, и зачастую в первую очередь решается, но всё же о нём стоит упомянуть. Оперативная память решает. Если вам кажется, что надо её увеличить, то надо её увеличить. Более подробно о диагностике этого вопроса читайте ниже.
- Использование PostgreSQL на типовых настройках. Если вы имеете дело с клиент-серверным вариантом работы 1С:Предприятия, то, с большой вероятностью, вы используете PostgreSQL. Это очень популярная СУБД для такого режима работы платформы 1С, в виду того, что она бесплатная. Но, как и всё бесплатное, чтобы её правильно внедрить, надо немного поработать ручками и головой, в отличие от, может быть, той же Microsoft SQL Server. В последней танцев с бубном вокруг производительности, обычно, меньше. Ошибка заключается чаще всего в том, что установив PostgreSQL на сервер, специалист оставляет стандартный файл настроек postgresql.conf, который, как следует из документации, вообще не предназначен для постоянной работы и требует настройки под каждый конкретный сервер. Особенно, как я выяснил, это касается серверов на SSD-накопителях.
- Кривой код. Проблемы, которые таятся в неоптимальном использовании ресурсов, то же имеют место быть. Оптимизация запросов и программного кода таит в себе, зачастую, неограниченные возможности по ускорению работы в 1С.
Тестирование производительности сервера 1С.
Для диагностики производительности сервера обычно хватает штатных средств. Например, в Windows Server 2008 R2 есть замечательная кнопка «Монитор ресурсов» в диспетчере задач. С помощью монитора ресурсов можно достоверно произвести диагностику таких проблем как нехватка оперативной памяти или пропускной способности дисков.
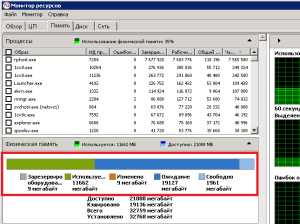 На странице «Память» можно оценить расход памяти теми или иными процессами, а так же наглядно оценить фактическую занятость оперативной памяти с помощью полоски внизу. Как вы заметите, помимо зелёной части полоски «Занято» есть не маловажная часть «Ожидание», которая отражает занятость памяти системным кешем. Наличие сектора «Свободно» означает, что памяти в данный момент хватает. Чем меньше памяти доступно для «Ожидания», тем меньше системный кэш, тем медленнее могут происходить некоторые операции. Тем не менее, я взял для себя ориентир, что примерно 30-40% памяти, находящийся в состоянии «Ожидание» и 60-70% в состоянии «Занято» это допустимый предел. Если памяти становится занято больше, то пора подумать либо об её очистке, либо об увеличении объёма памяти.
На странице «Память» можно оценить расход памяти теми или иными процессами, а так же наглядно оценить фактическую занятость оперативной памяти с помощью полоски внизу. Как вы заметите, помимо зелёной части полоски «Занято» есть не маловажная часть «Ожидание», которая отражает занятость памяти системным кешем. Наличие сектора «Свободно» означает, что памяти в данный момент хватает. Чем меньше памяти доступно для «Ожидания», тем меньше системный кэш, тем медленнее могут происходить некоторые операции. Тем не менее, я взял для себя ориентир, что примерно 30-40% памяти, находящийся в состоянии «Ожидание» и 60-70% в состоянии «Занято» это допустимый предел. Если памяти становится занято больше, то пора подумать либо об её очистке, либо об увеличении объёма памяти.
На странице «Диск» можно оценить загруженность дисковой подсистемы операциями ввода-вывода. В частности, если увидите, что очень много и часто происходит запись в файл «pagefile.sys», то это верный признак того, что памяти не хватает. Однако, надо иметь в виду, что как таковая активность на нём есть почти при любом количестве памяти из-за особенностей работы ОС. Но, пожалуй, главный показатель, который скажет вам о проблемах с дисковой системой, это 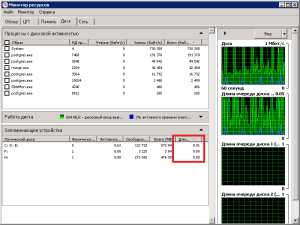 показатель «Длина очереди» в нижней части окна, где перечислены установленные диски. Если на одном из дисков этот показатель регулярно превышает значение 1, то это верный признак того, что этот диск не справляется с обработкой поступающих запросов. То есть, это говорит о том, что запросы отправляемые к диску чаще встают в очередь и ожидают завершения других запросов, чем обрабатываются сразу. В норме средняя очередь должна быть менее единицы, что говорит о том, что все операции чтения/записи отрабатываются вовремя, без ожидания других операций.
показатель «Длина очереди» в нижней части окна, где перечислены установленные диски. Если на одном из дисков этот показатель регулярно превышает значение 1, то это верный признак того, что этот диск не справляется с обработкой поступающих запросов. То есть, это говорит о том, что запросы отправляемые к диску чаще встают в очередь и ожидают завершения других запросов, чем обрабатываются сразу. В норме средняя очередь должна быть менее единицы, что говорит о том, что все операции чтения/записи отрабатываются вовремя, без ожидания других операций.
Это как в отделении СберБанка — если вы пришли, нажали кнопку на терминале и девушка, со странной интонацией в голосе, через громкоговоритель сразу пригласила вас к окну, то длина очереди оказалась меньше 1 и вы как-бы довольны. Если же вы приходите в своё отделение и регулярно ожидаете, когда обслужат бабулек перед вами, то длина очереди ожидания больше 1 и ваш запрос обрабатывается с задержкой.
Способы увеличения производительности работы с базой 1С.
Как это ни странно, но фирма «1С» буквально подарила нам (т. е. совсем бесплатно) предоставляет нам на платформе 8.3. простой клиент-серверный вариант работы, который способен основательно разгрузить локальную сеть, не прибегая к серьёзным затратам. Речь идёт о web-сервере.
Работа в режиме web-сервера, посредством тонкого клиента 1С:Предприятие позволяет перенести многие операции работы с данными действительно на сервер. В контексте сервера Apache или IIS запускается серверная часть 1С:Предприятие, которая обеспечивает доступ к файловой базе. Правда, в этом режиме, конечно же, не доступны разные плюшки, предоставляемые СУБД типа блокировок на уровне записей, кэширования, планирования запросов и т. п. но этот метод доступа сваливает различные операции прямого чтения данных на компьютер-сервер, за счёт чего значительно уменьшается сетевой трафик. Кроме этого, в режиме тонкого клиента, как я заметил, происходит оптимизация работы интерфейсных элементов, типа операций обновления списков, что позволяет так же разгрузить сеть. В случае необходимости, за счёт исчезновения некоторых приятных моментов типа подсказок при вводе, картинок и прочего, можно ещё больше улучшить отзывчивость клиентской части 1С — для этого надо включить галку «Низкая скорость соединения» при запуске базы 1С.
Как сделать публикацию базы 1С, настроить сервер и т. п. – тема выходящая за рамки статьи. Можете поискать информацию об этом сети. От себя скажу, что проще всего 1С взлетает на сервере Apache, но вот гнаться за последней его версией не стоит — смотрите информацию о совместимости на сайте 1С.
 Вернёмся к варианту работы с СУБД PostgreSQL. Так уж случилось, что те базы, которые сопровождает наша компания «крутятся» на SSD-дисках. Приход PostgreSQL зачастую был связан не столько с погоней за производительностью, сколько за вообще техническими ограничениями вроде допустимого размера таблиц базы данных.
Вернёмся к варианту работы с СУБД PostgreSQL. Так уж случилось, что те базы, которые сопровождает наша компания «крутятся» на SSD-дисках. Приход PostgreSQL зачастую был связан не столько с погоней за производительностью, сколько за вообще техническими ограничениями вроде допустимого размера таблиц базы данных.
После поднятия базы данных на Postgres, нужно обязательно покрутить настройки postgresql.conf. Какие-то достоверные рекомендации дать сложно, многое познаётся опытным путём, могу лишь описать некоторые настройки этого файла, которые давали какой-то, а иногда и очень ощутимый прирост производительности (или его падение).
Хороший прирост дало изменение параметра wal_sync_method: wal_sync_method = open_datasync. Этот параметр задаёт метод работы с файловой системой. В значении open_datasync под Windows появилось некоторое ускорение работы.
Стоит подобрать оптимальное значение для checkpoint_segments. Этот параметр задаёт частоту полной синхронизации страниц памяти с базой на накопителе. Слишком мало — даст частую запись, слишком много — в случае сбоя может не сохранить часть данных. По крайней мере, так я понял работу этого параметра.. При проблемах с долгим проведением закрытия месяца в Бухгалтерии предприятия 3.0, я проверил варианты от 3 (по умолчанию) до 96 , и где -то от 32 разницы не было. Оставил 64 с некоторым запасом, т.к. при работе всех пользователей, этот параметр мог бы потребовать изменений:
checkpoint_segments = 64
Однако, наибольший эффект в этих экспериментах дали параметры из раздела Planner Cost Constants. С их помощью удалось добиться почти трёхкратного роста производительности.
Параметры seq_page_cost и random_page_cost задают абстрактную цену соответственно последовательного и случайного доступа к страницам базы данных на накопителе. Стоит обратить внимание, что на SSD накопителях эти параметры имеют меньшую разницу, чем на HDD, т.к на SSD случайная выборка данных занимает почти столько же времени, как и последовательная. А вот на HDD накопителе цена случайного доступа к данным (random_page_cost) гораздо больше, чем последовательного. Подробнее о параметре random_page_cost можно прочитать тут (на английском, так что Google-переводчик в помощь).
Две последних настройки нужно рассматривать в совокупности с параметрами cpu_tuple_cost, cpu_index_tuple_cost и cpu_operator_cost. Они задают цену операций процессора, когда оптимизатору предстоит решить выбирать ли нагрузку на процессор, или же предпочесть нагрузку на диск в некоторых операциях.
У меня по по разделу «Planner Cost Constraints» получился такой «прайс-лист»:
seq_page_cost = 1random_page_cost = 1.5cpu_tuple_cost = 0.001cpu_index_tuple_cost = 0.0005cpu_operator_cost = 0.00025
Рекомендую, так же, почитать про параметры работы с памятью effective_cache_size, shared_buffers, work_mem и поэкспериментировать с ними. На больших выборках данных и при большом количестве пользователей их неправильная настройка должна привести к плохим результатам. А правильная — к хорошим.
Интересный случай настройки PosgreSQL произошёл при поднятии на нём одной из старых релизов Управление торговлей 10.3. Путём временного отключения параметра enable_nestloop, удалось улучшить выполнение некоторых сложных запросов. Совсем отключать этот параметр не рекомендуется, т. к. в более простых запросах операции соединения таблиц могут наоборот выполняться медленнее. Что интересно, включив его через некоторое время, случилось чудо — производительность осталась на том же уровне. Я это связываю с тем, что планировщику пришлось использовать другие методы соединения таблиц и накопить по ним статистику. В результате, после возвращения настроек, планировщик уже «знал что делать» с теми проблемными запросами, погоняв их другими методами, вроде indexscan или bitmapscan, и больше не использовал на них метод nestloop.
На любом варианте работы с базой данных — будь то web-сервер, СУБД или файловый вариант, я очень рекомендую перебороть в себе консерватизм и страх перед… в общем-то, уже не такой уж и новизной. Простая замена ваших HDD, на SSD-накопители закроет большинство ваших проблем. Правда, не стоит рассчитывать, что при прямом доступе к файловой базе данных по локальной сети это даст какой-то серьёзный эффект. Если только ваши HDD не на столько медленные, что даже задержка запросов по сети отрабатывает быстрее… Что вряд ли.
Для пущей уверенности, настройте регулярное копирование базы данных средствами Windows с твердотельника на жёсткий диск. Благо, встроенная система архивации данных Windows позволяет быстро делать инкрементальные архивы внутри одной машины. Это должно немного расслабить вас в отношении «небольшого ресурса» SSD-накопителей. А так же, при наличии бюджета, настройте массив RAID1 для зеркальной записи на SSD, на случай чего. Комбинация двух этих методов должна снять с вас всё бремя ответственности за внедрение продвинутых технологий, которые ещё не обкатаны десятилетиями…
 Не стоит забывать (а вы о нём наверняка помните) о таком устаревающем методе, как установка терминал-серверной ОС и запуск работы в терминальном режиме. Способ, в общем-то очевиден, по этому на нём останавливаться не буду. Стоит сказать, что при всей своей кажущейся простоте он не является панацеей, довольно сложен и дорог. Но, тем не менее, терминалка находится в топе способов оптимизации производительности. Хотя, как мне кажется, эта штука устаревает с развитием интернета, сетей и технологий доступа к данным, с годами отходя на второй план, оставаясь лишь у консервативно настроенных сисадминов.
Не стоит забывать (а вы о нём наверняка помните) о таком устаревающем методе, как установка терминал-серверной ОС и запуск работы в терминальном режиме. Способ, в общем-то очевиден, по этому на нём останавливаться не буду. Стоит сказать, что при всей своей кажущейся простоте он не является панацеей, довольно сложен и дорог. Но, тем не менее, терминалка находится в топе способов оптимизации производительности. Хотя, как мне кажется, эта штука устаревает с развитием интернета, сетей и технологий доступа к данным, с годами отходя на второй план, оставаясь лишь у консервативно настроенных сисадминов.
Некоторые вопросы оптимизации кода и запросов в 1С.
Все описанные выше способы хороши, но криво написанный код, отчёт или запрос, который выбирает избыточное количество данных, да ещё и которые потом блокируются для записи могут свести на нет все ваши попытки улучшить положение.
Например, в упоминавшейся выше УТ 10.3 на критичном участке — загрузка данных в оффлайн-ККМ проходила очень медленно, — история кончилась лишь тогда, когда были переписаны несколько процедур. В частности, ранее неплохо работавшая в файловом режиме обработка, создавала множественные обращения к базе данных, для получения значения «Уровень()» у элемента справочника. Однако, при переводе в клиент-сервер этот метод, выполнявшийся десятки тысяч раз за один запуск обработки, создавал наибольшую загруженность. Пришлось отдельной процедуркой пройти все группы справочника, которые обычно составляют 1-5% от всего количества элементов, сложить эти группы в таблицу значений и рассчитать для них уровень заблаговременно. За тем, вместо метода «Уровень()» был сделан поиск по этой таблице значений как по кэшу, что ускорило работу обработки с 40 минут до 4-х, т.е. в 10 раз.
Подобные неявные обращения к базе данных возможны при обращении к свойствам ссылок или при получении представления объектов — нужно иметь это ввиду. Если вам нужно вывести представление объекта, получите в запросе заблаговременно функцией ПРЕДСТАВЛЕНИЕССЫЛКИ(). Если вам нужно обратиться к свойству ПометкаУдаления элемента справочника во время обхода запроса, получите его в запросе, а не обращайтесь к нему через Ссылка.ПометкаУдаления. А ещё лучше, сразу в запросе ограничьте выборку элементов, например «ГДЕ НЕ Номенклатура.ПометкаУдаления». Но, в общем, во мне сейчас говорит Капитан Очевидность, он же напоминает вам и про параметры виртуальных таблиц, которые иногда не используют новички, в которых тоже можно сразу ограничить выборку данных. Принцип Бритвы Оккама «Не стоит творить сущности без необходимости» — один из главных методов написания оптимального кода. Нужно на максимально ранних этапах отрезать ненужные данные.
Встроенный замер производительности в Конфигураторе вам в помощь. В нём вы сможете отследить подобные неочевидные ошибки.
А вот менее бросается в глаза такой метод, как использование индексов во временных таблицах запроса. Вообще, времена вложенных запросов давно прошли, и практически все таблицы, которые выбираются как вложенный запрос имеет смысл выносить во временную таблицу. А эти временные таблицы, если по их полям происходят соединения, сортировки или отборы имеет смысл индексировать.
Например:
ВЫБРАТЬНоменклатураБезПометок.Наименование,Остатки.ОстатокИЗ(Выбрать Номенклатура.Ссылка ИЗ Номенклатура ГДЕ НЕ Номенклатура.Пометка) Как НоменклатураБезПометокЛЕВОЕСОЕДИНЕНИЕРегистрыНакопления.Остатки(&КонецПериода) Как ОстаткиПО Остатки.Номенклатура = НоменклатураБезПометок.Ссылка
Быстрее будет работать так (добавляем индекс и временную таблицу):
ВЫБРАТЬНоменклатура.Наименование,Номенклатура.СсылкаПОМЕСТИТЬ втНоменклатураБезПометокИНДЕКСИРОВАТЬ ПО Номенклатура.Ссылка;ВЫБРАТЬНоменклатураБезПометок.Наименование,Остатки.ОстатокИЗвтНоменклатураБезПометок Как НоменклатураБезПометокЛЕВОЕСОЕДИНЕНИЕРегистрыНакопления.Остатки(&КонецПериода) Как ОстаткиПО Остатки.Номенклатура = НоменклатураБезПометок.Ссылка
А ещё быстрее — так (сразу убираем лишнее на этапе выборки остатков):
ВЫБРАТЬОстатки.Номенклатура.Наименование КАК Наименование,Остатки.ОстатокИЗРегистрыНакопления.Остатки(&КонецПериода, НЕ Номенклатура.Пометка) Как Остатки
Однако, стоит без фанатизма относиться к индексам. Во-первых, построение индекса занимает время — на запросах с маленьким количеством записей построение индекса может свести на нет выигрыш от выполнения запроса. Во-вторых, индексы строятся в оперативной памяти вашего сервера, что тоже надо иметь в виду. Но всё же, на больших выборках данных, обрабатываемых в запросе, индексы могут стать спасением.
Надеюсь, что эта статья навела вас на идеи о том, как решить проблемы со скоростью доступа к базе 1С. Если вам понравилась статья, поделитесь ею на своей странице в ВКонтакте или расскажите о ней в своём блоге или на форуме.
Напоследок, почитайте нашу статью о том, как защитить ваши базы от вирусов-шифровальщиков или о том как второй монитор может облегчить вашу трудовую жизнь.
delprog.ru