1С 8.3 : Ускорение и оптимизация настроек PostgreSQL для 1С. Postgresql 1с оптимизация
Как ускорить 1С или правильная настройка PostgreSQL для 1С

Как ускорить 1С, наверное, такой вопрос рано или поздно приходит в голову каждого кто работает с данным продуктом. В этой статье хочу поделиться своим опытом в настройке PostgreSQL для 1С и как его ускорить 1С 8.3 + PostgreSQL если данная связка начала медленно работать.
Как вы уже поняли речь, пойдет о тюнинге 1С в клиент-серверном варианте. Выбор в пользу именно такого варианта был сделан т.к. количество пользователей, работающих с 1С небольшое и использование платного MS SQL было бы просто экономически не целесообразно, а настройка PostgreSQL довольна проста и возможна практически из коробки.
Если у вас проблема с медленной работой 1С, то на 99% это проблема не с самой 1С, а это проблема в не правильной настройке СУБД, вот собственно о б этом и пойдет речь, как правильно настроить СУБД PostgreSQL для быстрой работы 1С.
И так начнем для настройки PostgreSQL мы будем использовать pgAdmin на мой взгляд он очень удобен в настройке. Для начала сделаем копии конфигурационных файлов Postgresql.conf и pg_hba.conf они находиться:
C:\Program Files\PostgreSQL\9.2.х-1.1C\data
Это поможет вам быстро вернуть все в рабочее состояние если в друг что-то пойдёт не так.
postgresql.conf – это файл конфигурации СУБД PostgreSQL который мы в основном и будим править.
pg_hba.conf – это файл настройки доступа к СУБД, данный файл если вы в нем не чего не меняли по умолчанию правильный, но в нем можно допивать дополнительные настройки доступности.
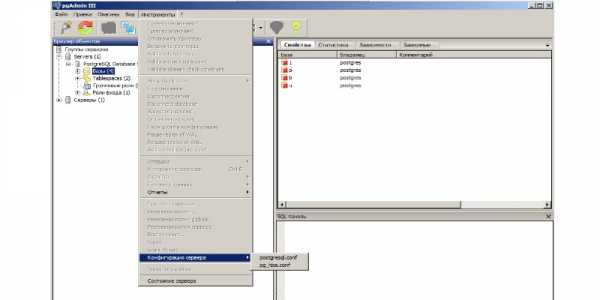
Отрываем настройки конфигурации (Postgresql.conf ) и там нам интересны следующие параметры:
shared_buffers – этот параметр определяет количество совместного кэша страниц СУБД. Рассчитывается примерно, делим всю доступную память на 4.
effective_cache_size – это параметр отвечает за оценку размера кэша файловой системы. Рассчитывается 32гб – shared_buffers = effective_cache_size.
temp_buffers – Этот параметр размера буфера для временных страниц, я оставляю по умолчанию равное 256 мб.
bgwrite_delay – время пропусков между циклами фоновой записи на диск. Процесс отвечает за синхронизацию страниц, большое значение этого параметра приведет к возрастанию нагрузки, а маленькое приведет к полной загрузке одного из ядер.
synchronous_commit = off — данный параметр ВЫКлючает синхронизацию с диском. Данный параметр дает значительный прирост в производительности.
autovacuum = on – это сбор мусора, также обязательно рекомендую включать настройки автовакума они тоже значительно помогут ускроить работу вашей 1С.
autovacuum_max_workers = 5 – максимальное количество параллельно запущенных процессов уборки.
autovacuum_naptime = 20s – минимальный интервал, реже которого autovacuum не будет запускаться.
После чего применяем настройки и перезагружаем конфигурацию сервера СУБД.
Но вот думаю эти настройки уже позволят вам значительно ускорить работу 1С. Для более тонкой настройки работы связки PostgreSQL и 1С нужен более полный анализ и возможно модернизация сервера.
Установка и настройка PostgreSQL для 1С:Предприятие
Установка PostgreSQL 9.6
Устанавливать будем сборку от компании Postgres Professional. На странице с версией для 1С:Предприятие найдем информацию об установке на CentOS 7 свежей версии PostgreSQL.
Подключим репозитории и установим PostgreSQL 9.6:
sudo rpm -ivh http://1c.postgrespro.ru/keys/postgrespro-1c-centos96.noarch.rpm sudo yum makecache sudo yum install postgresql-pro-1c-9.6Базовая настройка PostgreSQL
Инициализируем служебные базы данных с русской локализацией:
su postgres /usr/pgsql-9.6/bin/initdb -D /var/lib/pgsql/9.6/data --locale=ru_RU.UTF-8 exit service postgresql-9.6 initdbЗапускаем службу PostgreSQL и добавляем его в автозагрузку:
systemctl enable postgresql-9.6 systemctl start postgresql-9.6 systemctl status postgresql-9.6Задаем пароль пользователю postgres, для того чтобы была возможность подключаться к серверу удаленно:
su - postgres psql ALTER USER postgres WITH ENCRYPTED PASSWORD 'yourpassword'; \q exitДля возможности пользователю postgres авторизовываться по паролю отредактируем файл pg_hba.conf:
в открывшемся файле раскомментируем и изменим строки:
host all all 127.0.0.1/32 ident на host all all 127.0.0.1/32 md5
host all all 0.0.0.0/0 ident на host all all 0.0.0.0/0 md5
Оптимизация настроек PostgreSQL (postgresql.conf) для 1С:Предприятие
Здесь будут настройки для PostgreSQL, работающей в виртуальной машине ESXi 6.5.
Ресурсы выделенные для ВМ:
процессор — 8 vCPU;
память — 48 GB;
диск для ОС — 50 GB на LUN аппаратном RAID1 из SAS HDD;
диск для БД — 170 GB на программном RAID1 из SSD
диск для логов — 100 GB на программном RAID1 из SSD
Для редактирования настроек выполним команду:
mcedit /var/lib/pgsql/9.6/data/postgresql.confЗакомментированные параметры, которые будем изменять необходимо активировать.
Процессор
autovacuum_max_workers = 4
autovacuum_max_workers = NCores/4..2 но не меньше 4
Количество процессов автовакуума. Общее правило — чем больше write-запросов, тем больше процессов. На read-only базе данных достаточно одного процесса.
ssl = off
Выключение шифрования. Для защищенных ЦОД’ов шифрование бессмысленно, но приводит к увеличению загрузки CPU
Память
shared_buffers = 12GB
shared_buffers = RAM/4
Количество памяти, выделенной PgSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PgSQL. Операционная система сама кеширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память.
temp_buffers = 256MB
Максимальное количество страниц для временных таблиц. Т.е. это верхний лимит размера временных таблиц в каждой сессии.
work_mem = 64MB
work_mem = RAM/32..64 или 32MB..128MB
Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребная память равна max_connections * work_mem, на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании. Это рекомендательное значение используется оптимайзером: он пытается предугадать размер необходимой памяти для запроса, и, если это значение больше work_mem, то указывает экзекьютору сразу создать временную таблицу. work_mem не является в полном смысле лимитом: оптимайзер может и промахнуться, и запрос займёт больше памяти, возможно в разы. Это значение можно уменьшать, следя за количеством создаваемых временных файлов:
maintenance_work_mem = 2GB
maintenance_work_mem = RAM/16..32 или work_mem * 4 или 256MB..4GB
Лимит памяти для обслуживающих задач, например по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и добавления внешних ключей. Размер выделяемой под эти операции памяти должен быть сравним с физическим размером самого большого индекса на диске.
effective_cache_size = 36GB
effective_cache_size = RAM — shared_buffers
Оценка размера кеша файловой системы. Увеличение параметра увеличивает склонность системы выбирать IndexScan планы. И это хорошо.
Диски
effective_io_concurrency = 5
Оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Для одиночного диска = 1, для RAID — 2 или больше.
random_page_cost = 1.3
random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для SSD
Стоимость чтения рандомной страницы (по-умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PgSQL к выбору планов с сканированием всей таблицы (PgSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). И это плохо.
autovacuum = on
Включение автовакуума.
autovacuum_naptime = 20s
Время сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать вакуумиться и, как следствие, вырастет bloat и размер таблиц и индексов. Малая величина приведет к бесполезному нагреванию.
bgwriter_delay = 20ms
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0
bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чем bgwriter_lru_maxpages.
synchronous_commit = off
Выключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. Но значительно увеличивает производительность.
wal_keep_segments = 256
wal_keep_segments = 32..256
Максимальное количество сегментов WAL между checkpoint. Слишком частые checkpoint приводят к значительной нагрузке на дисковую подсистему по записи. Каждый сегмент имеет размер 16MB
wal_buffers = 16MB
Объём разделяемой памяти, который будет использоваться для буферизации данных WAL, ещё не записанных на диск. Значение по умолчанию, равное -1, задаёт размер, равный 1/32 (около 3%) от shared_buffers, но не меньше, чем 64 КБ и не больше, чем размер одного сегмента WAL (обычно 16 МБ). Это значение можно задать вручную, если выбираемое автоматически слишком мало или велико, но при этом любое положительное число меньше 32 КБ будет восприниматься как 32 КБ. Этот параметр можно задать только при запуске сервера.
Содержимое буферов WAL записывается на диск при фиксировании каждой транзакции, так что очень большие значения вряд ли принесут значительную пользу. Однако значение как минимум в несколько мегабайт может увеличить быстродействие при записи на нагруженном сервере, когда сразу множество клиентов фиксируют транзакции. Автонастройка, действующая при значении по умолчанию (-1), в большинстве случаев выбирает разумные значения.
default_statistics_target = 1000
Устанавливает целевое ограничение статистики по умолчанию, распространяющееся на столбцы, для которых командой ALTER TABLE SET STATISTICS не заданы отдельные ограничения. Чем больше установленное значение, тем больше времени требуется для выполнения ANALYZE, но тем выше может быть качество оценок планировщика. Значение этого параметра по умолчанию — 100.
checkpoint_completion_target = 0.9
Степень «размазывания» checkpoint’a. Скорость записи во время checkpoint’а регулируется так, что бы время checkpoint’а было равно времени, прошедшему с прошлого, умноженному на checkpoint_completion_target.
min_wal_size = 4G max_wal_size = 8G
min_wal_size = 512MB .. 4Gmax_wal_size = 2 * min_wal_size
Минимальное и максимальный объем WAL файлов. Аналогично checkpoint_segments
fsync = on
Выключение параметра приводит к росту производительности, но появляется значительный риск потери всех данных при внезапном выключении питания. Внимание: если RAID имеет кеш и находиться в режиме write-back, проверьте наличие и функциональность батарейки кеша RAID контроллера! Иначе данные записанные в кеш RAID могут быть потеряны при выключении питания, и, как следствие, PgSQL не гарантирует целостность данных.
row_security = off
Отключение контроля разрешения уровня записи
enable_nestloop = off
Включает или отключает использование планировщиком планов соединения с вложенными циклами. Полностью исключить вложенные циклы невозможно, но при выключении этого параметра планировщик не будет использовать данный метод, если можно применить другие. По умолчанию этот параметр имеет значение on.
Блокировки
max_locks_per_transaction = 256
Максимальное число блокировок индексов/таблиц в одной транзакции
Настройки под платформу 1С
standard_conforming_strings = off
Разрешить использовать символ \ для экранирования
escape_string_warning = off
Не выдавать предупреждение о использовании символа \ для экранирования
Настройка безопасности
Сделаем так, чтобы сервер PostgreSQL был виден только для сервера 1С: Предприятие, установленного на этой же машине.
listen_addresses = ‘localhost’
Если сервер 1С: Предприятие установлен на другой машине или существует необходимость подключиться подключиться к серверу СУБД с помощью оснастки PGAdmin, то вместо localhost нужно указать адрес этой машины.
Хранение базы данных
PostgreSQL как и почти любая СУБД критична к дисковой подсистеме, поэтому для повышения быстродействия СУБД разместим систему PostgreSQL, логи и сами базы на разные диски.
Останавливаем сервер
systemctl stop postgresql-9.6Переносим логи на созданный RAID1 из 120GB SSD:
mv /var/lib/pgsql/9.6/data/pg_xlog /raid120 mv /var/lib/pgsql/9.6/data/pg_clog /raid120 mv /var/lib/pgsql/9.6/data/pg_log /raid120Создаем символьные ссылки:
ln -s /raid120/pg_xlog /var/lib/pgsql/9.6/data/pg_xlog ln -s /raid120/pg_clog /var/lib/pgsql/9.6/data/pg_clog ln -s /raid120/pg_log /var/lib/pgsql/9.6/data/pg_logТак же перенесем каталог с базами:
mv /var/lib/pgsql/9.6/data/base /raid200и создадим символьную ссылку:
ln -s /raid200/base /var/lib/pgsql/9.6/data/baseзапустим сервер и проверим его статус
systemctl start postgresql-9.6 systemctl status postgresql-9.6
Поделиться ссылкой:
Похожее
kazhaev.ru
postgresql | Gilev.ru | Ускоряем 1С:Предприятие
При работе с СУБД PostgreSQL и IBM DB2 ускорено удаление записей о фактическом периоде действия регистра расчета при удалении больших наборов записей.
Реализована поддержка СУБД Oracle Database версии 12.1.0.2 (Linux)
Доступно клиентское приложение, работающее под OS X 10.8 и старше (только в варианте 64-разрядного приложения)
Реализована поддержка дистрибутива Astra Linux Special Edition 1.4
Оптимизирована работа полнотекстового поиска и построение индекса полнотекстового поиска. Реализовано событие технологического журнала <INPUTBYSTRING> для отслеживания событий, связанных с вводом по строке.
При выполнении запроса, обращающегося только к данным табличных частей, исключено соединение с таблицей родительского объекта.Оптимизировано чтение из СУБД объектов типа ДокументОбъект, СправочникОбъект, БизнесПроцессОбъект, ЗадачаОбъект, ПланВидовРасчетаОбъект, ПланВидовХарактеристикОбъект, ПланОбменаОбъект, ПланСчетовОбъект — чтение сопровождается неявным созданием транзакции только при наличии у объекта табличных частей и если СУБД используется «грязное» чтение вне транзакции.
Оптимизирована работа с условным оформлением в управляемой форме. Ускорено открытие управляемой формы с большим количеством элементов условного оформления.
Ускорена работа конфигураций (включая открытие форм) с большим количеством ролей.
В языке запросов реализована оптимизация выражений, содержащих операции сравнения, в которых участвует константное значение и операция ВЫБОР, которая в качестве результата может принимать только константные значения. В результате оптимизации выражение или его часть может быть упрощено.
Программные лицензии. Начиная с версии 8.3.7.1949 изменение нумерации сетевых адаптеров не будет приводить к нарушению привязки лицензии (если не поменялись другие параметры). Это актуально для работы в виртуальных средах.
Реализовано событие технологического журнала <CONFLOADFROMFILES>.
Реализовано событие технологического журнала <INPUTBYSTRING> для отслеживания событий, связанных с вводом по строке.
Реализовано журналирование исключительных ситуаций, возникающих в процессе работы отладчика, в технологическом журнале. Журналирование выполняется с помощью события <EXCP>.
Во релизе 8.3.7 есть проблема подключения к кластеру после перезапуска рабочего процесса — обходится отключением перезапуска процессов. Заявляется исправление в 8.3.7.1949В версии 8.3.7 выключенный процесс будет продолжать обслуживать вызовы, пока не перезапустится. Не устанавливайте слишком большое время завершения выключенных процессов.
В 8.3.7 могут быть избыточные блокировки на константах и регламентах.
Подробнее описание тут
www.gilev.ru
1С 8.3 : Ускорение и оптимизация настроек PostgreSQL для 1С » Администрирование » FAQ 1С 8.3 : » HelpF.pro
По умолчанию PostgreSQL настроен таким образом, чтобы расходовать минимальное количество ресурсов для работы с небольшими базами до 4 Gb на не очень производительных серверах. То есть, если дело касается систем посерьезней, то вы столкнетесь с большими потерями производительности базы данных лишь потому, что дефолтные настройки могут в корне не соответствовать производительности вашего северного оборудования. Настройки выделения ресурсов оперативной памяти RAM для работы PostgreSQL хранятся в файле postgresql.conf.
Доступен как из папки, куда установлен PostgreSQL / Data, так и из pgAdmin:
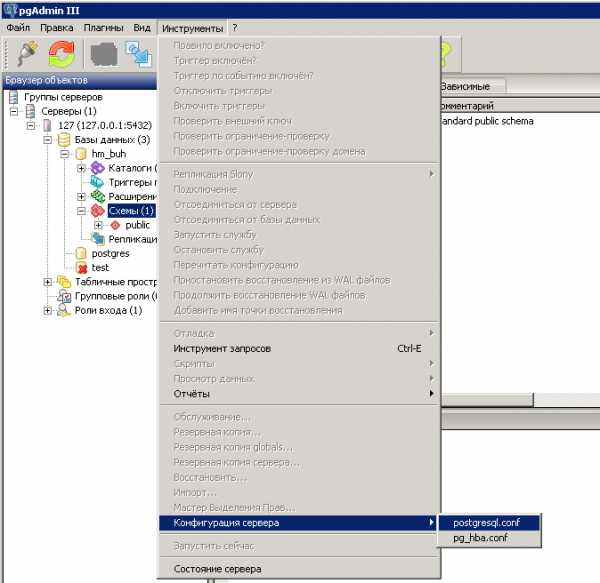
В общем на начальном этапе при возникновении трудностей и замедления работы БД, заметной для глаз пользователей достаточно увеличить три параметра:
shared_buffers
Это размер памяти, разделяемой между процессами PostgreSQL, отвечающими за выполнения активных операций. Максимально-допустимое значение этого параметра – 25% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 64-128 Mb (8192-16384).
temp_buffers
Это размер буфера под временные объекты (временные таблицы). Среднее значение 2-4% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 32-64 Mb.
work_mem
Это размер памяти, используемый для сортировки и кэширования таблиц.
При 1-2 Gb RAM на сервере, рекомендуемое значение 32-64 Mb.
Для вступления новых значений в силу, потребуется перезапуск службы, поэтому лучше делать во вне рабочее время.
Еще два важных параметра это maintenance_work_mem (для операций VACUUM, CREATE INDEX и других) и max_stack_depth
Примеры оптимальных настроек:
Hardware:
- CPU: E3-1240 v3 @ 3.40GHz
- RAM: 32Gb 1600Mhz
- Диски: Plextor M6Pro
postgresql.conf:
- shared_buffers = 8GB
- work_mem = 128MB
- maintenance_work_mem = 2GB
- fsync = on
- synchronous_commit = off
- wal_sync_method = fdatasync
- checkpoint_segments = 64
- seq_page_cost = 1.0
- random_page_cost = 6.0
- cpu_tuple_cost = 0.01
- cpu_index_tuple_cost = 0.0005
- cpu_operator_cost = 0.0025
- effective_cache_size = 24GB
Вариант настроек от pgtune:
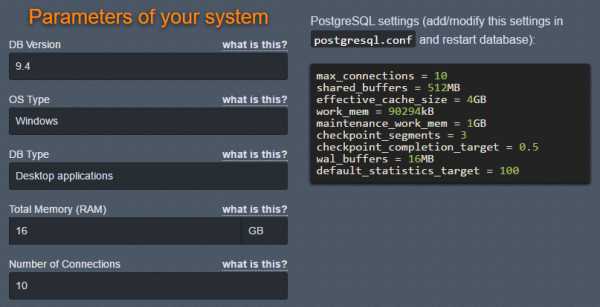
Полезные запросы:
Блокировки БД по пользователям
Код SQL select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename;Вывести все таблицы, размером больше 10 Мб
Код SQL SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size from pg_tables where tableName not like ‘sql_%’ and pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) like ‘%MB%’;Определение размеров таблиц в базе данных PostgreSQL
Код SQL SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size from pg_tables where tableName not like ‘sql_%’ order by size;Пользователи блокирующие конкретную таблицу
Код SQL select a.usename, t.relname, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid inner join pg_stat_all_tables t on t.relid=l.relation where t.relname = ‘tablename’; Код SQL select relation::regclass, mode, a.usename, granted, pid from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not mode = ‘AccessShareLock’ and relation is not null;Запросы с эксклюзивными блокировками
Код SQL select a.usename, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where mode ilike ‘%exclusive%’;Количество блокировок по пользователям
Код SQL select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename;Количество подключений по пользователям
Код SQL select count(usename), usename from pg_stat_activity group by usename order by count(usename) desc;helpf.pro
1С 8.2 УП : Ускорение и оптимизация настроек PostgreSQL для 1С » Администрирование » FAQ 1С 8.2 УП : » HelpF.pro
По умолчанию PostgreSQL настроен таким образом, чтобы расходовать минимальное количество ресурсов для работы с небольшими базами до 4 Gb на не очень производительных серверах. То есть, если дело касается систем посерьезней, то вы столкнетесь с большими потерями производительности базы данных лишь потому, что дефолтные настройки могут в корне не соответствовать производительности вашего северного оборудования. Настройки выделения ресурсов оперативной памяти RAM для работы PostgreSQL хранятся в файле postgresql.conf.
Доступен как из папки, куда установлен PostgreSQL / Data, так и из pgAdmin:
В общем на начальном этапе при возникновении трудностей и замедления работы БД, заметной для глаз пользователей достаточно увеличить три параметра:
shared_buffers
Это размер памяти, разделяемой между процессами PostgreSQL, отвечающими за выполнения активных операций. Максимально-допустимое значение этого параметра – 25% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 64-128 Mb (8192-16384).
temp_buffers
Это размер буфера под временные объекты (временные таблицы). Среднее значение 2-4% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 32-64 Mb.
work_mem
Это размер памяти, используемый для сортировки и кэширования таблиц.
При 1-2 Gb RAM на сервере, рекомендуемое значение 32-64 Mb.
Для вступления новых значений в силу, потребуется перезапуск службы, поэтому лучше делать во вне рабочее время.
Еще два важных параметра это maintenance_work_mem (для операций VACUUM, CREATE INDEX и других) и max_stack_depth
Примеры оптимальных настроек:
Hardware:
- CPU: E3-1240 v3 @ 3.40GHz
- RAM: 32Gb 1600Mhz
- Диски: Plextor M6Pro
postgresql.conf:
- shared_buffers = 8GB
- work_mem = 128MB
- maintenance_work_mem = 2GB
- fsync = on
- synchronous_commit = off
- wal_sync_method = fdatasync
- checkpoint_segments = 64
- seq_page_cost = 1.0
- random_page_cost = 6.0
- cpu_tuple_cost = 0.01
- cpu_index_tuple_cost = 0.0005
- cpu_operator_cost = 0.0025
- effective_cache_size = 24GB
Вариант настроек от pgtune:
Полезные запросы:
Блокировки БД по пользователям
Код SQL select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename;Вывести все таблицы, размером больше 10 Мб
Код SQL SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size from pg_tables where tableName not like ‘sql_%’ and pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) like ‘%MB%’;Определение размеров таблиц в базе данных PostgreSQL
Код SQL SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size from pg_tables where tableName not like ‘sql_%’ order by size;Пользователи блокирующие конкретную таблицу
Код SQL select a.usename, t.relname, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid inner join pg_stat_all_tables t on t.relid=l.relation where t.relname = ‘tablename’; Код SQL select relation::regclass, mode, a.usename, granted, pid from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not mode = ‘AccessShareLock’ and relation is not null;Запросы с эксклюзивными блокировками
Код SQL select a.usename, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where mode ilike ‘%exclusive%’;Количество блокировок по пользователям
Код SQL select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename;Количество подключений по пользователям
Код SQL select count(usename), usename from pg_stat_activity group by usename order by count(usename) desc;helpf.pro
1С и Linux: Оптимизация postgresql 9.6.3
Настройка shared memoryWhat's new in PostgreSQL 9.3Работа с PostgreSQL: настройка и масштабированиеДокументация к PostgreSQL 9.6.3Немного о конфигурировании PostgreSQLСУБД для 1С Fresh. Быстро. Надежно. Бесплатно"In 9.3, PostgreSQL has switched from using SysV shared memory to using Posix shared memory and mmap for memory management. This allows easier installation and configuration of PostgreSQL, and means that except in unusual cases, system parameters such as SHMMAX and SHMALL no longer need to be adjusted. We need users to rigorously test and ensure that no memory management issues have been introduced by the change."
nano /etc/postgresql/9.6/main/postgresql.conf Проверить:dynamic_shared_memory_type = posix
Таким образом SHMMAX and SHMALL не настраиваем!
Оптимизация производительности PostgreSQLНастройки PostgreSQL для работы с 1С:Предприятием. Часть 2 Лучшие практики от gilev.ruConfiguration calculator for PostgreSQLПолезные запросы:
Пример для виртуальной машины 8 Гб - 1/2 4 Гб отдадим postgresql
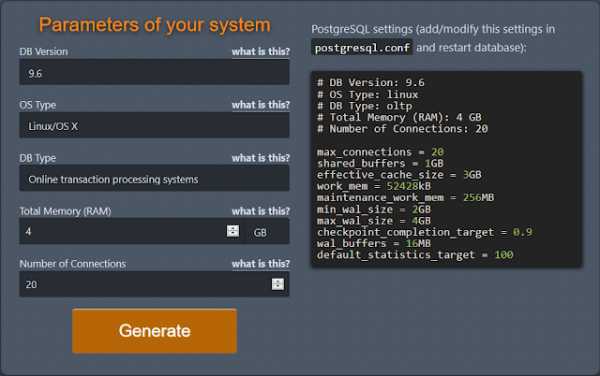 # nano /etc/postgresql/9.6/main/postgresql.conf # DB Version: 9.6 # OS Type: linux # DB Type: oltp # Total Memory (RAM): 4 GB # Number of Connections: 20 max_connections = 20 shared_buffers = 1GB effective_cache_size = 3GB work_mem = 52428kB maintenance_work_mem = 256MB min_wal_size = 2GB max_wal_size = 4GB checkpoint_completion_target = 0.9 wal_buffers = 16MB default_statistics_target = 100 PostgreSQL - реальная альтернатива для высоконагруженных систем на базе 1С !!!# nano /etc/postgresql/9.6/main/postgresql.conf ssl = false autovacuum = on autovacuum_max_workers =4 autovacuum_naptime = 20s autovacuum_vacuum_scale_factor = 0.01 autovacuum_analyze_scale_factor = 0.05 online_analyze.enable = on fsync = on synchronous_commit = off Сохранить !!! # reboot # service postgresql restart Тест Гилёва Особенности использования теста на субд PostgreSQL Установите значение параметра standard_conforming_strings в конфигурационном файле postgresql.conf в значение ‘off’ # nano /etc/postgresql/9.6/main/postgresql.conf standard_conforming_strings = off
# nano /etc/postgresql/9.6/main/postgresql.conf # DB Version: 9.6 # OS Type: linux # DB Type: oltp # Total Memory (RAM): 4 GB # Number of Connections: 20 max_connections = 20 shared_buffers = 1GB effective_cache_size = 3GB work_mem = 52428kB maintenance_work_mem = 256MB min_wal_size = 2GB max_wal_size = 4GB checkpoint_completion_target = 0.9 wal_buffers = 16MB default_statistics_target = 100 PostgreSQL - реальная альтернатива для высоконагруженных систем на базе 1С !!!# nano /etc/postgresql/9.6/main/postgresql.conf ssl = false autovacuum = on autovacuum_max_workers =4 autovacuum_naptime = 20s autovacuum_vacuum_scale_factor = 0.01 autovacuum_analyze_scale_factor = 0.05 online_analyze.enable = on fsync = on synchronous_commit = off Сохранить !!! # reboot # service postgresql restart Тест Гилёва Особенности использования теста на субд PostgreSQL Установите значение параметра standard_conforming_strings в конфигурационном файле postgresql.conf в значение ‘off’ # nano /etc/postgresql/9.6/main/postgresql.conf standard_conforming_strings = off renbuar.blogspot.com
PostgreSQL и 1С Предприятие
«Да, забудьте Вы об SQL Express» говорю я многим своим клиентам последние так года два.
Отчасти сам виноват, в 2015-ом опубликовал видео «1С 8.3 и SQL Server 2014 Express».
И это видео для многих почему-то сработало как сигнал на внедрение версии Express.
Несмотря на то, что в этом уроке я говорю о серьёзных ограничениях этой версии СУБД, да, собственно как и Microsoft, прямо пишет, — «Эту бесплатную версию стоит использовать только для теста и ознакомления».
(Цель видео в том, чтоб показать ограничения файлового варианта работы в 1С, как перейти на клиент-сервер и показать ограничения версии Express).
И лишь в некоторых случаях, когда база 1С совсем малая и с базой работает пара пользователей, нет нагрузок, тогда, может быть смысл использовать эту СУБД для реальной работы в 1С.
Но большинству конечно ограничения не позволят работать «нормально» в клиент-сервере.
Как минимум нужна версия Standard.
Альтернативой MS SQL всегда был и остается PostgreSQL.
Абсолютно бесплатная* СУБД с реализацией как под Linux, так и на Windows.
Бытует мнение, что PostgreSQL нормально работает только на Linux.
Но это ужа давно не так (Хоть изначально он и разрабатывался под UNIX-подобные платформы).
Сегодня PostgreSQL можно смело использовать и на Windows , (Пользователей 50-70- одновременно работающих в 1С будет держать нормально, до 15-ти, даже не нужно никаких доп. настроек!).
Если у Вас пользователей будет больше, тогда лучше брать MS SQL.
Конечно, в сети можно встретить примеры, (особенно в последнее время) когда PostgreSQL работает на сотнях пользователей в 1С, но я такого в живую не видел (чтоб без косяков, при большом количестве запросов) чтоб СУБД работала также быстро и хорошо, как и на MS SQL standard, например.
Вот одна из причин: PostgreSQL не умеет работать многопоточно!
Иногда в интернете, можно наткнуться на статью что PostgreSQL грузит только одно ядро на 100%, и мол не работает с многоядерными архитектурами.
Знайте, что это не так! (Вернее не совсем так!)
PostgreSQL грузит все ядра, только если есть соответствующее количество запросов .
Один большой запрос действительно может на 100% загрузить одно ядро вашего сервера так как
1 запрос = 1 поток! (На этой СУБД).
Но если запросов будет много, соответственно и все ядра будут задействованы также.
PostgreSQL способен задействовать все ядра вашего сервера!
Каждое ядро может дать нам несколько потоков, например как минимум два, и уже, чтоб задействовать 2 ядра (4 потока) будет достаточно отправить на СУБД 3 — 4 запроса.
Помните?
1 запрос = 1 поток.
Другими словами, не распараллеливается выполнение одного запроса.
Нет многопоточности! в рамках одного запроса — это одна из причин, почему PostgreSQL работает медленнее MS SQL.
Один большой запрос может стать «узким местом» в производительности вашей 1С на этой СУБД.
Есть, конечно, еще много вопросов по «бєкапу», настройке и оптимизации PostgreSQL в том числе и под крупные внедрения, но это все подробно мы будем обсуждать уже на курсе: Установка и настройка 1С 2017.
Как известно без специальных «патчей» от компании 1С СУБД-шка работает не стабильно, вылетает + есть проблемы с производительностью.
Но с «пропатченой» таких серьезных проблем обычно не возникает.
Дело в том что в 1С часто используются временные таблицы, а PostgreSQL плохо сними дружит.
«Патчи» как раз правят эти и другие «косяки 1С» в официальном релизе.
Теперь о главном!
В феврале 2015 года наиболее известные российские разработчики PostgreSQL основали компанию «Постгрес Профессиональный» (Postgres Professional), целью которой стало развитие СУБД PostgreSQL и оказание полного спектра связанных с ней услуг.
И если раньше я скачивал PostgreSQL на сайте 1С (Поддержка пользователей), то сегодня
Я беру дистрибутив на сайте postgrespro.ru (Как для Windows так и для Linux).
Внимание Важно!
PostgresPro Standard и Enterprise — платные!
https://postgrespro.ru/products/postgrespro#license
Качайте просто «пропатченую 1С» по ссылке ниже:
https://postgrespro.ru/products/1c
Enterprise — действительно очень дорогой продукт, а вот Standard на момент написания статьи, приобретается как годовая поддержка.
Другими словами Вы покупаете поддержку на год и получаете версию Standard в *подарок*.
Второй способ получить PostgreSQL бесплатно:
Для этого нужно скачать на сайте поддержки пользователей 1С, нужный Вам дистрибутив PostgreSQL со всеми патчами для 1С, и работать бесплатно на этой СУБД.
На момент написания статьи, доступна версия PostgreSQL 9.6.5 для 1С Предприятия.
Все в *свободном доступе*, можно скачать и установить у себя.
Делюсь ссылкой, друзья >>>
Дело в том, что Postgres Pro (основанный на PostgreSQL) уже содержит все нужные «патчи» для 1С Предприятия.
И Вы не «паритесь» поиском каких-то критически важных «патчей» все уже включено в эту сборку, это удобно.
Даже для Windows включены дополнительные «патчи» повышающие отказоустойчивость еще не успевшие войти в стабильный релиз, например, включены «патчи», которые исправляют проблему с правами доступа и критический баг с остановкой Postgres.
Установка:
Качаем инсталлятор на сайте по ссылке выше.
И приступаем к установке.
Конечно я рекомендую ставить СУБД на Windows Server 2016.
Установка PostgreSQL на Windows совсем не сложная, но во избежание каких-то возможных проблем, смотрите ниже в скриншотах весь процесс пошагово:
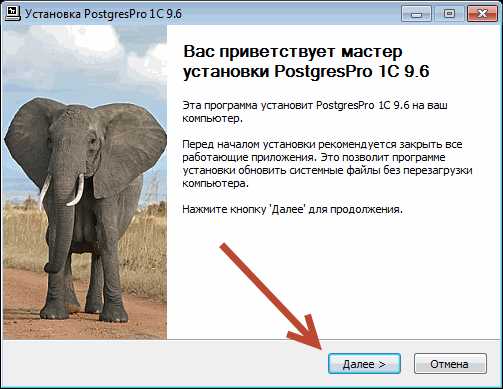
Как видно уже на скрине, сборка действительно под 1С-ку. «PostgresPro 1C 9.6».
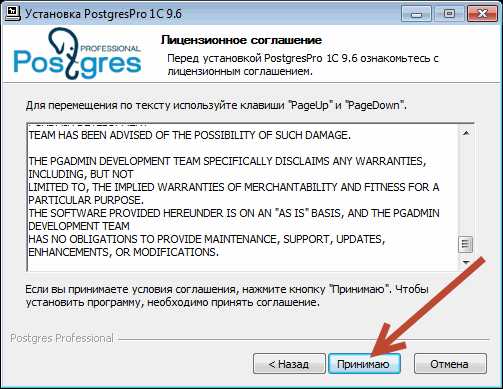
Принимаем условия лицензионного соглашения «Принимаю».
И установим все нужные компоненты.
Клик по кнопке «Далее».
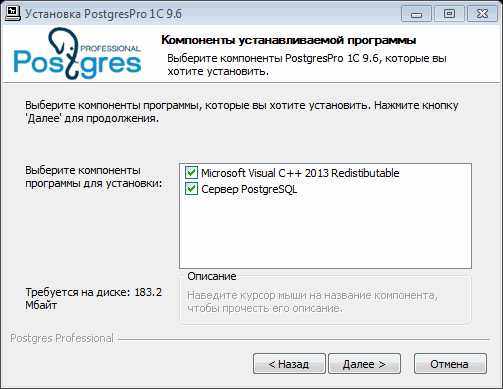
Укажем каталог где будет установлен сам PostgresPro (Можно оставить каталог по умолчанию).
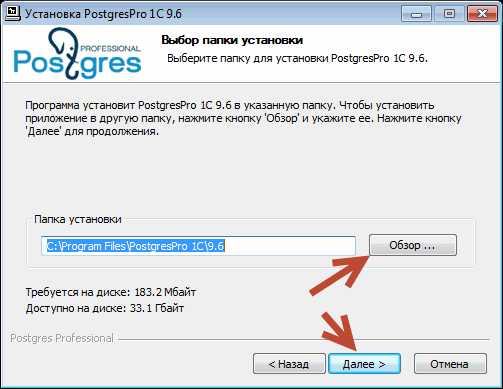
Клик по кнопке «Далее».
Теперь нужно указать каталог для наших баз данных.


На вкладке параметров порт 5432 можно оставить по умолчанию (Если у Вас он свободный на момент установки).
Затем птичку «Подключение с любых IP адресов» убираем если Сервер 1С и СУБД будут располагаться на одном сервере.
Иначе оставляем все как есть.
Локаль: — Russian, Russia.
Супер пользователя можно оставить по умолчанию «postgres».
И обязательно создадим пароль для него.
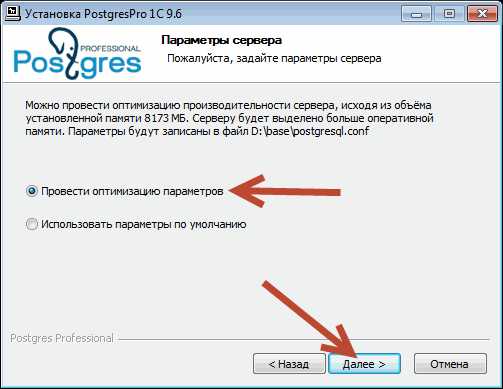
Птичку возле «Провести оптимизацию параметров» оставляем по умолчанию.
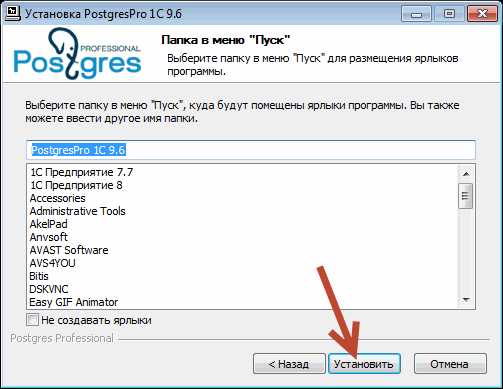
И клик по кнопке «Установить».
Все готово! можно создавать базу используя утилиту администрирования серверов 1C.
Для удобства администрирования, рекомендую еще установить дополнительно и PGAdmin 4.
kuharbogdan.com