CppCMS - фреймфорк C++. Преимущества. Подготовка сервера. Установка. Оптимизация серверной логики
Серверная оптимизация - Что кешировать?
Понравилась статья — публикую ее здесь.
Всё. На этом можно было бы статью закончить, так как эта аксиома повторяется из года в год на форумах и конференциях и кочует из текста в текст на всех технических ресурсах. Однако это ёмкое «Всё» не поясняет деталей. Ведь существует достаточно широкая прослойка программистов, движки и проекты которых справляются с задачей без мемкеша и шардинга. Но момент нагрузки приходит, и приходится разбираться.Для таких людей я и разобрал на запчасти это универсальный ответ высоконагруженных проектов.Ограничимся изучением системы для веба. Попросту говоря, на привычном обычном сайте. Используете ли вы готовую CMS, или уже выросли до каркаса, или написали «с нуля» код для нестандартного проекта – основными элементами процесса приёма-отдачи данных всегда будут одни и те же узлы. Я их рассмотрю с точки зрения «Где что можно закешировать».
База данных
Даже если у вас файловая база, есть драйвер (ведь так?) который отвечает за выдачу необходимой информации.Что тут у нас? Обычно располагать данные по алфавиту неэффективно, поэтому лучшие умы уже придумали огромное количество методов, способов и хаков по скоростной доставке информации на блюдечке. И вы должны знать, что БД не просто вводят индексы, а кешируют их, кешируют результаты запросов, оптимизируют структуру реляционных таблиц и пытаются лишний раз не сканировать тонны данных. Но, вера в гениев это одно, а проверка файла конфигурации на включенность данных механизмов – это долг каждого разработчика! Если у вас есть отдельный администратор сервера (или серверов), то при первом же зафиксированном простое оного заставьте его подкрутить гайки в настройках вашего самого важного узла. Изучите потребление памяти, фрагментированность и доступность дискового пространства для временных файлов.Своевременное грамотное кеширование запроса может дать вам достаточно времени в условиях быстрорастущего проекта, для подкручивания гаек на всех последующих этапах.Эта оптимизация доступна всем участникам регаты с полным доступом к хостингу и разобраться с темой придётся, рано или поздно.Есть еще один шикарный полноформатный кеш, который называется реплика базы данных. Но вряд ли вы зачитаетесь данной статьёй, если в вашем проекте уже есть настолько сложная структура, как мастер база, её реплика, веб-сервер, файл-сервер и группа сбора статистики. В любом случае отдельная база для чтения может с натяжкой считаться кешем.
Логика (или наш Код, которым мы гордимся)
Язык программирования значения не имеет. Это просто инструмент обработки полученных данных. Даже если у вас не модульная структура и весь проект – это один файл, вы всё равно работаете с данными.Если код ваш, то вы обязаны включать голову во время написании кода. Апологеты быстрой разработки и святого ORM скажут, что тут искать нечего и лучше кешировать где то в другом месте. Доля истины есть, однако каких только уродов не рождают скорописцы!Итак, на что надо обратить внимание, когда мы уже смотрим в код?Оптимизируйте запросы к базе. Зачем тянуть все данные, когда нужен только индекс и дата? Чем меньше запрос, тем легче БД его закешировать.Определите с помощью утилит БД так называемые медленные запросы. Подумайте над индексами в таблицах или в перепланировании запросов и необходимых данных к кешированию это не относится, но раз уж мы тут, то пуркуа бы и не па прямо сейчас?После стабилизации кода посмотрите где вы дважды обращаетесь к базе за одинаковыми или похожими данными. Может лучше сделать один запрос потолще, но потом полученные данные использовать в нескольких модулях/функциях/циклах? Это еще не кеширование, но вот дальнейшая оптимизация – вынос сложных или массивных результатов вычисления в кеш (в базу или файл) в виде сериализованного массива, или чего там вам удобно, будет очень кстати. И тогда промежуточные вычисления будут проводится быстрее, менее затратно и более комфортно для сайта, задач по расписанию и API.Соберите всю мелочь, которая обычно болтается в сессии, в переменных, в куках в единое место (если позволяет политика безопасности) и обращайтесь к такой записной книжечке. Это лучше чем вызывать обращение к файловой системе, вызывать методы класса, которые вызывают функцию общего класса, которая выдаёт логин пользователя или, о ужас, дёргает базу простым запросом. Ведь вы не уверены, что чтение сессии происходит из ОЗУ а не из файла сессии? А может админ без спроса вынес сессию в базу а метод этого не учёл? Или логика кода предполагает интернациализацию через тонны абстракций и вызовы подфункций, а вам надо аяксом три раза вернуть слово «Корзина».
Заниматься кодом рекомендуется в последнюю очередь. То есть: бизнес налажен, база оптимизирована, внешний кеш работает, всё в порядке, расширяемся. Кешировать данные в этом узле следует на этапе оптимизации затрат на расширение серверной части или когда узкая математическая часть не успевает обрабатывать большие потоки данных. Такое случается в громоздких маркетинг-планах сетевых компаний, генерации отчётов по вычурной статистике и прочих подобных вещах. Результатом оптимизации будет всего лишь снижение нагрузки на не самом нагруженном сервере и оттянет время покупки балансировщика и второго серва.Если вы еще сидите на CMS и начинаете думать про её оптимизацию, то пора переписывать движок под свои высоконагруженные нужды или докупить ОЗУ. Нет денег? Тогда срочно занимайтесь монетизацией ресурса, а не ковырянием недр кода!
Шаблонизатор
Вроде бы и код, но немного более специализированный. Этот элемент практически всегда присутствует и тоже важен для наших исследований.Что такое шаблон? Это некая конструкция, которая служит сырьём для создания кода на последующей компиляции. Разница только в том, что в этом коде огромное количество тегов, строк и ссылок, которые перемежаются фрагментами логики. Вещь достаточно понятная, но я замечал, что многие начинающие не вникают в детали работы смарти и блица. А зря!Если грубо. то шаблонизатор сначала ищет ранее скомпилированный код (или проверяет его актуальность). Если его нет, то он обрабатывает заново шаблон, записывает файл (удаляя иногда предыдущий). Иногда, разработчик просто забывает включить подобное кеширование шаблонов (в рабочей версии неудобно чистить кеш). Хуже, когда опция включена, но время жизни предкомпилированного файла невелико. Тогда задержка нерегулярна и «отловить» её начинающему спецу сложно. Синдром «У меня не тормозит».
Разберитесь в возможностями кеширования вашего шаблонизатора, подберите оптимальные промежутки обновления (если это надо). На крайний случай поставьте задачу в расписание по принудительному обновлению этого кеша ночью, чтобы не вылезло в пике. Изучите скоростные характеристики того диска, где хранятся кеши. Может имеет смысл и есть возможность вынести в ОЗУ?Настройка кеширования этого этапа обязательна в начале развития проекта. А вот перебор оптимальных значений уже можно перенести на после тюнинга базы и введения кеширования выдачи.Для тех, кто сидит на готовой CMS, простора для фантазии тут маловато. Однако проверить что используется (алгоритм или готовый продукт), проверить где хранится кеш шаблонов и как он себя ведёт будет не лишним.
Результат
Его величество сгенерированная страница должна быть доставлена клиенту как можно быстрее с необходимой актуальностью. И тут мы можем что-то придумать отдельно, например файловое кеширование или любимый многими мемкеш.Если вы всё с интересом еще читаете данную статью, то ваш проект, скорее всего, уже столкнулся с проблемами подтормаживания, но всё еще жив и работает в штатном режиме.Для аксакалов проектовнедрения и сайтостроения нет ничего нового в настройке кластера мемкеша и их проблемы упираются в актуальность выборки. Но, спешу вас удивить, существует огромное количество проектов нормального размера, в которых руки вебмастера еще не добрались до нормального обычного кеша в noSQL БД. Сначала поднимали проект как могли, формировали идею на лету. Потом могло банально не хватить денег на второй сервер, куда стоило бы вынести нашу пухлую базу данных. Есть огромное количество людей, которые хорошо разбираются в бизнесе, дизайне, пишут хорошие тексты. Они подняли проект, но вот сил углубится в администрирование *nix чтобы установить мемкеш уже нет.Короче говоря, если вы выросли из памперса, первое что надо делать, это кешировать готовую после шаблонизатора страницу. Сначала статику. Потом статические фрагменты динамических страниц. Дальше ищите своё бутылочное горлышко. Если нет прав для установки хранилища ключ-значение, сделайте себе на первых порах файловый кеш главной самых востребованных страниц. Даже такая примитивная вещь сэкономит больше, чем месяцы оптимизации на предыдущих узлах.Пользователям систем управления контентом стоит поискать в закромах модуль кеширования для своей версии. Или даже наиболее удачный его вариант. К примеру MODx сразу включает механизм файлового кеширования как целых страниц, так и отдельных чанков и сниппетов. Но существует модуль, который вместо файлового хранилища предлагает воспользоваться мемкешем.
Балансировщик
Если у вас его еще нет, то он появится со временем. С его появлением вся лабуда сверху будет у вас называться бэкэндом, а наш подзаголовок назовётся фронтендом. Справедливости ради надо сказать, что файловое кеширование результата и фронтенд причудами архитектора может располагаться и рядом, и в обратном порядке. Но не будем усложнять таксономией простую статью для новичка.Задача балансировщика разрулить очередь обычных запросов между всеми бэкендами, определить по типу запроса куда его направить и т.п. Главная оптимизация на этом этапе – отдача статических элементов, минуя все тяжеловесные баррикады из веб-серера с логикой и базой с данными. Это, главным образом, картинки, таблицы стилей, документы. Можно настроить отдельно файловый кеш, который будет отдаваться не бекендом, а напрямую балансировщиком. Надо всего лишь организовать поставку html (js, css, xml) страниц по нужному пути своевременно.Можно написать свой модуль с персональной логикой кеширования результатов работы бэкэндов. Ведь ответ не обязательно бывает киломегабайтный. Можно разом для всех в памяти сервера балансировщика запомнить JSON с текущим лучшим игроком или последним твитом админа.Прибегать к внедрению самого балансировщика можно на ранних этапах развития проекта. Ендженикс перед апачем много не съест, а масштабируемость проекта вырастет.
Клиент
Он тоже подвергается нашим уговорам что-то запомнить и не просить лишний раз нас занятых мучить всех демонов системы. И сами браузеры успешно пытаются избавить удалённый сервер от лишних мучений. Локально кешируются графические файлы и прочая мультимедия. Запоминаются пары логин-пароль, последние посещённые ресурсы и прочее. Но мы можем сделать еще более продвинутый вариант: ведь мы же знаем чего хотим от своей страницы!В минимальном варианте, мы можем рассчитывать на хранение всякой персонализированной мелочи в печеньках. У флеша есть какой-никакой запас мегабайт для разгона. HTML5 нам даёт еще больший полигон для хранения записочек в формате огромных талмудов. Сохраните безопасную информацию на стороне клиента и модифицируйте страницу джаваскриптом. Корзина, последние отправленные сообщения, текущую амуницию и прочее.Еще лучше, когда вы отвяжете логику своего приложения от привычного PHP и перенесёте на сторону нашего любимого пользователя. Сам скрипт закешируется браузером (а предварительно пулей отдастся енджениксом) и спокойненько на стороне сервера посчитает статистику персональных данных (покупок, бонусов, убитых монстров) из локального кеша.
Итоги подведём
Надеюсь для всех стартаперов-бизнесменов, а не технарей, вынесенная в заглавие фраза и короткий ответ теперь означают гораздо больше, чем просто необходимость заплатить денег за решение проблемы. Мы рассмотрели общую схему работы обычного веб-проекта в разрезе отдачи одиночного ответа пользователю и теперь понимаем что и когда и в какую сторону можно заоптимизировать кешированием. Прежде чем натравливать программистов на оптимизацию кода уже можно смело анализировать эффективность покупки ОЗУ или введения нового сервера с балансировщиком и мемкешем на нём же.Как и чем именно кешировать – вопрос другой. Где и когда, думаю уже можно определить:Настройте быстро базовые мелочи в конфигурации базы данных, проверьте кеширование шаблонизатора и|или CMS. По возможности сразу настройте балансировщик и организуйте отдачу статики минуя веб-сервер.Кешируем результат (статику, фрагменты динамики, полный кеш) в файлы или key-value хранилище.Глубоко изучаем нашу базу данных и настраиваем максимально эффективное кеширование запросов, проводим оптимизацию ключей. Возможно пора вводить реплику.Изучаем внутренности нашего шаблонизатора, оптимизируем параметры. Возможно меняем привычный Smarty на более быстрый, но сложный в реализации Blitz. Сокращаем и ускоряем файловые операции на этом уровне.Устраняем косяки и излишки нашего кода. Оптимизируем работу с данными из базы и приводим в порядок работу с мелочью.В работающем коде и отработанной бизнес-логике проекте начинаем переносить на сторону клиента рутинные операции, персонализацию и её обработку.
И не забываем: кеширование – это не единственный метод оптимизации проекта!http://habrahabr.ru/blogs/server_side_optimization/129623/
(Просмотров 43, 1 за сегодня)
yavasilek.ru
Серверная оптимизация на практике
23 апреля 2011 г.
Сайт представляет собой площадку для общения пользователей – тут есть группы, блоги, фотогалереи, в общем полноценная социальная сеть, впридачу каждому пользователю создается почтовый ящик с разными крутыми фишками. Но сейчас не об этом. Моей задачей было посмотреть, что можно сделать с сайтом в плане улучшения быстродействия. Как оказалось, даже имея в наличии посредственный сервер с одноядерным процессором Pentium 2800 и 1 гигабайт памяти на борту, можно сделать вполне себе готовый к высоким нагрузкам проект.
Фронтенд – бэкенд
Беглый взгляд обнаружил, что основной функционал сайта составляет InstantCMS. Платформа стандартная LAMP, дистрибутив Ubuntu 10.10. Как это обычно бывает, веб-сервером служил Apache2. Первой идеей стало установка легкого фронтенда nginx перед Apache. Не так давно вышла версия nginx 1.0.0, ее я и поставил на сервер:
wget <a title="Откроется в новом окне - sysoev.ru" target="_blank" href="http://sysoev.ru/nginx/nginx-1.0.0.tar.gz">sysoev.ru/nginx/nginx-1.0.0.tar.gz</a> tar xvzf nginx-1.0.0.tar.gz cd nginx-1.0.0 ./configure --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-client-body-temp-path=/var/lib/nginx/body --http-log-path=/var/log/nginx/access.log --http-proxy-temp-path=/var/lib/nginx/proxy --lock-path=/var/lock/nginx.lock --pid-path=/var/run/nginx.pid --with-http_gzip_static_module --with-http_stub_status_module --with-http_realip_module --with-http_ssl_module make install strip /usr/local/nginx/sbin/nginxВот часть конфига nginx, описывающая виртуальный хост moybox.ru. В Ubuntu этот файлик кладется в /etc/nginx/sites-enabled.server {listen 0.0.0.0:80;server_name moybox.ru www.moybox.ru;location / {proxy_pass 127.0.0.1:81/;}location ~* \.(jpg|gif|png|css|js)$ {root /www/site;}}Вот статистика до и после установки nginx, которая поражает (точнее, ужасает скорость Apache в данном случае):
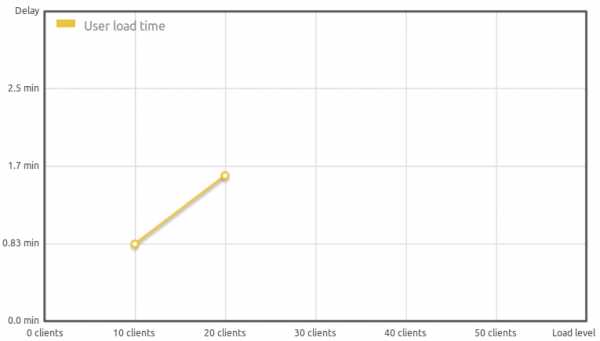
| Clients | 10 | 20 |
| Delay (min) | 0,83 | 1,6 |
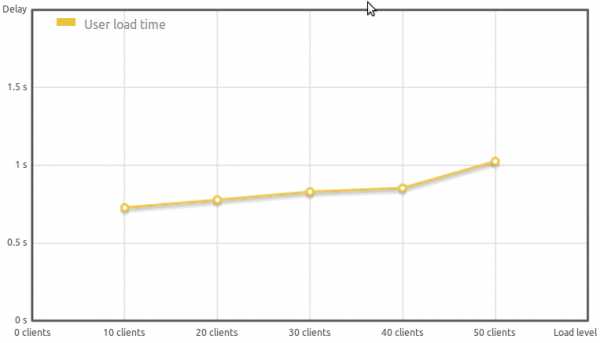
| Clients | 10 | 20 | 30 | 40 | 50 |
| Delay (ms) | 659 | 686 | 684 | 727 | 819 |
gzip_static и оптимизация файлов
С этим разобрались, но естественно, это еще не все пути оптимизации. Теперь посмотрим на размер главной страницы сайта с помощью другого инструмента того же сайта – Page Analyzer, сгруппируем файлы главной страницы по размеру:
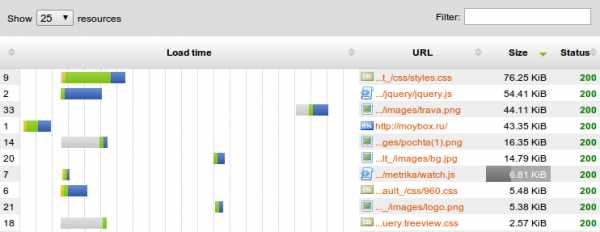 Total downloaded data: 290.47 KiB Видим, что значительную часть занимают CSS, javascript и всякие фоновые картинки. С последним ничего хитрого нет. Травку в нижней части сайта в формате png конвертируем в формат jpeg и получаем 7К из исходных 44К. Изображение письма преобразуем в gif со степенью постеризации 64 и прозрачным фоном, получаем 8К из исходных 16К, практически без потери качества “на глаз”.
Total downloaded data: 290.47 KiB Видим, что значительную часть занимают CSS, javascript и всякие фоновые картинки. С последним ничего хитрого нет. Травку в нижней части сайта в формате png конвертируем в формат jpeg и получаем 7К из исходных 44К. Изображение письма преобразуем в gif со степенью постеризации 64 и прозрачным фоном, получаем 8К из исходных 16К, практически без потери качества “на глаз”.Теперь перейдем к оптимизации файлов css/js и собственно html, ведь они одни составляют 130К – около половины веса страницы.
В nginx есть такая замечательная директива gzip, которая позволяет отдавать браузеру сжатую в gzip версию файла. Причем если включена еще и gzip_static, то, к примеру, вместо filename.txt будет отдаваться лежащий рядом заранее заготовленный файл filename.txt.gz. То есть, таким образом экономится время на сжатие файла сервером – один раз сжал и далее его только отдавать. Нужно только следить за актуальностью сжатого файла по отношению к оригиналу.
Наибольший размер имеют styles.css и jquery.js, их и будем оптимизировать. Для их сжатия я использую yui-compressor, вот так (здесь также я решил сжать фоновый файл bg.jpg):
yui-compressor styles.css | gzip -c -5 > styles.css.gz yui-compressor jquery.css | gzip -c -5 > jquery.css.gz gzip bg.jpg > bg.jpg.gzПо многочисленным рекомендациям, ставить уровень сжатия GZIP выше 5 не стоит – только тратится процессорное время, а улучшение сжатия практически незаметно. Другие css- и js-файлы, а также HTML как результат работы InstantCMS, будем сжимать на лету и отдавать по gzip. А мелкие файлы меньше 1 килобайта сжимать вообще не будем.Вот полученный конфиг nginx:user www-data;worker_processes 1;error_log /var/log/nginx/error.log;pid /var/run/nginx.pid;events {worker_connections 1024;}
http {include /etc/nginx/mime.types;
access_log /var/log/nginx/access.log;
sendfile on;tcp_nopush on;keepalive_timeout 65;tcp_nodelay on;
gzip on;gzip_static on;gzip_disable "MSIE [1-6]\.(?!.*SV1)";gzip_types application/x-javascript text/css;gzip_min_length 1024;include /etc/nginx/conf.d/*.conf;include /etc/nginx/sites-enabled/*;}Вот результат проделанных махинаций, весьма впечатляет:
Полный размер главной страницы составил 93.13 KiB, что меньше прежнего размера в 3 раза (!).Оптимизация PHP
Еще можно ускорить выполнение php-скриптов за счет кеширования байткода в оперативной памяти. Установим eaccelerator, также из исходников:
wget <a title="Откроется в новом окне - bart.eaccelerator.net" target="_blank" href="http://bart.eaccelerator.net/source/0.9.6.1/eaccelerator-0.9.6.1.tar.bz2">bart.eaccelerator.net/source/0.9.6.1/eaccelerator-0.9.6.1.tar.bz2</a> tar xvjf eaccelerator-0.9.6.1.tar.bz2 cd eaccelerator-0.9.6.1 apt-get install php5-dev phpize ./configure make installПрописываем в /etc/php5/apache2/conf.d/eaccelerator.ini следующие параметры:extension="eaccelerator.so"eaccelerator.shm_size="64"eaccelerator.cache_dir="/var/cache/eaccelerator"eaccelerator.enable="1"eaccelerator.optimizer="1"eaccelerator.check_mtime="1"eaccelerator.debug="0"eaccelerator.filter=""eaccelerator.shm_max="0"eaccelerator.shm_ttl="3600"eaccelerator.shm_prune_period="1800"eaccelerator.shm_only="0"eaccelerator.compress="1"eaccelerator.compress_level="9" Создаем каталог для кеша:
mkdir -m 0777 /var/cache/eacceleratorи перезапускаем веб-сервер:
/etc/init.d/apache2 restartЕсли апач откажется запускаться с вот такой ошибкой:eAccelerator: Could not allocate 67108864 bytes, the maximum size the kernel allows is 33554432 bytes. Lower the amount of memory request or increase the limit in /proc/sys/kernel/shmmax.Тогда нужно либо уменьшить запрашиваемый объем памяти с 64 мегабайт на поменьше, либо повысить порог shmmax до требуемого значения:echo 67108864 > /proc/sys/kernel/shmmaxecho kernel.shmmax = 67108864 >> /etc/sysctl.confПосле этого наши php-скрипты должны кешироваться в памяти, что можно наблюдать, к примеру, в выводе функции phpinfo:

Вот результат, которого удалось добиться на данном этапе:
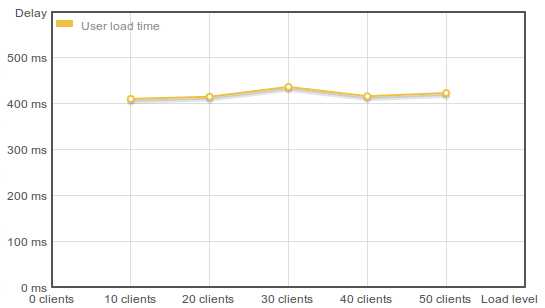
| Clients | 10 | 20 | 30 | 40 | 50 |
| Delay (ms) | 410 | 415 | 437 | 416 | 423 |
к – время полной загрузки страницы (с учетом всех картинок, скриптов и т.п.):
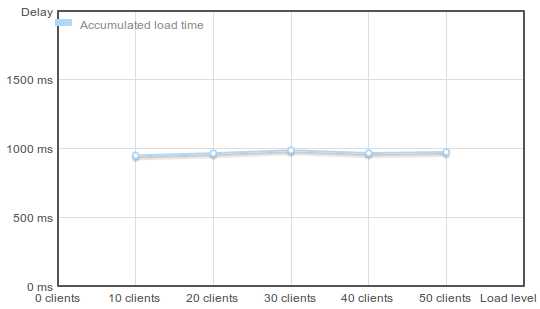
Эта история – хороший пример того, что может происходить, когда в каком-то проекте никто не задумывается о производительности, и оставляет все настройки “по умолчанию”. Как показала практика, даже простая установка nginx как фронтенда к апачу ускоряет сайт в десятки раз.
korzh.net
performance - Логика на стороне клиента ИЛИ логика на стороне сервера?
Я обычно реализую как можно более разумную клиентскую сторону. Единственными исключениями, которые заставили бы меня перейти на сервер, было бы решить следующее:
Целевые проблемы
Любой может отлаживать JavaScript и читать пароли и т.д. Здесь нет проблем.
Проблемы с производительностью
Двигатели JavaScript развиваются быстро, поэтому это становится проблемой, но мы все еще находимся в мире с доминированием в IE, поэтому все будет замедляться, когда вы будете обрабатывать большие массивы данных.
Проблемы с языком
JavaScript - это слабо типизированный язык, и он делает много предположений вашего кода. Это может привести к тому, что вы будете использовать ложные обходные пути, чтобы заставить работу работать в определенных браузерах. Я избегаю такого типа вещей, как чума.
Из вашего вопроса, похоже, вы просто пытаетесь загрузить значения в форму. Если у вас есть какие-либо проблемы, у вас есть 3 варианта:
Чистая клиентская сторона
Недостаток заключается в том, что время загрузки ваших пользователей удваивается (одна загрузка для пустой формы, другая загрузка данных). Однако последующие обновления формы не потребуют обновления страницы. Пользователям это понравится, если будет много данных, извлекаемых из загрузки сервера в ту же форму.
Чистая серверная сторона
Преимущество заключается в том, что ваша страница будет загружаться с данными. Однако последующие обновления данных потребуют обновления для всех/значимых частей страницы.
гибридный сервер-клиент
У вас будет лучшее из обоих миров, однако вам нужно будет создать две точки извлечения данных, в результате чего ваш код слегка раздувается.
Есть компромиссы с каждым вариантом, поэтому вам придется взвесить их и решить, какой из них вам больше всего пригодится.
qaru.site
Оптимизация HTTP-сервера через версионность ресурсов. Особенности реализации
- Суть оптимизации
- Page load vs forced refresh
- Потребуется автоматизация
- Реализация серверной части
- Оптимизация серверной части
- Особенности google app engine
- Исходный код
- Резюме
Рассматривается пример реализации для Google App Engine / Python.
Суть оптимизации
Инженеры Yahoo в своей известной статье писали об интересной технике оптимизации обработки HTTP через версионность файлов. Суть её такова… Обычно в HTML пишут просто:< img src="image.jpg" >
Заполучив однажды image.jpg в кэш, после браузер снова считывает HTML и снова обнаруживает там ссылку на ту же картинку. Понять обновилась ли она на сервере в общем случае браузер самостоятельно не может, так что ему приходится послать запрос на сервер.
Чтобы избежать лишнего запроса, можо указывать версию ресурса в его адресе, сделав адрес уникальным:
< img src="image.v250.jpg" >
Таким образом, браузер может быть уверен что файл версии №250 в будущем не поменяется, и №251 тоже; и если №250 есть в кэше, значит можно использовать его безо всяких вопросов к серверу. Придать браузеру эту уверенность помогут два HTTP-заголовка:
// Будте спокойны, картинка не обновится никогда Expires: Fri, 30 Oct 2050 14:19:41 GMT // и может хранится в кэше вечность Cache-Control: max-age=12345678, public
Таким образом, для просмотра некой страницы в энный раз требуется только скачать HTML, а обращаться к многочисленным ресурсам уже не требуется.
Page Load vs. Forced Refresh
В текущем виде эта оптимизация работает для переходов по ссылкам и для Ctrl+L, Enter. Но если пользователь обновляет текущую страницу через F5, браузер забывает что для ресурсов было указано «более не беспокоить», и вот на сервер несутся «лишние» запросы, по одному на каждый ресурс. Такое поведение браузеров уже не изменишь, но то что можно и нужно сделать — это не отдавать каждый раз файлы по полной программе, но ввести дополнительную логику, по возможости стараясь отвечать «у меня ничего не изменилось, возьмите из своего кэша».Когда браузер запрашивает «image.v250.jpg», то в случае если у него в кэше есть копия, браузер посылает заголовок «If-Modified-Since: Fri, 01 Jan 1990 00:00:00 GMT». Браузер пришедший за этой картинкой в первый раз такой хидер не отправляет. Соответственно, север должен первому говорить «ничего не изменилось», а второму честно отдать картинку. Конкретно в нашем случае дату можно не анализировать — важен сам факт наличия картинки в кэше, а картинка-то там верная (из-за версионности файлов и уникальных URL'ов).
Но просто так заголовок «If-Modified-Since» на сервер не придёт, даже если картинка лежит в кэше. Чтобы заставить браузер отправлять этот заголовок, в (хронологически) предыдущем ответе нужно было отдать заголовок «Last-Modified: Fri, 01 Jan 1990 00:00:00 GMT». На практике это всего лишь означает что этот заголовок сервер должен отдавать всегда. Можно отдавать честную дату последнего изменения файла, а можно указать любую дату в прошлом — эта же дата потом пойдёт обратно на сервер, а там она, как уже выяснилось, особого интереса не представляет.
По сути, описываемая в этом параграфе оптимизация прямого отношения к Yahoo'вской не имеет, но должна использоваться в паре, чтобы избежать лишних нагрузки. Иначе эффект будет неполным.
Потребуется автоматизация
Техника неплохая, но расставлять версии файлов вручную на практике маловозможно. В GAE/django проблема решается через custom tags. В шаблоне пишется код:< img src="{% static 'image.jpg' %}" >
преобразующийся в HTML:
< img src="/never-expire/12345678/image.jpg" >
И вот реализация такого тэга:
def static(path): return StaticFilesInfo.get_versioned_resource_path(path) register.simple_tag(static)
Реализация серверной части
В основном, данная оптимизация удобна для обработки статических файлов — картинок, css, javascript. Но App Engine обрабатывает файлы означенные как static сама (не очень эффективно) и не даст поменять заголовки HTTP. Поэтому в дополнение к стандартной директории «static» появляется ещё одна — «never-expire».Сначала обработчик GET-запроса проверяет что запрашиваемая версия файла соответствует последней. Если не соответствует — перенаправляет на новый адрес, для порядку:
# Some previous version of resource requested - redirect to the right version correct_path = StaticFilesInfo.get_resource_path(resource) if self.request.path != correct_path: self.redirect(correct_path) return
Потом выставляет заголовки ответа: — Content-Type согласно расширению файла — Expires, Cache-Control, Last-Modified как уже было описано.
Если в запросе замечен заголовок If-Modified-Since, ничего не делаем и выставляем код 304 — ресурс не изменился. Иначе содержимое файла копируется в тело ответа:
if 'If-Modified-Since' in self.request.headers: # This flag means the client has its own copy of the resource # and we may not return it. We won't. # Just set the response code to Not Changed. self.response.set_status(304) else: time.sleep(1) # todo: just making resource loading process noticeable abs_file = os.path.join(os.path.split(__file__)[0], WHERE_STATIC_FILES_ARE_STORED, resource) transmit_file(abs_file, self.response.out)
Возможно, если БД в GAE побыстрее файловой системы, стоит при первом запросе файла копировать содержимое файла в базу и потом обращаться уже только туда. Вопрос для меня открытый.
Оптимизация серверной части
В качестве версии файла можно использовать как версию из VCS, так и время последнего обновления файла — тут принципиальной разницы нет. Я выбрал второе, да с ним и попроще:os.path.getmtime(file)
Однако опрашивать файловую систему на каждый запрос вроде бы не очень хорошо — I/O всегда медленный. Поэтому можно собрать информацию о текущих версиях (всех) статических файлах при первом запросе и положить информацию в memcache. На выходе получается такой хэш:
{ 'cover.jpg': 123456, 'style.css': 234567 }
который и будет использоваться в custom tag'е для нахождения последней версии. Естественно, понадобится что-то вроде синглтона на случай если memcache протухнет:
class StaticFilesInfo(): @classmethod def __get_static_files_info(cls): info = memcache.get(cls.__name__) if info is None: info = cls.__grab_info() time = MEMCACHE_TIME_PRODUCTION if is_production() else MEMCACHE_TIME_DEV_SERVER memcache.set(cls.__name__, info, time) return info @classmethod def __grab_info(cls): """ Obtain info about all files in managed 'static' directory. This is done rarely. """ dir = os.path.join(os.path.split(__file__)[0], WHERE_STATIC_FILES_ARE_STORED) hash = {} for file in os.listdir(dir): abs_file = os.path.join(dir, file) hash[file] = int(os.path.getmtime(abs_file)) return hash
Особенности Google App Engine
Можно собрать информацию о всех статических файлах, но что если дизайнер изменит картинку? Как сервер узнает что пора обновить закэшированные версии файлов? В общем случае не очень себе представляю — нужно или заводить демона слушающего изменения файловой системы, или не забывать выполнять скрипты после деплоя.Но App Engine — случай особенный. В этой системе разработка ведётся на локальной машине, после чего готовый код (и статические файлы) разворачиваются (деплоятся) на сервер. И, что важно, файлы на сервере уже не могут быть изменены (до следующего деплоя). То есть достаточно прочитать версии лишь однажды и более не заботиться о том что они могут поменяться.
Единственное, при локальной разработке файлы меняться очень даже могут, и если в данном случае не действовать альтернативно, браузер будет, например, показывать разработчику старую версию изображения, что неудобно. Но в этом случае производительности важна не очень, так что можно класть данные в memcache на считанные секунды или не класть вовсе.
Исходный код законченного примера
code.google.com/p/investigations/source/browse/#svn%2Ftrunk%2Fnever-expire-http-resourcessvn checkout investigations.googlecode.com/svn/trunk/never-expire-http-resources investigations
Резюме
На appspot пока что не заливал, но локально всё работает и летает. Люди, пользуйтесь благами клиентско-серверной оптимизации, не отвечайте тупо 200 OK :)UPD. В комментариях пишут (и я подтверждаю) что для статических файлов того же эффекта возможно добиться и через стандартный static. То есть для обработки статики подобный «ручной» код вряд ли подходит — с этим лучше справится GAE. Однако подход может быть полезен для обработки динамически создаваемых ресурсов. В таком разрезе ETag может быть удобнее чем Last-Modified для реализации.
habr.com
CppCMS - фреймфорк C++. Преимущества. Подготовка сервера. Установка
Фреймворк CppCMS используется для разработки быстрых Интернет-сервисов на языке C++. Программы на языке C++ ускоряют работу веб-сайта, сокращают потребляемые ресурсы, время ответа сервера, время обработки запроса. Готовый машинный код компилированных программ веб-сайта исполняется быстрее, чем код на интерпретируемых языках, как например PHP, Perl. Использование фреймворка CppCMS даёт набор готовых решений и компонентов.
CppCMS - это инструмент разработки веб-сервисов реального времени. Высоконагруженные сайты с тысячами обращений в секунду, в отличие от небольших Интернет-сайтов, требуют оптимизации использования ресурсов и ускорения работы. Язык программирования C++ вместе с готовыми решениями CppCMS могут применяться для эффективного решения задач при разработке веб-сайтов, сервисов и приложений.Создаваемые на C++ веб-приложения, сетевые службы, интерфейсы, интерактивные сервисы позволяют оптимизировать работу сайта с высокой нагрузкой за счёт ускорения отдельных функций или всех программ сайта.
Какие задачи эффективно решаются с применением CppCMS?
- Сайты с высокой нагрузкой, для которых важны критерии: скорость работы, эффективность, время отклика сервера, количество одновременных соединений.
- CppCMS рассчитана на обеспечение бесперебойной работы с сотнями тысяч HTTP-соединений одновременно.
- Сервисы, работающие в режиме реального времени. Например, push-уведомления технологии Comet/Server.
- Вспомогательные или служебные веб-сервисы с большим количеством одновременно обрабатываемых запросов.
- Также CppCMS может использоваться для разработки не сетевых программ и встраиваемых систем.
Если скорость работы вашего сервера при разработке сайтов на других платформах (Drupal, Django, ASP.NET) создаёт неудобства для пользователей, кеширование и распределение нагрузки между серверами решает задачу дорого и неэффективно, вам стоит использовать CppCMS.
Преимущества CppCMS
- Высокая производительность систем при масштабировании проектов и увеличении нагрузки
- Сокращение потребляемых ресурсов (процессорного времени, памяти)
- Экономия вычислительных мощностей (1 сервер вместо серверной фермы)
- Прямая логика разработки (разработка и внедрение алгоритмов и интерфейсов системы вместо оптимизации и распределения вычислений)
- Более точная диагностика аварий и обеспечение высокого уровня надёжности разрабатываемых систем
- CppCMS, как инструмент разработчика, обеспечивает уровень виртуализации разработки, предлагает набор готовых решений.
Для примера, как создать страницу с исполняемым C++ кодом: http://www.youtube.com/watch?v=7VcxdZbXkOc
Как работать с CppCMS
CppCMS может работать на Интернет-сервере (VPS / VDS) или на локальном веб-сервере. Фреймворк работает на Windows, Linux. Для пользователей Linux ниже предложены инструкции установки и настройки веб-сервера на ОС Убунту.
Для работы CppCMS и сайтов мы установим веб-сервер Nginx, PHP FastCGI, MySQL и компилятор C++, а также необходимые пакеты (зависимости).
Для написания кодов и работы над проектами используйте IDE - среду разработки на C++. Например, Code::Blocks или другие по совету Artemiz на Хабре.
Установка веб-сервера Nginx + php5-fpm + mysql
Подготовьте сервер и настройте сайт на локальном хосте или на VPS.Установка nginx описана тут: http://help.ubuntu.ru/wiki/nginx-phpfpmУстановка mysql : http://help.ubuntu.ru/wiki/mysqlУстановка phpmyadmin : http://help.ubuntu.ru/wiki/%D1%80%D1%83%D0%BA%D0%BE%D0%B2%D0%BE%D0%B4%D1...
Далее продолжим подготовку сервера к работе с CppCMS.
Подробное руководство по установке предложено на русском: http://cppcms.com/wikipp/ru/page/cppcms_1x_build
Если у вас сложности с зависимостями и пакетами Убунту
Обязательные требования
Современный C++ компилятор -- GCC, MSVC 9, Intel. См. поддерживаемые компиляторы и платформыCMake 2.6 и выше, рекомендуется 2.8.x.Библиотека Zlib.Библиотека PCRE.Python >=2.4 (но не 3)
Всё это устанавливается так:
sudo apt-get install gcc g++ cmake zlib1g-dev libpcre3 libpcre3-dev python
Если не получается, тогда установите через центр приложений или Synaptic, в котором можно искать и добавлять необходимые библиотеки (часто имена библиотек подсказывают имя пакета, например, библиотека zlib доступна в пакете zlib1g-dev ).Для установки и запуска Synaptic:sudo apt-get install synapticsudo synaptic
Скачать и установить CppCMS
Тут http://sourceforge.net/projects/cppcms/files/ откройте папку cppcms и скачайте последнюю версию. На данный момент 1.0.5.
Распакуйте в папку вашего сайта.
Далее соберите проект и запустите как это предложено в руководстве:
http://cppcms.com/wikipp/ru/page/cppcms_1x_build
Разработчики фреймворка подготовили CMS для блога, которая называется CppBlog. Для старта проекта в Интернет можно начать с изучения CppBlog. Подробнее о CppBlog: http://cppcms.com/wikipp/en/page/install_cppblog
Тлито.ру будет публиковать демонстрационные статьи по разработке веб-сайтов с использованием CppCMS.
www.tlito.ru
НОУ ИНТУИТ | Лекция | Обзор методов клиентской оптимизации
Аннотация: В лекции рассматриваются цели клиентской оптимизации и инструменты ее измерения. Кроме того, в данной лекции перечисляются основные методы клиентской оптимизации и дается краткий обзор соответствующих технологий
1.1. Клиентская оптимизация
Клиентская оптимизация — это оптимизация процесса загрузки клиентским приложением содержимого веб-страниц. Основная цель такой оптимизации — достижение максимальной скорости загрузки страниц сайта браузером клиента, ведь даже незначительные изменения времени загрузки могут иметь серьезные последствия для задачи, возложенной на сайт.
При построении высокопроизводительных сайтов должен присутствовать и клиентский, и серверный подход, они во многом дополняют друг друга. Главное отличие клиентского подхода состоит в том, что в качестве объекта оптимизации рассматриваются страницы сайта, получаемые браузером клиента, состоящие из HTML-документа, содержащего вызовы внешних объектов, а также сами внешние объекты (чаще всего это файлы CSS, файлы JavaScript и изображения).
Может показаться, что клиентская оптимизация является лишь составляющей частью серверной оптимизации, однако это не так. Различные технологические решения клиентской области сайта при одинаковой нагрузке на сервер могут обеспечивать совершенно разные характеристики клиентского быстродействия.
При исключении из рассмотрения всех факторов, относящихся к серверному программному обеспечению и каналу передачи данных, можно заключить, что увеличение скорости загрузки страницы на различных стадиях загрузки принципиально возможно за счет ограниченного количества методов. Об этих методах и пойдет речь далее.
1.2. Анализ веб-страниц
Большинство приведенных в курсе методов оптимизации являются универсальными и могут быть применены практически в любом случае, на любом сайте. Но только выбор наиболее подходящего плана оптимизации может привести к наилучшему результату при решении каждой конкретной задачи.
Перед оптимизацией сайта необходим тщательный анализ его клиентской производительности, а также четко сформулированная цель оптимизации, ведь в подобном усовершенствовании важен только результат, а не процесс.
Процедуру анализа веб-сайта можно разделить на несколько основных стадий: анализ веб-страниц и их компонентов, анализ стадий загрузки веб-страниц и анализ характеристик браузеров, при помощи которых веб-страницы обычно загружаются.
1.2.1. Определение цели оптимизации
Целью клиентской оптимизации может быть решение подобных задач:
- достижение минимально возможного времени загрузки какой-либо конкретной страницы;
- достижение минимально возможного времени загрузки группы страниц, просматриваемых в произвольном порядке;
- обеспечение минимально возможного времени с момента запроса страницы до момента появления у пользователя возможности просматривать страницу и взаимодействовать с ней.
Это далеко не полный перечень возможных целей. Иногда и вовсе требуется достигать компромисса и выбирать между несколькими взаимо-исключающими вариантами оптимизации. В таких ситуациях лучше иметь максимум возможной информации о ваших веб-сайтах и их посетителях.

Определить список "критических" страниц, на которых необходим максимальный эффект оптимизации, можно при помощи систем сбора и анализа статистики. Необходимо также учитывать назначение и специфику оптимизируемого сайта или сервиса.
Как правило, оптимизация требуется на главной странице сайта и других страницах с высокой посещаемостью, но это не всегда так. В качестве примера можно привести страницы оформления заказа на коммерческом сайте. На них может приходить лишь 5% от общего числа посетителей сайта, однако если они будут загружаться слишком медленно, посетители могут так и не стать клиентами.
Google Analytics http://www.google.com/analytics/
Google Analytics — один из лучших среди бесплатных сервисов для сбора и анализа статистики. С его помощью можно узнать о посетителях сайта почти все: страницы, с которых они переходили на сайт, время и длительность посещений, наиболее посещаемые страницы и последовательности посещений, параметры программного и аппаратного обеспечения и т. п.
Сервис работает по тому же принципу, что и большинство Интернет-счетчиков: специальный код устанавливается на всех страницах сайта и регистрирует каждое посещение, собирая все данные о нем.
Яндекс.Метрика (http://metrika.yandex.ru/)
Относительно молодой, но активно развивающийся русскоязычный сервис для оценки посещаемости сайтов и анализа поведения пользователей на нем. Позволяет получить детальную информацию об источниках перехода на сайт, числе возвратов, просматриваемом содержимом, географии и демографии посещений, программных и аппаратных характери-тиках компьютеров пользователей.
Для сбора всей упомянутой выше информации достаточно лишь установить определенный код на всех страницах анализируемого сайта.
1.2.2. Анализ заголовков, компонентов и стадий загрузки страницы
Firebug (http://getfirebug.com/)
Одним из наиболее популярных среди веб-разработчиков средств для анализа и разработки веб-страниц является дополнение Firebug для браузера Firefox.
Панель Net в дополнении Firebug позволяет получить весьма де-тальную диаграмму загрузки страницы. По диаграмме можно опреде-лить стадии загрузки страницы, понять порядок загрузки объектов и выяснить, какие объекты блокируют, замедляют загрузку страницы. Кроме того, на этой панели можно получить детальную информацию о размере и заголовках самого документа, а также всех загруженных внешних объектов.
Firebug также позволяет изменять DOM-дерево и CSS-свойства страницы без ее перезагрузки, сразу отражая результат изменений на странице, а также предоставляет обширные возможности для отладки и профилирования кода JavaScript. Все эти возможности являются прекрасным подспорьем во время работ по оптимизации сайта.
Стоит заметить, что аналогичные Firebug инструменты существуют во всех широко распространенных браузерах. В браузере Safari схожей
функциональностью обладает надстройка Web Inspector, в Opera Dragonfly, в Internet Explorer — Developer Toolbar.
LiveHTTPHeaders (http://livehttpheaders.mozdev.org/)
Дополнение LiveHTTPHeaders для Firefox позволяет в режиме реального времени получать исчерпывающую информацию о пересылаемых между браузером и сервером заголовках. Кроме того, в этом дополнении существует режим Replay, позволяющий отправлять на сервер произвольные запросы GET или POST, что часто бывает удобно при разработке.
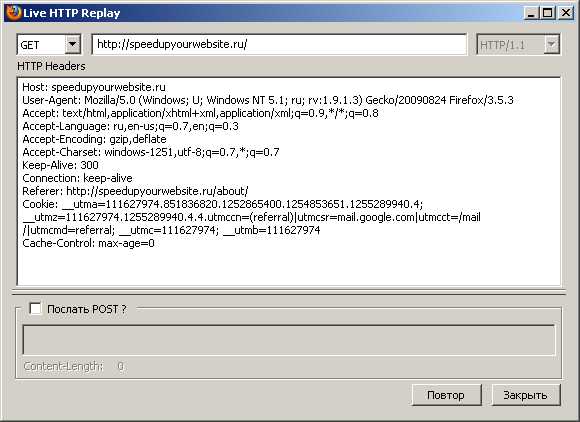 Рис. 1.4. Режим ручной отправки запроса в дополнении LiveHTTPHeaders
Рис. 1.4. Режим ручной отправки запроса в дополнении LiveHTTPHeadersYSlow (http://developer.yahoo.com/yslow/)
Дополнение YSlow для Firefox позволяет легко определить общее количество объектов, из которых состоит веб-страница, а также понять соотношения между объектами различного типа. В списке, содержащем перечень всех загруженных на странице объектов, предоставляется детальная информация по каждому такому объекту: размер, наличие сжатия, размер cookie, заголовки, время отклика и др.
HTTPWatch (http://www.httpwatch.com/)
Более мощным средством для получения информации о составе и ходе загрузки веб-страниц является приложение HTTPWatch. Это приложение устанавливается в виде дополнений к браузерам Firefox и Internet Explorer и предоставляет более полную и более точную информацию, чем Firebug. В HTTPWatch поддерживаются любые виды сжатия, поддерживается протокол HTTPS, учитываются редиректы, есть возможность составления отчетов, фильтрации данных, просмотра любых заголовков, cookie, данных POST-запросов и многое другое. HTTPWatch можно использовать бесплатно, но только в базовой редакции, с достаточно ограниченным набором возможностей.
Hammerhead (http://stevesouders.com/hammerhead/)
Небольшое дополнение к браузеру Firefox под названием Hammerhead позволяет имитировать многократную последовательную загрузку набора заданных страниц. Число попыток может быть установлено пользователем. Как результат работы дополнение отображает среднее время полной загрузки каждой испытуемой страницы. Дополнение позволяет очищать кэш после каждой загрузки для имитации обоих случаев: когда пользователь загружает страницу впервые или загружает ее повторно.
www.intuit.ru
Клиентская и серверная оптимизация: сходство и различия
Клиентская оптимизация оперирует двумя основными принципами: меньше данных и меньше соединений. Но именно эти принципы помогают уменьшить нагрузку на сам сервер. Давайте посмотрим, как это происходит и как перенести часть серверной нагрузки на клиентский браузер.
Кэширование во главу угла
Сервер может управлять состоянием кэша клиентского браузера, во-первых, через заголовок Cache-Control (и его атрибуты max-age, pre-check, post-check), который может указывать на промежуток времени, в течение которого соответствующий файл следует хранить на диске и не запрашивать с сервера. Рекомендуется для всех статических файлов выставлять максимальное время жизни кэша и форсировать его обновление у пользователя через изменение URL ресурса (с помощью RewriteRule либо GET-параметра). Во-вторых, состоянием клиентского кэша можно управлять через заголовки ETag и Last-Modified, которые ставят в соответствие каждому файлу уникальный идентификатор, изменяющийся при изменении файла, — своеобразная цифровая подпись или хэш. При этом серверу нужно не пересылать файл заново, а лишь ответить статус-кодом 304 на запрос браузера, если файл не изменился с момента последнего запроса. В итоге сам файл не пересылается, соединение (и сокет) освобождается быстрее, и ресурсы сервера также экономятся. Подробнее о кэшировании рассказывается в третьей главе.
Меньше запросов — легче серверу
Используя объединение файлов, мы не заставляем сервер обмениваться с браузером заголовками для передачи, например, нескольких таблиц стилей — гораздо экономичнее будет их объединить в одну. При этом браузер быстрее получит всю необходимую информацию и быстрее освободит такой важный ресурс, как соединение. Наряду с объединением текстовых файлов не стоит пренебрегать и объединением картинок. Если учитывать, что современные браузеры могут устанавливать несколько десятков одновременных соединений с сервером для получения статических файлов (и 80% из них — это именно картинки), то экономия от использования CSS Sprites, Image Map или data:URI подхода рассчитывается очень просто. В некоторых случаях удается уменьшить число соединений браузера с сервером для загрузки одной HTML-страницы в 8-10 раз. Объединение файлов рассматривается в четвертой главе.
Архивировать и кэшировать на сервере
Как показали проведенные исследования, gzip-сжатие текстового файла «на лету» в 95-98% случаев позволяет сократить время на передачу файла браузеру. Если хранить архивированные копии файлов на сервере (в памяти proxy-сервера или просто на диске), то соединение в общем случае удается освободить в 3-4 раза быстрее. В случае высоконагруженных серверов с динамическими HTML-файлами gzip также может быть применим. Здесь стоит ориентироваться на минимальную степень сжатия, ибо процессорные издержки при этом растут линейно, а размер уменьшается лишь логарифмически. О сжатии рассказывает следующая глава.
Кто у кого на службе?
После проведенного обзора технологий может показаться, что клиентская оптимизация является лишь составляющей частью серверной. Однако это не так. И клиентский, и серверный подход должен присутствовать при построении высокопроизводительных веб-приложений. В этом случае можно говорить о пересекающейся области ответственности, но никак не о превалировании одной логики над другой. Когда дело доходит до взаимодействия клиент-сервер, нужно помнить обо всех аспектах оптимизации. И у клиентской составляющей есть своя, выделанная, область ответственности. Она находится в окне браузера — это веб-страница, которая загружается у пользователя и с которой он взаимодействует.
www.cwpro.ru