Как редактировать файл robots txt. В файле robots txt не задана директива host wordpress
Файл robots.txt и мета-тег robots — настройка индексации сайта Яндексом и Гуглом, правильный роботс и его проверка
Обновлено: 24 июня 2018
При самостоятельном продвижении и раскрутке сайта важно не только создание уникального контента или подбор запросов в статистике Яндекса, но и так же следует уделять должное внимание такому показателю, как индексация ресурса поисковиками, ибо от этого тоже зависит весь дальнейший успех продвижения.
У нас с вами имеются в распоряжении два набора инструментов, с помощью которых мы можем управлять этим процессом как бы с двух сторон. Во-первых, существует такой важный инструмент как карта сайта (Sitemap xml). Она говорит поисковикам о том, какие страницы сайта подлежат индексации и как давно они обновлялись.

А, во-вторых, это, конечно же, файл robots.txt и похожий на него по названию мета-тег роботс, которые помогают нам запретить индексирование на сайте того, что не содержит основного контента (исключить файлы движка, запретить индексацию дублей контента), и именно о них и пойдет речь в этой статье...
Индексация сайта
Упомянутые выше инструменты очень важны для успешного развития вашего проекта, и это вовсе не голословное утверждение. В статье про Sitemap xml (см. ссылку выше) я приводил в пример результаты очень важного исследования по наиболее частым техническим ошибкам начинающих вебмастеров, там на втором и третьем месте (после не уникального контента) находятся как раз отсутствие этих файлов роботс и сайтмап, либо их неправильное составление и использование.
Почему так важно управлять индексацией сайта
Надо очень четко понимать, что при использовании CMS (движка) не все содержимое сайта должно быть доступно роботам поисковых систем. Почему?
- Ну, хотя бы потому, что, потратив время на индексацию файлов движка вашего сайта (а их может быть тысячи), робот поисковика до основного контента сможет добраться только спустя много времени. Дело в том, что он не будет сидеть на вашем ресурсе до тех пор, пока его полностью не занесет в индекс. Есть лимиты на число страниц и исчерпав их он уйдет на другой сайт. Адьес.
- Если не прописать определенные правила поведения в роботсе для этих ботов, то в индекс поисковиков попадет множество страниц, не имеющих отношения к значимому содержимому ресурса, а также может произойти многократное дублирование контента (по разным ссылкам будет доступен один и тот же, либо сильно пересекающийся контент), что поисковики не любят.
Хорошим решением будет запрет всего лишнего в robots.txt (все буквы в названии должны быть в нижнем регистре — без заглавных букв). С его помощью мы сможем влиять на процесс индексации сайта Яндексом и Google. Представляет он из себя обычный текстовый файл, который вы сможете создать и в дальнейшем редактировать в любом текстовом редакторе (например, Notepad++).
Поисковый бот будет искать этот файл в корневом каталоге вашего ресурса и если не найдет, то будет загонять в индекс все, до чего сможет дотянуться. Поэтому после написания требуемого роботса, его нужно сохранить в корневую папку, например, с помощью Ftp клиента Filezilla так, чтобы он был доступен к примеру по такому адресу:
Кстати, если вы хотите узнать как выглядит этот файл у того или иного проекта в сети, то достаточно будет дописать к Урлу его главной страницы окончание вида /robots.txt. Это может быть полезно для понимания того, что в нем должно быть.
Однако, при этом надо учитывать, что для разных движков этот файл будет выглядеть по-разному (папки движка, которые нужно запрещать индексировать, будут называться по-разному в разных CMS). Поэтому, если вы хотите определиться с лучшим вариантом роботса, допустим для Вордпресса, то и изучать нужно только блоги, построенные на этом движке (и желательно имеющие приличный поисковый трафик).
Как можно запретить индексацию отдельных частей сайта и контента?
Прежде чем углубляться в детали написания правильного файла robots.txt для вашего сайта, забегу чуть вперед и скажу, что это лишь один из способов запрета индексации тех или иных страниц или разделов вебсайта. Вообще их три:
- Роботс.тхт — самый высокоуровневый способ, ибо позволяет задать правила индексации для всего сайта целиком (как его отдельный страниц, так и целых каталогов). Он является полностью валидным методом, поддерживаемым всеми поисковиками и другими ботами живущими в сети. Но его директивы вовсе не являются обязательными для исполнения. Например, Гугл не шибко смотрит на запреты в robots.tx — для него авторитетнее одноименный мета-тег рассмотренный ниже.
- Мета-тег robots — имеет влияние только на страницу, где он прописан. В нем можно запретить индексацию и переход робота по находящимся в этом документе ссылкам (подробнее смотрите ниже). Он тоже является полностью валидным и поисковики будут стараться учитывать указанные в нем значения. Для Гугла, как я уже упоминал, этот метод имеет больший вес, чем файлик роботса в корне сайта.
- Тег Noindex и атрибут rel="nofollow" — самый низкоуровневый способ влияния на индексацию. Они позволяют закрыть от индексации отдельные фрагменты текста (noindex) и не учитывать вес передаваемый по ссылке. Они не валидны (их нет в стандартах). Как именно их учитывают поисковики и учитывают ли вообще — большой вопрос и предмет долгих споров (кто знает наверняка — тот молчит и пользуется).
Важно понимать, что даже «стандарт» (валидные директивы robots.txt и одноименного мета-тега) являются необязательным к исполнению. Если робот «вежливый», то он будет следовать заданным вами правилам. Но вряд ли вы сможете при помощи такого метода запретить доступ к части сайта роботам, ворующим у вас контент или сканирующим сайт по другим причинам.
Вообще, роботов (ботов, пауков, краулеров) существует множество. Какие-то из них индексируют контент (как например, боты поисковых систем или воришек). Есть боты проверяющие ссылки, обновления, зеркалирование, проверяющие микроразметку и т.д. Смотрите сколько роботов есть только у Яндекса.
Большинство роботов хорошо спроектированы и не создают каких-либо проблем для владельцев сайтов. Но если бот написан дилетантом или «что-то пошло не так», то он может создавать существенную нагрузку на сайт, который он обходит. Кстати, пауки вовсе на заходят на сервер подобно вирусам — они просто запрашивают нужные им страницы удаленно (по сути это аналоги браузеров, но без функции просмотра страниц).
Robots.txt — директива user-agent и боты поисковых систем
Роботс.тхт имеет совсем не сложный синтаксис, который очень подробно описан, например, в хелпе яндекса и хелпе Гугла. Обычно в нем указывается, для какого поискового бота предназначены описанные ниже директивы: имя бота ('User-agent'), разрешающие ('Allow') и запрещающие ('Disallow'), а также еще активно используется 'Sitemap' для указания поисковикам, где именно находится файл карты.
Стандарт создавался довольно давно и что-то было добавлено уже позже. Есть директивы и правила оформления, которые будут понятны только роботами определенных поисковых систем. В рунете интерес представляют в основном только Яндекс и Гугл, а значит именно с их хелпами по составлению robots.txt следует ознакомиться особо детально (ссылки я привел в предыдущем абзаце).
Например, раньше для поисковой системы Яндекс было полезным указать, какое из зеркал вашего вебпроекта является главным в специальной директиве 'Host', которую понимает только этот поисковик (ну, еще и Майл.ру, ибо у них поиск от Яндекса). Правда, в начале 2018 Яндекс все же отменил Host и теперь ее функции как и у других поисковиков выполняет 301-редирект.
Если даже у вашего ресурса нет зеркал, то полезно будет указать, какой из вариантов написания является главным - с www или без него.
Теперь поговорим немного о синтаксисе этого файла. Директивы в robots.txt имеют следующий вид:
<поле>:<пробел><значение><пробел> <поле>:<пробел><значение><пробел>Правильный код должен содержать хотя бы одну директиву «Disallow» после каждой записи «User-agent». Пустой файл предполагает разрешение на индексирование всего сайта.
User-agent
Директива «User-agent» должна содержать название поискового бота. При помощи нее можно настроить правила поведения для каждого конкретного поисковика (например, создать запрет индексации отдельной папки только для Яндекса). Пример написания «User-agent», адресованной всем ботам зашедшим на ваш ресурс, выглядит так:
User-agent: *Если вы хотите в «User-agent» задать определенные условия только для какого-то одного бота, например, Яндекса, то нужно написать так:
User-agent: YandexНазвание роботов поисковых систем и их роль в файле robots.txt
Бот каждой поисковой системы имеет своё название (например, для рамблера это StackRambler). Здесь я приведу список самых известных из них:
У крупных поисковых систем иногда, кроме основных ботов, имеются также отдельные экземпляры для индексации блогов, новостей, изображений и т.д. Много информации по разновидностям ботов вы можете почерпнуть тут (для Яндекса) и тут (для Google).
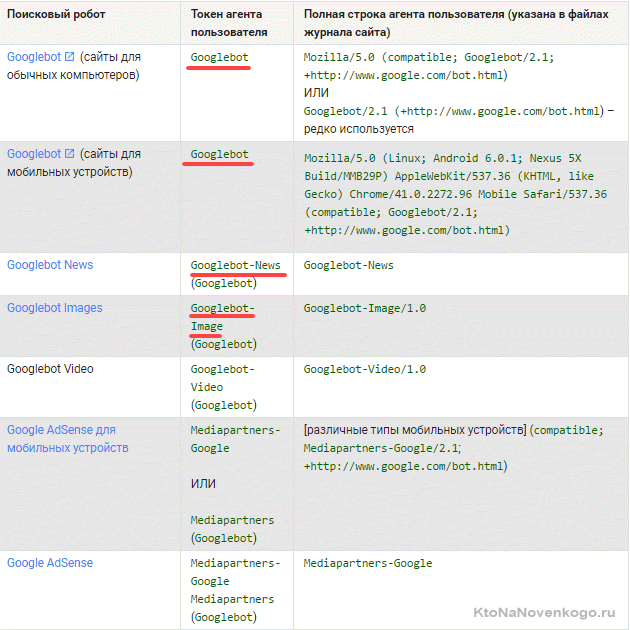
Как быть в этом случае? Если нужно написать правило запрета индексации, которое должны выполнить все типы роботов Гугла, то используйте название Googlebot и все остальные пауки этого поисковика тоже послушаются. Однако, можно запрет давать только, например, на индексацию картинок, указав в качестве User-agent бота Googlebot-Image. Сейчас это не очень понятно, но на примерах, я думаю, будет проще.
Примеры использования директив Disallow и Allow в роботс.тхт
- Приведенный ниже код разрешает всем ботам (на это указывает звездочка в User-agent) проводить индексацию всего содержимого без каких-либо исключений. Это задается пустой директивой Disallow. User-agent: * Disallow:
- Следующий код, напротив, полностью запрещает всем поисковикам добавлять в индекс страницы этого ресурса. Устанавливает это Disallow с «/» в поле значения. User-agent: * Disallow: /
- В этом случае будет запрещаться всем ботам просматривать содержимое каталога /image/ (http://mysite.ru/image/ — абсолютный путь к этому каталогу) User-agent: * Disallow: /image/
- Чтобы заблокировать один файл, достаточно будет прописать его абсолютный путь до него (читайте про абсолютные и относительные пути по ссылке): User-agent: * Disallow: /katalog1//katalog2/private_file.html
Забегая чуть вперед скажу, что проще использовать символ звездочки (*), чтобы не писать полный путь:
Disallow: /*private_file.html - В приведенном ниже примере будут запрещены директория «image», а также все файлы и директории, начинающиеся с символов «image», т. е. файлы: «image.htm», «images.htm», каталоги: «image», «images1», «image34» и т. д.): User-agent: * Disallow: /image Дело в том, что по умолчанию в конце записи подразумевается звездочка, которая заменяет любые символы, в том числе и их отсутствие. Читайте об этом ниже.
- С помощью директивы Allow мы разрешаем доступ. Хорошо дополняет Disallow. Например, таким вот условием поисковому роботу Яндекса мы запрещаем выкачивать (индексировать) все, кроме вебстраниц, адрес которых начинается с /cgi-bin: User-agent: Yandex Allow: /cgi-bin Disallow: /
Ну, или такой вот очевидный пример использования связки Allow и Disallow:
User-agent: * Disallow: /catalog Allow: /catalog/auto - При описании путей для директив Allow-Disallow можно использовать символы '*' и '$', задавая, таким образом, определенные логические выражения.
- Символ '*'(звездочка) означает любую (в том числе пустую) последовательность символов. Следующий пример запрещает всем поисковикам индексацию файлов с расширение «.php»: User-agent: * Disallow: *.php$
- Зачем нужен на конце знак $ (доллара)? Дело в том, что по логике составления файла robots.txt, в конце каждой директивы как бы дописывается умолчательная звездочка (ее нет, но она как бы есть). Например мы пишем: Disallow: /images
Т.е. это правило запрещает индексацию всех файлов (вебстраниц, картинок и других типов файлов) адрес которых начинается с /images, а дальше следует все что угодно (см. пример выше). Так вот, символ $ просто отменяет эту умолчательную (непроставляемую) звездочку на конце. Например:
Disallow: /images$Запрещает только индексацию файла /images, но не /images.html или /images/primer.html. Ну, а в первом примере мы запретили индексацию только файлов оканчивающихся на .php (имеющих такое расширение), чтобы ничего лишнего не зацепить:
Disallow: *.php$
Звездочка после вопросительного знака напрашивается, но она, как мы с вами выяснили чуть выше, уже подразумевается на конце. Таким образом мы запретим индексацию страниц поиска и прочих служебных страниц создаваемых движком, до которых может дотянуться поисковый робот. Лишним не будет, ибо знак вопроса чаще всего CMS используют как идентификатор сеанса, что может приводить к попаданию в индекс дублей страниц.
Директивы Sitemap и Host (для Яндекса) в Robots.txt
Во избежании возникновения неприятных проблем с зеркалами сайта, раньше рекомендовалось добавлять в robots.txt директиву Host, которая указывал боту Yandex на главное зеркало.
Однако, в начале 2018 год это было отменено и и теперь функции Host выполняет 301-редирект.
Директива Host — указывает главное зеркало сайта для Яндекса
Например, раньше, если вы еще не перешли на защищенный протокол, указывать в Host нужно было не полный Урл, а доменное имя (без http://, т.е. ktonanovenkogo.ru, а не https://ktonanovenkogo.ru). Если же уже перешли на https, то указывать нужно будет полный Урл (типа https://myhost.ru).
Сейчас переезд сайта после отказа от директивы Host очень сильно упростился, ибо теперь не нужно ждать пока произойдет склейка зеркал по директиве Host для Яндекса, а можно сразу после настройки Https на сайте делать постраничный редирект с Http на Https.
Напомню в качестве исторического экскурса, что по стандарту написания роботс.тхт за любой директивой User-agent должна сразу следовать хотя бы одна директива Disallow (пусть даже и пустая, ничего не запрещающая). Так же, наверное, имеется смысл прописывать Host для отдельного блока «User-agent: Yandex», а не для общего «User-agent: *», чтобы не сбивать с толку роботов других поисковиков, которые эту директиву не поддерживают:
User-agent: Yandex Disallow: Host: www.site.ruлибо
User-agent: Yandex Disallow: Host: site.ruлибо
User-agent: Yandex Disallow: Host: https://site.ruлибо
User-agent: Yandex Disallow: Host: https://www.site.ruв зависимости от того, что для вас оптимальнее (с www или без), а так же в зависимости от протокола.
Указываем или скрываем путь до карты сайта sitemap.xml в файле robots
Директива Sitemap указывает на местоположение файла карты сайта (обычно он называется Sitemap.xml, но не всегда). В качестве параметра указывается путь к этому файлу, включая http:// (т.е. его Урл).Благодаря этому поисковый робот сможете без труда его найти. Например:
Sitemap: http://site.ru/sitemap.xmlРаньше файл карты сайта хранили в корне сайта, но сейчас многие его прячут внутри других директорий, чтобы ворам контента не давать удобный инструмент в руки. В этом случае путь до карты сайта лучше в роботс.тхт не указывать. Дело в том, что это можно с тем же успехом сделать через панели поисковых систем (Я.Вебмастер, Google.Вебмастер, панель Майл.ру), тем самым «не паля» его местонахождение.
Местоположение директивы Sitemap в файле robots.txt не регламентируется, ибо она не обязана относиться к какому-то юзер-агенту. Обычно ее прописывают в самом конце, либо вообще не прописывают по приведенным выше причинам.
Проверка robots.txt в Яндекс и Гугл вебмастере
Как я уже упоминал, разные поисковые системы некоторые директивы могут интерпритировать по разному. Поэтому имеет смысл проверять написанный вами файл роботс.тхт в панелях для вебмастеров обоих систем. Как проверять?
- Зайти в инструменты проверки Яндекса и Гугла.
- Убедиться, что в панель вебмастера загружена версия файла с внесенными вами изменениями. В Яндекс вебмастере загрузить измененный файл можно с помощью показанной на скриншоте иконки:

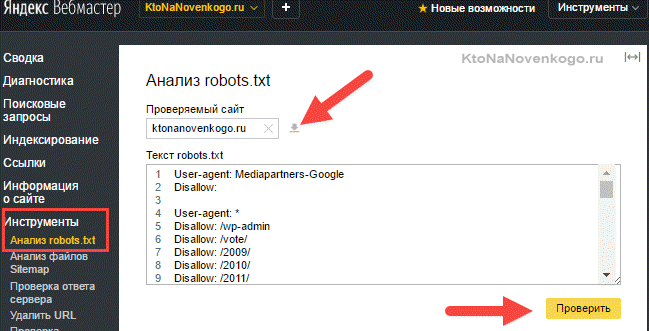
В Гугл Вебмастере нужно нажать кнопку «Отправить» (справа под списком директив роботса), а затем в открывшемся окне выбрать последний вариант нажатием опять же на кнопку «Отправить»:
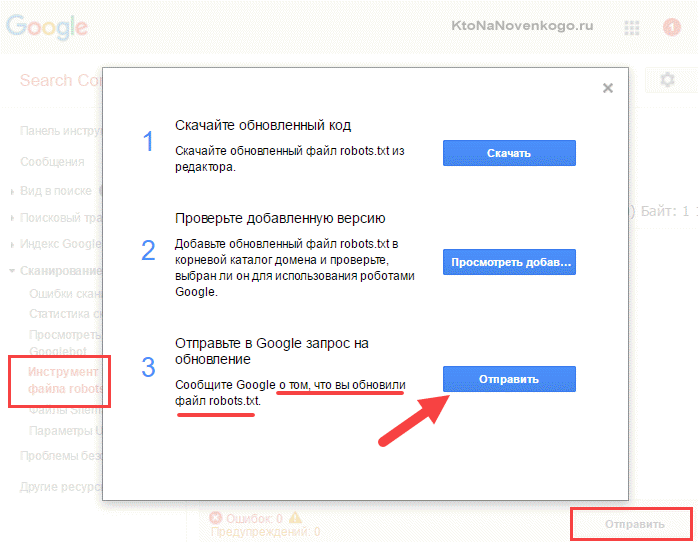
- Набрать список адресов страниц своего сайта (по Урлу в строке), которые должны индексироваться, и вставить их скопом (в Яндексе) или по одному (в Гугле) в расположенную снизу форму. После чего нажать на кнопку «Проверить».
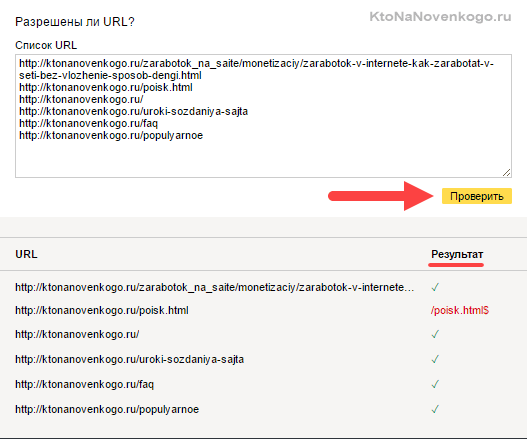
Если возникли нестыковки, то выяснить причины, внести изменения в robots.txt, загрузить обновленный файл в панель вебмастеров и повторить проверку. Все ОК?
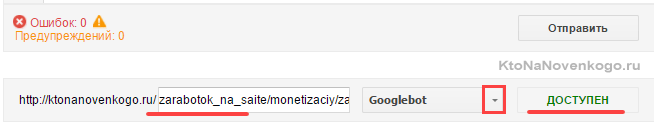 Тогда составляйте список страниц, которые не должны индексироваться, и проводите их проверку. При необходимости вносите изменения и проверку повторяйте. Естественно, что проверять следует не все страницы сайта, а ярких представителей своего класса (страницы статей, рубрики, служебные страницы, файлы картинок, файлы шаблона, файлы движка и т.д.)
Тогда составляйте список страниц, которые не должны индексироваться, и проводите их проверку. При необходимости вносите изменения и проверку повторяйте. Естественно, что проверять следует не все страницы сайта, а ярких представителей своего класса (страницы статей, рубрики, служебные страницы, файлы картинок, файлы шаблона, файлы движка и т.д.)
Причины ошибок выявляемых при проверке файла роботс.тхт
- Файл должен находиться в корне сайта, а не в какой-то папке (это не .htaccess, и его действия распространяются на весь сайт, а не на каталог, в котором его поместили), ибо поисковый робот его там искать не будет.
- Название и расширение файла robots.txt должно быть набрано в нижнем регистре (маленькими) латинскими буквами.
- В названии файла должна быть буква S на конце (не robot.txt, как многие пишут)
- Часто в User-agent вместо звездочки (означает, что этот блок robots.txt адресован всем ботам) оставляют пустое поле. Это не правильно и * в этом случае обязательна User-agent: * Disallow: /
- В одной директиве Disallow или Allow можно прописывать только одно условие на запрет индексации директории или файла. Так нельзя: Disallow: /feed/ /tag/ /trackback/
Для каждого условия нужно добавить свое Disallow:
Disallow: /feed/ Disallow: /tag/ Disallow: /trackback/ - Довольно часто путают значения для директив и пишут: User-agent: / Disallow: Yandex
вместо
User-agent: Yandex Disallow: / - Порядок следования Disallow (Allow) не важен — главное, чтобы была четкая логическая цепь
- Пустая директива Disallow означает то же, что «Allow: /»
- Нет смысла прописывать директиву sitemap под каждым User-agent, если будете указывать путь до карты сайта (читайте об этом ниже), то делайте это один раз, например, в самом конце.
- Директиву Host лучше писать под отдельным «User-agent: Yandex», чтобы не смущать ботов ее не поддерживающих
Мета-тег Robots — помогает закрыть дубли контента при индексации сайта
Существует еще один способ настроить (разрешить или запретить) индексацию отдельных страниц вебсайта, как для Яндекса, так и для Гугл. Причем для Google этот метод гораздо приоритетнее описанного выше. Поэтому, если нужно наверняка закрыть страницу от индексации этой поисковой системой, то данный мета-тег нужно будет прописывать в обязательном порядке.
Для этого внутри тега «HEAD» нужной вебстраницы дописывается МЕТА-тег Robots с нужными параметрами, и так повторяется для всех документов, к которым нужно применить то или иное правило (запрет или разрешение). Выглядеть это может, например, так:
<html> <head> <meta name="robots" content="noindex,nofollow"> <meta name="description" content="Эта страница ...."> <title>...</title> </head> <body> ...В этом случае, боты всех поисковых систем должны будут забыть об индексации этой вебстраницы (об этом говорит присутствие noindex в данном мета-теге) и анализе размещенных на ней ссылок (об этом говорит присутствие nofollow — боту запрещается переходить по ссылкам, которые он найдет в этом документе).
Существуют только две пары параметров у метатега robots: [no]index и [no]follow:
- Index — указывают, может ли робот проводить индексацию данного документа
- Follow — может ли он следовать по ссылкам, найденным в этом документе
Значения по умолчанию (когда этот мета-тег для страницы вообще не прописан) – «index» и «follow». Есть также укороченный вариант написания с использованием «all» и «none», которые обозначают активность обоих параметров или, соответственно, наоборот: all=index,follow и none=noindex,nofollow.
Более подробные объяснения можно найти, например, в хелпе Яндекса:
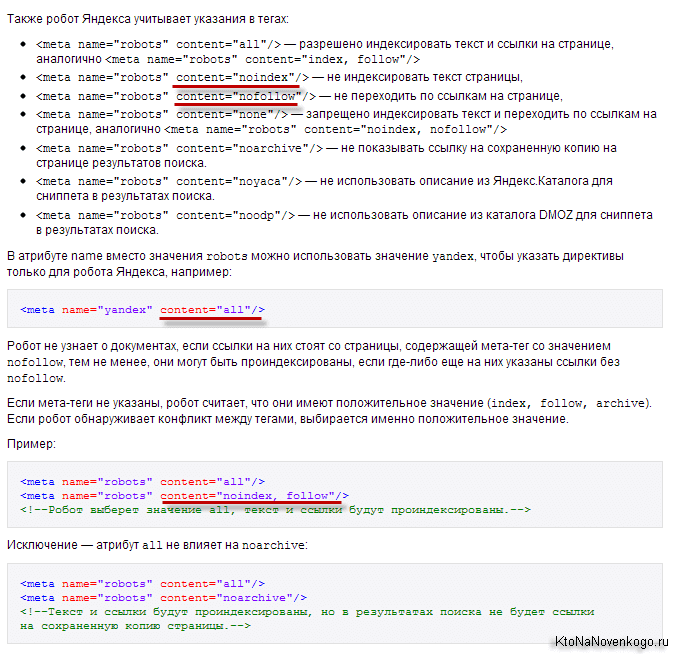
Для блога на WordPress вы сможете настроить мета-тег Robots, например, с помощью плагина All in One SEO Pack. Если используете другие плагины или другие движки сайта, то гуглите на тему прописывания для нужных страниц meta name="robots".
Как создать правильный роботс.тхт?
Ну все, с теорией покончено и пора переходить к практике, а именно к составлению оптимальных robots.txt. Как известно, у проектов, созданных на основе какого-либо движка (Joomla, WordPress и др), имеется множество вспомогательных объектов не несущих никакой информативной нагрузки.
Если не запретить индексацию всего этого мусора, то время, отведенное поисковиками на индексацию вашего сайта, будет тратиться на перебор файлов движка (на предмет поиска в них информационной составляющей, т.е. контента). Но фишка в том, что в большинстве CMS контент хранится не в файликах, а в базе данных, к которой поисковым ботам никак не добраться. Полазив по мусорным объектам движка, бот исчерпает отпущенное ему время и уйдет не солоно хлебавши.
Кроме того, следует стремиться к уникальности контента на своем проекте и не следует допускать полного или даже частичного дублирования контента (информационного содержимого). Дублирование может возникнуть в том случае, если один и тот же материал будет доступен по разным адресам (URL).
Яндекс и Гугл, проводя индексацию, обнаружат дубли и, возможно, примут меры к некоторой пессимизации вашего ресурса при их большом количестве (машинные ресурсы стоят дорого, а посему затраты нужно минимизировать). Да, есть еще такая штука, как мета-тэг Canonical.
Замечательный инструмент для борьбы с дублями контента — поисковик просто не будет индексировать страницу, если в Canonical прописан другой урл. Например, для такой страницы https://ktonanovenkogo.ru/page/2 моего блога (страницы с пагинацией) Canonical указывает на https://ktonanovenkogo.ru и никаких проблем с дублированием тайтлов возникнуть не должно.
<link rel="canonical" href="https://ktonanovenkogo.ru/" />Но это я отвлекся...
Если ваш проект создан на основе какого-либо движка, то дублирование контента будет иметь место с высокой вероятностью, а значит нужно с ним бороться, в том числе и с помощью запрета в robots.txt, а особенно в мета-теге, ибо в первом случае Google запрет может и проигнорировать, а вот на метатег наплевать он уже не сможет (так воспитан).
Например, в WordPress страницы с очень похожим содержимым могут попасть в индекс поисковиков, если разрешена индексация и содержимого рубрик, и содержимого архива тегов, и содержимого временных архивов. Но если с помощью описанного выше мета-тега Robots создать запрет для архива тегов и временного архива (можно теги оставить, а запретить индексацию содержимого рубрик), то дублирования контента не возникнет. Как это сделать описано по ссылке приведенной чуть выше (на плагин ОлИнСеоПак)
Подводя итог скажу, что файл Роботс предназначен для задания глобальных правил запрета доступа в целые директории сайта, либо в файлы и папки, в названии которых присутствуют заданные символы (по маске). Примеры задания таких запретов вы можете посмотреть чуть выше.
Теперь давайте рассмотрим конкретные примеры роботса, предназначенного для разных движков — Joomla, WordPress и SMF. Естественно, что все три варианта, созданные для разных CMS, будут существенно (если не сказать кардинально) отличаться друг от друга. Правда, у всех у них будет один общий момент, и момент этот связан с поисковой системой Яндекс.
Т.к. в рунете Яндекс имеет достаточно большой вес, то нужно учитывать все нюансы его работы, и тут нам поможет директива Host. Она в явной форме укажет этому поисковику главное зеркало вашего сайта.
Для нее советуют использовать отдельный блог User-agent, предназначенный только для Яндекса (User-agent: Yandex). Это связано с тем, что остальные поисковые системы могут не понимать Host и, соответственно, ее включение в запись User-agent, предназначенную для всех поисковиков (User-agent: *), может привести к негативным последствиям и неправильной индексации.
Как обстоит дело на самом деле — сказать трудно, ибо алгоритмы работы поиска — это вещь в себе, поэтому лучше сделать так, как советуют. Но в этом случае придется продублировать в директиве User-agent: Yandex все те правила, что мы задали User-agent: *. Если вы оставите User-agent: Yandex с пустым Disallow:, то таким образом вы разрешите Яндексу заходить куда угодно и тащить все подряд в индекс.
Robots для WordPress
Не буду приводить пример файла, который рекомендуют разработчики. Вы и сами можете его посмотреть. Многие блогеры вообще не ограничивают ботов Яндекса и Гугла в их прогулках по содержимому движка WordPress. Чаще всего в блогах можно встретить роботс, автоматически заполненный плагином Google XML Sitemaps.
Но, по-моему, все-таки следует помочь поиску в нелегком деле отсеивания зерен от плевел. Во-первых, на индексацию этого мусора уйдет много времени у ботов Яндекса и Гугла, и может совсем не остаться времени для добавления в индекс вебстраниц с вашими новыми статьями. Во-вторых, боты, лазящие по мусорным файлам движка, будут создавать дополнительную нагрузку на сервер вашего хоста, что не есть хорошо.
Мой вариант этого файла вы можете сами посмотреть. Он старый, давно не менялся, но я стараюсь следовать принципу «не чини то, что не ломалось», а вам уже решать: использовать его, сделать свой или еще у кого-то подсмотреть. У меня там еще запрет индексации страниц с пагинацией был прописан до недавнего времени (Disallow: */page/), но недавно я его убрал, понадеясь на Canonical, о котором писал выше.
А вообще, единственно правильного файла для WordPress, наверное, не существует. Можно, кончено же, реализовать в нем любые предпосылки, но кто сказал, что они будут правильными. Вариантов идеальных robots.txt в сети много.
Приведу две крайности:
- Тут можно найти мегафайлище с подробными пояснениями (символом # отделяются комментарии, которые в реальном файле лучше будет удалить): User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS # то пишем протокол, если нужно указать порт, указываем). Команду Host понимает # Яндекс и Mail.RU, Google не учитывает. Host: www.site.ru
- А вот тут можно взять на вооружение пример минимализма: User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Host: https://site.ru Sitemap: https://site.ru/sitemap.xml
Истина, наверное, лежит где-то посредине. Еще не забудьте прописать мета-тег Robots для «лишних» страниц, например, с помощью чудесного плагина — All in One SEO Pack. Он же поможет и Canonical настроить.
Правильный robots.txt для Joomla
Рекомендованный файл для Джумлы 3 выглядит так (живет он в файле robots.txt.dist корневой папки движка):
User-agent: * Disallow: /administrator/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/В принципе, здесь практически все учтено и работает он хорошо. Единственное, в него следует добавить отдельное правило User-agent: Yandex для вставки директивы Host, определяющей главное зеркало для Яндекса, а так же указать путь к файлу Sitemap.
Поэтому в окончательном виде правильный robots для Joomla, по-моему мнению, должен выглядеть так:
User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /layouts/ Disallow: /cli/ Disallow: /bin/ Disallow: /logs/ Disallow: /components/ Disallow: /component/ Disallow: /component/tags* Disallow: /*mailto/ Disallow: /*.pdf Disallow: /*% Disallow: /index.php Host: vash_sait.ru (или www.vash_sait.ru) User-agent: * Allow: /*.css?*$ Allow: /*.js?*$ Allow: /*.jpg?*$ Allow: /*.png?*$ Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /layouts/ Disallow: /cli/ Disallow: /bin/ Disallow: /logs/ Disallow: /components/ Disallow: /component/ Disallow: /*mailto/ Disallow: /*.pdf Disallow: /*% Disallow: /index.php Sitemap: http://путь к вашей карте XML форматаДа, еще обратите внимание, что во втором варианте есть директивы Allow, разрешающие индексацию стилей, скриптов и картинок. Написано это специально для Гугла, ибо его Googlebot иногда ругается, что в роботсе запрещена индексация этих файлов, например, из папки с используемой темой оформления. Даже грозится за это понижать в ранжировании.
Поэтому заранее все это дело разрешаем индексировать с помощью Allow. То же самое, кстати, и в примере файла для Вордпресс было.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Твитнуть
Поделиться
Плюсануть
Поделиться
Отправить
Класснуть
Линкануть
Вотсапнуть
Запинить
Подборки по теме:
Рубрика: Инструменты вебмастера, Как самому раскрутить сайтktonanovenkogo.ru
Файл robots.txt - настройка и директивы robots.txt, запрещаем индексацию страниц
Robots.txt – это служебный файл, который служит рекомендацией по ограничению доступа к содержимому веб-документов для поисковых систем. В данной статье мы разберем настройку Robots.txt, описание директив и составление его для популярных CMS.
Находится данный файл Робота в корневом каталоге вашего сайта и открывается/редактируется простым блокнотом, я рекомендую Notepad++. Для тех, кто не любит читать — есть ВИДЕО, смотрите в конце статьи 😉
- В чем его польза
- Директивы и правила написания
- Мета-тег Robots и его директивы
- Правильные роботсы для популярных CMS
- Проверка робота
- Видео-руководство
- Популярные вопросы
Зачем нужен robots.txt
Как я уже говорил выше – с помощью файла robots.txt мы можем ограничить доступ поисковых ботов к документам, т.е. мы напрямую влияем на индексацию сайта. Чаще всего закрывают от индексации:
- Служебные файлы и папки CMS
- Дубликаты
- Документы, которые не несут пользу для пользователя
- Не уникальные страницы
Разберем конкретный пример:
Интернет-магазин по продаже обуви и реализован на одной из популярных CMS, причем не лучшим образом. Я могу сразу сказать, что будут в выдаче страницы поиска, пагинация, корзина, некоторые файлы движка и т.д. Все это будут дубли и служебные файлы, которые бесполезны для пользователя. Следовательно, они должны быть закрыты от индексации, а если еще есть раздел «Новости» в которые копипастятся разные интересные статьи с сайтов конкурентов – то и думать не надо, сразу закрываем.
Поэтому обязательно получаемся файлом robots.txt, чтобы в выдачу не попадал мусор. Не забываем, что файл должен открываться по адресу http://site.ru/robots.txt.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом ЯндексаDisallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articlesРегулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/newДиректива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xmlДиректива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ruCrawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секундClean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрамиГлавное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2Мета-тег robots и как он прописывается
Данный вариант запрета страниц лучше учитывается поисковой системой Google. Яндекс одинаково хорошо учитывает оба варианта.
Директив у него 2: follow/nofollow и index/noindex. Это разрешение/запрет перехода по ссылкам и разрешение/запрет на индексацию документа. Директивы можно прописывать вместе, смотрим пример ниже.
Для любой отдельной страницы вы можете прописать в теге <head> </head> следующее:

Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
User-agent: Yandex Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: romanus.ru User-agent: * Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Sitemap: http://romanus.ru/sitemap.xmlТрэкбэки запрещаю потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильный robots для нужной CMS просто кликните по соответствующей ссылке.
Как проверить корректность работы файла
Анализ robots.txt в Яндекс Вебмастере – тут.

Указываем адрес своего сайта, нажимаем кнопку «Загрузить» (или вписываем его вручную) – бот качает ваш файл. Далее просто указываем нужные нам УРЛы в списке, которые мы хотим проверить и жмем «Проверить».
Смотрим и корректируем, если это нужно.
Популярные вопросы о robots.txt
Как закрыть сайт от индексации?
Как запретить индексацию страницы?
Как запретить индексацию зеркала?
Для магазина стоит закрывать cart (корзину)?
- Да, я бы закрывал.
У меня сайт без CMS, нужен ли мне robots?
- Да, чтобы указать Host и Sitemap. Если у вас есть дубли — то исходя из ситуации закрывайте их.
romanus.ru
Файл robots txt — основные директивы и инструкция по редактированию в Нубексе
Robots.txt — это текстовый файл, который содержит специальные инструкции для роботов-поисковиков, исследующих ваш сайт в интернете. Такие инструкции — они называются директивами — могут запрещать к индексации некоторые страницы сайта, указывать на правильное «зеркалирование» домена и т.д.
Для сайтов, работающих на платформе «Нубекс», файл с директивами создается автоматически и располагается по адресу domen.ru/robots.txt, где domen.ru — доменное имя сайта. Например, с содержанием файла для сайта nubex.ru можно ознакомиться по адресу nubex.ru/robots.txt.

Изменить robots.txt и прописать дополнительные директивы для поисковиков можно в админке сайта. Для этого на панели управления выберите раздел «Настройки», а в нем — пункт «SEO».

Найдите поле «Текст файла robots.txt» и пропишите в нем нужные директивы. Желательно активировать галочку «Добавить в robots.txt ссылку на автоматически генерируемый файл sitemap.xml»: так поисковый бот сможет загрузить карту сайта и найти все необходимые страницы для индексации.

Не забудьте сохранить страницу после внесения необходимых изменений.
Основные директивы для файла robots txt
Загружая robots.txt, поисковый робот первым делом ищет запись, начинающуюся с User-agent: значением этого поля должно являться имя робота, которому в этой записи устанавливаются права доступа. Т.е. директива User-agent — это своего рода обращение к роботу.
1. Если в значении поля User-agent указан символ «*», то заданные в этой записи права доступа распространяются на любых поисковых роботов, запросивших файл /robots.txt.

2. Если в записи указано более одного имени робота, то права доступа распространяются для всех указанных имен.

3. Заглавные или строчные символы роли не играют.

4. Если обнаружена строка User-agent: ИмяБота, директивы для User-agent: * не учитываются (это в том случае, если вы делаете несколько записей для различных роботов). Т.е. робот сначала просканирует текст на наличие записи User-agent: МоеИмя, и если найдет, будет следовать этим указаниям; если нет — будет действовать по инструкциям записи User-agent: * (для всех ботов).

Кстати, перед каждой новой директивой User-agent рекомендуется вставлять пустой перевод строки (Enter).
5. Если строки User-agent: ИмяБота и User-agent: * отсутствуют, считается, что доступ роботу не ограничен.

Запрет и разрешение индексации сайта: директивы Disallow и Allow
Чтобы запретить или разрешить поисковым ботам доступ к определенным страницам сайта, используются директивы Disallow и Allow соответственно.
В значении этих директив указывается полный или частичный путь к разделу:
- Disallow: /admin/ — запрещает индексацию всех страниц, находящихся внутри раздела admin;
- Disallow: /help — запрещает индексацию и /help.html, и /help/index.html;
- Disallow: /help/ — закрывает только /help/index.html;
- Disallow: / — блокирует доступ ко всему сайту.
Если значение Disallow не указано, то доступ не ограничен:
- Disallow: — разрешена индексация всех страниц сайта.
Для настройки исключений можно использовать разрешающую директиву Allow. Например, такая запись запретит роботам индексировать все разделы сайта, кроме тех, путь к которым начинается с /search:
User-agent: *
Allow: /search
Disallow: /
Неважно, в каком порядке будут перечислены директивы запрета и разрешения индексации. При чтении робот все равно рассортирует их по длине префикса URL (от меньшего к большему) и применит последовательно. То есть пример выше в восприятии бота будет выглядеть так:
User-agent: *
Disallow: /
Allow: /search
— разрешено индексировать только страницы, начинающиеся на /search. Таким образом, порядок следования директив никак не повлияет на результат.
Директива Host: как указать основной домен сайта
Если к вашему сайту привязано несколько доменных имен (технические адреса, зеркала и т.д.), поисковик может решить, что все это — разные сайты. Причем с одинаковым наполнением. Решение? В бан! И одному боту известно, какой из доменов будет «наказан» — основной или технический.

Чтобы избежать этой неприятности, нужно сообщить поисковому роботу, по какому из адресов ваш сайт участвует в поиске. Этот адрес будет обозначен как основной, а остальные сформируют группу зеркал вашего сайта.
Сделать это можно с помощью директивы Host. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы Host нужно указать основной домен с номером порта (по умолчанию 80). Например:
User-Agent: *
Disallow:
Host: test-o-la-la.ru
Такая запись означает, что сайт будет отображаться в результатах поиска со ссылкой на домен test-o-la-la.ru, а не www.test-o-la-la.ru и s10364.nubex.ru (см. скриншот выше).
В конструкторе «Нубекс» директива Host добавляется в текст файла robots.txt автоматически, когда вы указываете в админке, какой домен является основным.
В тексте robots.txt директива host может использоваться только единожды. Если вы пропишите ее несколько раз, робот воспримет только первую по порядку запись.
Директива Crawl-delay: как задать интервал загрузки страниц
Чтобы обозначить роботу минимальный интервал между окончанием загрузки одной страницы и началом загрузки следующей, используйте директиву Crawl-delay. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы укажите время в секундах.
User-Agent: *
Disallow:
Crawl-delay: 3
Использование такой задержки при обработке страниц будет удобным для перегруженных серверов.
Существуют также и другие директивы для поисковых роботов, но пяти описанных — User-Agent, Disallow, Allow, Host и Crawl-delay — обычно достаточно для составления текста файла robots.txt.
nubex.ru