Делаем правильный файл Robots.txt для WordPress. Robots wordpress
Правильный Robots.txt для Wordpress (2018) - как сделать?
В интернете можно найти много публикаций на тему, как составить лучший (или даже самый лучший) файл robots.txt для WordPress. При этом в ряде таких популярных статей многие правила не объясняются и, как мне кажется, вряд ли понимаются самими авторами. Единственный обзор, который я нашел и который действительно заслуживает внимания, — это статья в блоге wp-kama. Однако и там я нашел не совсем корректные рекомендации. Понятно, что на каждом сайте будут свои нюансы при составлении файла robots.txt. Но существует ряд общих моментов для совершенно разных сайтов, которые можно взять за основу. Robots.txt, опубликованный в этой статье, можно будет просто копировать и вставлять на новый сайт и далее дорабатывать в соответствии со своими нюансами.
Более подробно о составлении robots.txt и значении всех его директив я писал здесь. Ниже я не буду подробно останавливаться на значении каждого правила. Ограничусь тем, что кратко прокомментирую что для чего необходимо.
Правильный Robots.txt для WordPress
 Действительно самый лучший robots.txt, который я видел на данный момент, это роботс, предложенный в блоге wp-kama. Ряд директив и комментариев я возьму из его образца + внесу свои корректировки. Корректировки коснутся нескольких правил, почему так напишу ниже. Кроме того, напишем индивидуальные правила для всех роботов, для Яндекса и для Google.
Действительно самый лучший robots.txt, который я видел на данный момент, это роботс, предложенный в блоге wp-kama. Ряд директив и комментариев я возьму из его образца + внесу свои корректировки. Корректировки коснутся нескольких правил, почему так напишу ниже. Кроме того, напишем индивидуальные правила для всех роботов, для Яндекса и для Google.
Ошибочные рекомендации других блогеров для Robots.txt на WordPress

- Использовать правила только для User-agent: *Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт.
- Прописывание Sitemap после каждого User-agentЭто делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt
- Закрыть папки wp-content, wp-includes, cache, plugins, themesЭто устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше.
- Закрывать страницы тегов и категорийЕсли ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика
- Закрывать от индексации страницы пагинации /page/Это делать не нужно. Для таких страниц настраивается тег rel="canonical", таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса.
- Прописать Crawl-DelayМодное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей.
- ЛяпыНекоторые правила я могу отнести только к категории «блогер не подумал». Например: Disallow: /20 — по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше 🙂
Спорные рекомендации других блогеров для Robots.txt на WordPress
- КомментарииНекоторые ребята советуют закрывать от индексирования комментарии Disallow: /comments и Disallow: */comment-*.
- Открыть папку uploads только для Googlebot-Image и YandexImagesUser-agent: Googlebot-ImageAllow: /wp-content/uploads/User-agent: YandexImagesAllow: /wp-content/uploads/ Совет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
Спасибо за ваше внимание! Если у вас возникнут вопросы или предложения, пишите в комментариях!
seogio.ru
Правильный robots.txt для WordPress
О том, как сделать правильный robots.txt для WordPress написано уже достаточно. Однако, чтобы угодить своим читателям, я решил опубликовать свой пост на эту тему. Тем более, что моими коллегами эта тема раскрыта не полностью и тут можно многое добавить.

Что такое robots.txt и зачем он нужен?
robots.txt это текстовый документ, составленный в обыкновенном блокноте, расположенный в корневой директории блога и содержащий в себе инструкции по индексации для поисковых роботов. Проще говоря, что индексировать, а что нет. Наличие этого файла является обязательным условием для качественной внутренней поисковой оптимизации блога.
Как известно, блоги на платформе WordPress содержат в себе множество дублей (копий основного содержимого блога), а также целый набор служебных файлов. Дубли контента снижают его уникальность на домене и поисковые роботы могут наложить на блог серьезные штрафные санкции.
Чтобы повысить уникальность контента, облегчить поисковым ботам работу и тем самым улучшить качество индексации блога, нам и нужен robots.txt.

Правильный robots.txt для WordPress
Рассмотрим на примере моего robots.txt, как его правильно оформить и что в него должно входить.
Скачайте его себе на жесткий диск по этой ссылке и откройте для редактирования. В качестве редактора текстовых файлов настоятельно рекомендую использовать Notepad++.

Строки 6,7: Принято считать, что необходимо закрывать поисковым роботам доступ к служебным файлам в папках "wp-content" и "wp-includes". Но, Гугл по этому поводу нам говорит следующее:
Чтобы обеспечить правильное индексирование и отображение страниц, нужно предоставить роботу Googlebot доступ к JavaScript, CSS и графическим файлам на сайте. Робот Googlebot должен видеть ваш сайт как обычный пользователь. Если в файле robots.txt закрыт доступ к этим ресурсам, то Google не удастся правильно проанализировать и проиндексировать содержание. Это может ухудшить позиции вашего сайта в Поиске.
Таким образом, для Googlebot не рекомендуется запрещать доступ к файлам в этих папках.
Строка 40: С весны 2018 года директива "Host", указывающая главное зеркало сайта Яндексу, больше не действует. Главное зеркало для нашей поисковой системы теперь определяется только через 301 редирект.
Строки 42,43: Если у Вас еще не создана карта сайта, обязательно сделайте ее. В пути к файлам карты вместо моего адреса wordpress-book.ru пропишите свой. Этот ход сделает индексацию блога поисковиками полной и увеличит ее скорость.
Уже сейчас, можно сказать, что ваш правильный robots.txt для WordPress готов. В таком виде он подойдет для абсолютного большинства блогов и сайтов. Останется только закачать его в корень блога (обычно в папку public_html).
Сделать robots.txt для блога можно и с помощью плагина, например, PC Robots.txt. С его помощью вы сможете создать и редактировать свой robots.txt прямо в админке блога. Но я не советую использовать плагины для создания robots.txt, чтобы исключить лишнюю нагрузку на блог.
Содержание robots.txt любого блога или сайта, если он конечно есть, вы всегда можете посмотреть. Для этого достаточно в адресной строке браузера ввести к нему путь – https://wordpress-book.ru/robots.txt.
Ниже приведена информация по содержанию этого документа и некоторые рекомендации по его оформлению и анализу.
Звездочка "*", прописанная в тексте robots.txt, означает, что на ее месте допускается последовательность любых символов.
Директива "User-agent" определяет, для каких поисковых роботов даны указания по индексации, прописанные под ней. Таким образом, "User-agent: *" (строка 1) указывает, что инструкции, прописанные под ней, предназначены для всех поисковых систем.
Строка 21: Персонально для Яндекса под "User-agent: Yandex" дублируем список этих команд. Дублирование инструкций для Яндекса дает нам гарантию их выполнения поисковой системой.
Директива "Disallow" запрещает индексацию прописанного для нее каталога или страниц. Директива "Allow" разрешает. Командой "Disallow: /wp-content/" (строка 7) я запретил индексацию служебного каталога "wp-content" на сервере и соответственно всех папок в ней с их содержимым, но командой "Allow: /wp-content/uploads" (строка 8) разрешил индексировать все картинки в папке "upload" каталога "wp-content". Так как "Allow" является приоритетной директивой для поисковых роботов, то в индекс попадут только изображения папки "upload" каталога "wp-content".
Для директивы "Disallow" имеет смысл в некоторых случаях дополнительно прописывать следующие запреты:
- - /amp/ - дубли ускоренных мобильных страниц. На всякий случай для Яндекса.
- - /comments - закрыть от индексации комментарии. Зачем закрывать содержащийся в комментариях уникальный контент? Для большей релевантности ключевых слов и неиндексации исходящих ссылок в комментариях. Вряд ли это поможет.
- - /comment-page-* - другое дело древовидные комментарии. Когда комментарии не помещаются на одну страницу (их количество вы проставили в настройках админки), создается дубль страницы типа wordpress-book.ru/.../comment-page-1. Эти дубли конечно же надо закрывать.
- - /xmlrpc.php - служебный файл для удаленных вызовов. У меня его нет и соответственно нет индексации и без запрета.
- - /webstat/ - папка со статистикой сайта. Эта папка есть тоже далеко не у всех.
Нельзя не упомянуть про редко используемую, но очень полезную директиву для Яндекса - "Crawl-delay". Она задает роботу паузу во времени в секундах между скачиванием страниц, прописывается после групп директив "Disallow" и "Allow" и используется в случае повышенной нагрузки на сервер. Прописью "Crawl-delay: 2" я задал эту паузу в 2 секунды. При нормальной работе сервера качество индексации не пострадает, а при пиковых нагрузках не ухудшится.
Некоторым веб-мастерам может понадобится запретить индексацию файлов определенного типа, например, с расширением pdf. Для этого пропишите - "Disallow: *.pdf$". Или поместите все файлы, индексацию которых требуется запретить, в предварительно созданную новую папку, например, pdf, и пропишите "Disallow: /pdf/".
При необходимости запрета индексации всей рубрики, такое бывает ,например, при публикации в нее чужих интересных записей, пропишите - "Disallow: /nazvanie-rubriki/*", где "nazvanie-rubriki", как вы уже догадались - название рубрики, записи которой поисковикам индексировать не следует.
Тем, кто зарабатывает на своем блоге размещением контекстной рекламы в партнерстве с Google AdSense, будет нелишним прописать следующие две директивы:
User-agent: Mediapartners-Google
Disallow:
Это поможет роботу AdSense избежать ошибок сканирования страниц сайта и подбирать для них более релевантные объявления.
wp-content/uploads/2014/02/YouTube_Downloader_dlya_Ope.jpg",tid: "OIP.M3a4a31010ee6a500049754479585407do0
Обнаружил у себя только что вот такой вот новый вид дублей в Яндекс Вебмастере. 96 штук уже накопилось и это не предел. А ведь совсем недавно у wordpress-book.ru с дублями был полный порядок. Есть подозрение, что шлак с идентификатором tid:"OIP появляется в индексе поисковика после скачивания картинок роботом Яндекса. Если не лень, посмотрите сколько таких несуществующих страниц разных сайтов уже участвуют в поиске.
Понятно, что с этим чудом надо что-то делать. Достаточно добавить запрещающую директиву - "Disallow: /wp-content/uploads/*.jpg*tid*" в robots.txt. Если на сайте есть картинки png, gif и т.д., добавьте директивы с соответствующими расширениями изображений.
При редактировании robots.txt, учтите, что:
- перед каждой новой директивой "User-agent" должна быть пустая строка, которая обозначает конец инструкций для предыдущего поисковика. И соответственно после "User-agent" и между "Disallow" и "Allow" пустых строк быть не должно;
- запретом индексации страниц в результатах поиска "Disallow: /*?*" вы заодно можете случайно запретить индексацию всего контента, если адреса страниц вашего блога заданы по умолчанию со знаком вопроса в виде - /?p=123. Советую сделать для адресов ЧПУ (человеко понятные урлы :-)). Для этого в настройках постоянных ссылок выберите произвольный шаблон и поставьте плагин Rus-to-Lat.
Анализ robots.txt
Теперь, когда ваш robots.txt отредактирован и залит на сервер, остается только проверить, правильно ли он работает.
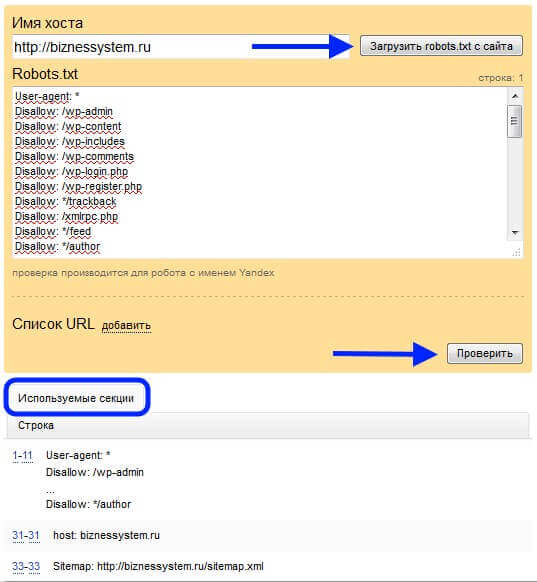
Зайдите в свой аккаунт Яндекс Вебмастер и перейдите "Настройки индексирования" → "Анализ robots.txt". Нажмите на кнопку "Загрузить robots.txt с сайта" и далее на кнопку "Проверить".

Если Яндексу понравится ваш файл, под кнопкой "Проверить" появится сообщение, примерно как на картинке выше.
Недавно в инструментах для веб-мастеров Гугла появилось очень полезная функция - "Инструмент проверки файла robots.txt". Можно проверить свой файл на наличие ошибок и предупреждений.
Просто в своем аккаунте перейдите "Сканирование" → "Инструмент проверки файла robots.txt".
Через некоторое время, когда бот Яндекса скачает ваш robots.txt, проанализируйте в Яндекс Вебмастере адреса страниц вошедших в индекс и исключенных из него в robots.txt. Вошедшие в индекс дубли срочно запрещайте к индексации.
Теперь ваш robots.txt для WordPress правильный и можно поставить еще одну галочку под пунктом выполнения задач по внутренней поисковой оптимизации блога.
robots.txt запретить индексацию всем
При создании тестового блога или при самом его рождении, если вы хотите полностью запретить индексацию сайта всеми поисковыми системами, в robots.txt должно быть прописано всего лишь следующее:
User-agent: *Disallow: /
wordpress-book.ru
Robots.txt для WordPress, идеальный вариант robots.txt для WP
Файл robots.txt это первоначальный, и один из главнейших инструментов для корректной индексации ваших сайтов и их контента. Отсутствие данного файла приведет к печальным последствиям которые тяжело будет исправить. От того как вы настроите robots.txt зависит что попадет в выдачу по запросам в поисковых системах. Сейчас рассмотрим правильный файл robots.txt для WordPress сайта.
Навигация по странице:
Для чего использовать robots.txt?
Перед тем как приступать к созданию и наполнению давайте разберем саму суть данного файла.
Ваш сайт это набор файлов и папок, некоторые из которых нужно защитить от чтения от сторонних глаз, которыми являются так же и поисковые роботы, пришедшие прочитать и запомнить наш контент, для дальнейшей выдачи в поиске.
Чем занимается поисковой робот на сайте?
Итак, к примеру ваш сайт посетил поисковой робот, что он делает в первую очередь? Во-первых пытается найти уникальную информацию, которую сможет занести в свою базу данных. Если роботс отсутствует, а именно к нему в первую очередь обращается робот, тогда он начинает «читать» файлы находящиеся в корне сайта, что конечно же нам не очень понравиться, ведь он не только не найдет там нужную ему информацию, а и прочитает наши данные настроек, которые созданы для нашей личной цели. Именно для этого и существует robots.txt. Он дает указания роботу куда ходить нужно, а куда заглядывать не стоит.
Создание и размещение файла на сайте WordPress.
Для того что бы создать путеводитель для роботов, вам потребуется обычный блокнот windows, в котором вы будете прописывать нужные команды для поисковых роботов. После этого нужно сохранить файл в формате «txt», под названием «robots». На этом создание завершено, далее в статье мы рассмотрим какие же команды должны находиться в robots.txt для WordPress.
Где размещать?
Robots.txt размещается на вашем хостинге, непосредственно в корневой папке сайта, куда мы перенесли наш сайт. Теперь поисковой робот перед тем как лазить по нашему сайту, сначала спросит разрешение куда ему можно, а куда запрещено заходить.
Важно: при размещении документа в подкаталогах, роботы не смогут найти этот файл.

Зайдя к вам на сайт робот заходит смотрит предназначеную для него «инструкцию» и начинает его изучать. Изучив до конца он пойдет по выбранному вами пути индексации, и будет игнорировать те директории, папки и URL к которым вы запретили обращаться.
Что включает в себя роботс?
Robots.txt несет в себе информативные данные для поисковых роботов и включает в себя такие основные «команды»:
User-agent
Указывает на имя потенциального робота посетителя. Синтаксис «User-agent: *» будет означать что данным командам должны следовать все роботы. Варианты для отдельных роботов рассматривать не будем, их очень много. По этому для примера будет только два варианта (для всех роботов и отдельно для Яндекс).
Disallow
Команда для роботов, рассказывающая о том куда ходить не стоит, запрещает чтение указанных адресов и файлов.
Allow
Команда которая рекомендует «направление» на индексирования данного адреса или файла.
Host
Данная команда указывает роботу, какой из вариантов сайта будет нашим главным зеркалом сайта.
Sitemap
Место нахождения xml карты сайта по которой должен пробежаться посетивший нас робот, в той части за которой он пришел (контент сайта).
Правильный robots.txt для сайта на CMS WordPress.
Для того что бы правильно настроить файл robots.txt специально под «движок» WordPress нужно для начала понимать что ищут роботы и что им будет интересно.А наши паучки ищут контент нашего ресурса, и им совершенно не нужно знать о всех остальных конфигурационных данных наших сайтов. Во первых они им приходятся не по вкусу, и от переедания таковых они могут покинуть наш сайт так и не найдя то что нам бы хотелось да еще и вынесут наши запрещенные для общего глаза данные на общее обозрение.
Говоря о требуемых размещения директорий в robots.txt для WordPress, нам нужно разобраться с главной (корневой) п
yrokiwp.ru
Правильный файл robots.txt для WordPress — важные правила при запрете индексации
В этой статье пример оптимального, на мой взгляд, кода для файла robots.txt под WordPress, который вы можете использовать в своих сайтах.
Для начала, вспомним зачем нужен robots.txt — файл robots.txt нужен исключительно для поисковых роботов, чтобы «сказать» им какие разделы/страницы сайта посещать, а какие посещать не нужно. Страницы, которые закрыты от посещения не будут попадать в индекс поисковиков (Yandex, Google и т.д.).

Вариант 1: оптимальный код robots.txt для WordPress
User-agent: * Disallow: /cgi-bin # классика... Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search # поиск Disallow: /author/ # архив автора Disallow: *?attachment_id= # страница вложения. Вообще-то на ней редирект... Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */page/ # все виды пагинации Allow: */uploads # открываем uploads Allow: /*/*.js # внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д. #Disallow: /wp/ # когда WP установлен в подкаталог wp Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap2.xml # еще один файл #Sitemap: http://site.ru/sitemap.xml.gz # сжатая версия (.gz) Host: site.ru # для Яндекса и Mail.RU. (межсекционная) # Версия кода: 1.0 # Не забудьте поменять `site.ru` на ваш сайт.Разбор кода:
-
В строке User-agent: * мы указываем, что все нижеприведенные правила будут работать для всех поисковых роботов *. Если нужно, чтобы эти правила работали только для одного, конкретного робота, то вместо * указываем имя робота (User-agent: Yandex, User-agent: Googlebot).
-
В строке Allow: */uploads мы намеренно разрешаем индексировать страницы, в которых встречается /uploads. Это правило обязательно, т.к. выше мы запрещаем индексировать страницы начинающихся с /wp-, а /wp- входит в /wp-content/uploads. Поэтому, чтобы перебить правило Disallow: /wp- нужна строчка Allow: */uploads, ведь по ссылкам типа /wp-content/uploads/... у нас могут лежать картинки, которые должны индексироваться, так же там могут лежать какие-то загруженные файлы, которые незачем скрывать. Allow: может быть "до" или "после" Disallow:.
-
Остальные строчки запрещают роботам "ходить" по ссылкам, которые начинаются с:
- Disallow: /cgi-bin - закрывает каталог скриптов на сервере
- Disallow: /feed - закрывает RSS фид блога
- Disallow: /trackback - закрывает уведомления
- Disallow: ?s= или Disallow: *?s= - закрыавет страницы поиска
- Disallow: */page/ - закрывает все виды пагинации
-
Правило Sitemap: http://site.ru/sitemap.xml указывает роботу на файл с картой сайта в формате XML. Если у вас на сайте есть такой файл, то пропишите полный путь к нему. Таких файлов может быть несколько, тогда указываем путь к каждому отдельно.
-
В строке Host: site.ru мы указываем главное зеркало сайта. Если у сайта существуют зеркала (копии сайта на других доменах), то чтобы Яндекс индексировал всех их одинаково, нужно указывать главное зеркало. Директива Host: понимает только Яндекс, Google не понимает! Если сайт работает под https протоколом, то его обязательно нужно указать в Host: Host: https://site.ru
Из документации Яндекса: «Host — независимая директива и работает в любом месте файла (межсекционная)». Поэтому её ставим наверх или в самый конец файла, через пустую строку.
Это важно: сортировка правил перед обработкой
Yandex и Google обрабатывает директивы Allow и Disallow не по порядку в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
User-agent: * Allow: */uploads Disallow: /wp-будет прочитана как:
User-agent: * Disallow: /wp- Allow: */uploadsТаким образом, если проверяется ссылка вида: /wp-content/uploads/file.jpg, правило Disallow: /wp- ссылку запретит, а следующее правило Allow: */uploads её разрешит и ссылка будет доступна для сканирования.
Чтобы быстро понять и применять особенность сортировки, запомните такое правило: «чем длиннее правило в robots.txt, тем больший приоритет оно имеет. Если длина правил одинаковая, то приоритет отдается директиве Allow.»
Вариант 2: стандартный robots.txt для WordPress
Не знаю кто как, а я за первый вариант! Потому что он логичнее — не надо полностью дублировать секцию ради того, чтобы указать директиву Host для Яндекса, которая является межсекционной (понимается роботом в любом месте шаблона, без указания к какому роботу она относится). Что касается нестандартной директивы Allow, то она работает для Яндекса и Гугла и если она не откроет папку uploads для других роботов, которые её не понимают, то в 99% ничего опасного это за собой не повлечет. Я пока не заметил что первый robots работает не так как нужно.
Вышеприведенный код немного не корректный. Спасибо комментатору "robots.txt" за указание на некорректность, правда в чем она заключалась пришлось разбираться самому. И вот к чему я пришел (могу ошибаться):
-
Некоторые роботы (не Яндекса и Гугла) — не понимают более 2 директив: User-agent: и Disallow:
- Директиву Яндекса Host: нужно использовать после Disallow:, потому что некоторые роботы (не Яндекса и Гугла), могут не понять её и вообще забраковать robots.txt. Cамому же Яндексу, судя по документации, абсолютно все равно где и как использовать Host:, хоть вообще создавай robots.txt с одной только строчкой Host: www.site.ru, для того, чтобы склеить все зеркала сайта.
3. Sitemap: межсекционная директива для Яндекса и Google и видимо для многих других роботов тоже, поэтому её пишем в конце через пустую строку и она будет работать для всех роботов сразу.
На основе этих поправок, корректный код должен выглядеть так:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Host: site.ru User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Sitemap: http://site.ru/sitemap.xmlДописываем под себя
Если вам нужно запретить еще какие-либо страницы или группы страниц, можете внизу добавить правило (директиву) Disallow:. Например, нам нужно закрыть от индексации все записи в категории news, тогда перед Sitemap: добавляем правило:
Disallow: /newsОно запретить роботам ходить по подобным ссылками:
- http://site.ru/news
- http://site.ru/news/drugoe-nazvanie/
Если нужно закрыть любые вхождения /news, то пишем:
Disallow: */newsЗакроет:
- http://site.ru/news
- http://site.ru/my/news/drugoe-nazvanie/
- http://site.ru/category/newsletter-nazvanie.html
Подробнее изучить директивы robots.txt вы можете на странице помощи Яндекса (но имейте ввиду, что не все правила, которые описаны там, работают для Google).
Проверка robots.txt и документация
Проверить правильно ли работают прописанные правила можно по следующим ссылкам:
Crawl-delay - таймаут для сумасшедших роботов (с 2018 года не учитывается)
Яндекс
Теперь и Яндекс перестал учитывать Crawl-delay:
Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay в robots.txt […] Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Когда робот Яндекса сканирует сайт как сумасшедший и это создает излишнюю нагрузку на сервер. Робота можно попросить «поубавить обороты».
Для этого нужно использовать директиву Crawl-delay. Она указывает время в секундах, которое робот должен простаивать (ждать) для сканирования каждой следующей страницы сайта.
Для совместимости с роботами, которые плохо следуют стандарту robots.txt, Crawl-delay нужно указывать в группе (в секции User-Agent) сразу после Disallow и Allow
Робот Яндекса понимает дробные значения, например, 0.5 (пол секунды). Это не гарантирует, что поисковый робот будет заходить на ваш сайт каждые полсекунды, но позволяет ускорить обход сайта.
Примеры:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Crawl-delay: 1.5 # таймаут в 1.5 секунды User-agent: * Disallow: /wp-admin Disallow: /wp-includes Allow: /wp-*.gif Crawl-delay: 2 # таймаут в 2 секундыРобот Google не понимает директиву Crawl-delay. Таймаут его роботам можно указать в панели вебмастера.
Я спросил у Яндекса...
Задал вопрос в тех. поддержку Яндекса насчет межсекционного использования директив Host и Sitemap:
Вопрос:
Здравствуйте!Пишу статью насчет robots.txt на своем блоге. Хотелось бы получить ответ на такой вопрос (в документации я не нашел однозначного "да"):
Если мне нужно склеить все зеркала и для этого я использую директиву Host в самом начале фала robots.txt:
Host: site.ru User-agent: * Disallow: /asdБудет ли в данном примере правильно работать Host: site.ru? Будет ли она указывать роботам что site.ru это основное зеркало. Т.е. эту директиву я использую не в секции, а отдельно (в начале файла) без указания к какому User-agent она относится.
Также хотел узнать, обязательно ли директиву Sitemap нужно использовать внутри секции или можно использовать за пределами: например, через пустую строчку, после секции?
User-agent: Yandex Disallow: /asd User-agent: * Disallow: /asd Sitemap: http://site.ru/sitemap.xmlПоймет ли робот в данном примере директиву Sitemap?
Надеюсь получить от вас ответ, который поставит жирную точку в моих сомнениях.
Спасибо!
Ответ:
Здравствуйте!
Директивы Host и Sitemap являются межсекционными, поэтому будут использоваться роботом вне зависимости от места в файле robots.txt, где они указаны.
--С уважением, Платон ЩукинСлужба поддержки Яндекса
Заключение
Важно помнить, что изменения в robots.txt на уже рабочем сайте будут заметны только спустя несколько месяцев (2-3 месяца).
Ходят слухи, что Google иногда может проигнорировать правила в robots.txt и взять страницу в индекс, если сочтет, что страница ну очень уникальная и полезная и она просто обязана быть в индексе. Однако другие слухи опровергают эту гипотезу тем, что неопытные оптимизаторы могут неправильно указать правила в robots.txt и так закрыть нужные страницы от индексации и оставить ненужные. Я больше склоняюсь ко второму предположению...
Статьи до этого: SEOwp-kama.ru
Как сделать robots.txt для WordPress.Создаем правильный robots.txt для сайта на WordPress
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет.
Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет.
Создание файла robots.txt
1. Создайте обычный текстовый файл с названием robots в формате .txt.
2. Добавьте в него следующую информацию :
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= Host: site.com Sitemap: http://site.com/sitemap.xml3. Замените в в текстовом файле строчку site.com на адрес Вашего сайта.
4. Сохраните изменения и загрузите файл robots.txt (с помощью FTP) в корневую папку Вашего сайта.
5. Готово.
Для просмотра и скачки примера, нажмите кнопку ниже и сохраните файл (Ctrl + S на клавиатуре).
Скачать пример файла robots.txtРазбираемся в файле robots.txt (директивы)
Давайте теперь более детально разберем, что именно и зачем мы добавили в файл robots.txt.
User-agent — директива, которая используется для указания названия поискового робота. С помощью этой директивы можно запретить или разрешить поисковым роботам посещать Ваш сайт. Примеры:
Запрещаем роботу Яндекса просматривать папку с кэшем:
User-agent: Yandex Disallow: /wp-content/cacheРазрешаем роботу Bing просматривать папку themes (с темами сайта):
User-agent: bingbot Allow: /wp-content/themesAllow и Disallow — разрешающая и запрещающая директива. Примеры:
Разрешим боту Яндекса просматривать папку wp-admin:
User-agent: Yandex Allow: /wp-adminЗапретим всем ботам просматривать папку wp-content:
User-agent: * Disallow: /wp-contentВ нашем robots.txt мы не используем директиву Allow, так как всё, что не запрещено боту с помощью Disallow — по умолчанию будет разрешено.
Host — директива, с помощью которой нужно указать главное зеркало сайта, которое и будет индексироваться роботом.
Sitemap — используя эту директиву, нужно указать путь к карте сайта. Напомню, что карта сайта является очень важным инструментом при продвижении сайта! Обязательно указывайте её в этой директиве!
Если остались какие-то вопросы — задавайте их в комментарий. Если же информации в этом уроке для Вас оказалось недостаточно, рекомендую почитать подробнее о всех директивах и способах их использования перейдя по этой ссылке.
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет. Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет. Создание файла robots.txt 1. Создайте обычный текстовый файл с названием robots в формате .txt. 2. Добавьте в него следующую информацию : User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes…
Создание и настройка robots.txt
Рейтинг: 4.44 ( 27 голосов ) 100wp-lessons.com
Делаем правильный файл Robots.txt для Wordpress
Приветствую вас, друзья. Займемся мы сегодня составлением правильного файла Robots.txt для WordPress блога. Файл Robots является ключевым элементом внутренней оптимизации сайта, так как выступает в роли гида-проводника для поисковых систем, посещающих ваш ресурс.

Содержание:
Само название файла robots.txt подсказываем нам, что он предназначен для роботов, а не для людей. В статье о том, как работают поисковые системы, я описывал алгоритм их работы, если не читали, рекомендую ознакомиться.
Зачем нужен файл robots.txt
Представьте себе, что ваш сайт – это дом. В каждом доме есть разные служебные помещения, типа котельной, кладовки, погреба, в некоторых комнатах есть потаенные уголки (сейф). Все эти тайные пространства гостям видеть не нужно, они предназначены только для хозяев.
Аналогичным образом, каждый сайт имеет свои служебные помещения (разделы), а поисковые роботы – это гости. Так вот, задача правильного robots.txt – закрыть на ключик все служебные разделы сайта и пригласить поисковые системы только в те блоки, которые созданы для внешнего мира.
Примерами таких служебных зон являются – админка сайта, папки с темами оформления, скриптами и т.д.
Вторая функция этого файла – это избавление поисковой выдачи от дублированного контента. Если говорить о WordPress, то, часто, мы можем по разным URL находить одни и те же статьи или их части. Допустим, анонсы статей в разделах с архивами и рубриках идентичны друг другу (только комбинации разные), а страница автора обычного блога на 100% копирует весь контент.
Поисковики интернета могут просто запутаться во всем многообразии таких страниц и неверно понять – что нужно показывать в поисковой выдаче. Закрыв одни разделы, и открыв другие, мы дадим однозначную рекомендацию роботам по правильной индексации сайта, и в поиске окажутся те страницы, которые мы задумывали для пользователей.
Если у вас нет правильно настроенного файла Robots.txt, то возможны 2 варианта:
1. В выдачу попадет каша из всевозможных страниц с сомнительной релевантностью и низкой уникальностью.
2. Поисковик посчитает кашей весь ваш сайт и наложит на него санкции, удалив из выдачи весь сайт или отдельные его части.
Есть у него еще пара функций, о них я расскажу по ходу.
Принцип работы файла robots
Работа файла строится всего на 3-х элементах:
- Выбор поискового робота
- Запрет на индексацию разделов
- Разрешение индексации разделов
1. Как указать поискового робота
С помощью директивы User-agent прописывается имя робота, для которого будут действовать следующие за ней правила. Она используется вот в таком формате:
User-agent: * # для всех роботов
User-agent: * # для всех роботов |
User-agent: имя робота # для конкретного робота
User-agent: имя робота # для конкретного робота |
После символа «#» пишутся комментарии, в обработке они не участвуют.
Таким образом, для разных поисковых систем и роботов могут быть заданы разные правила.
Основные роботы, на которые стоит ориентироваться – это yandex и googlebot, они представляют соответствующие поисковики.
2. Как запретить индексацию в Robots.txt
Запрет индексации осуществляется в помощью директивы Disallow. После нее прописывается раздел или элемент сайта, который не должен попадать в поиск. Указывать можно как конкретные папки и документы, так и разделы с определенными признаками.
Если после этой директивы не указать ничего, то робот посчитает, что запретов нет.
Disallow: #запретов нет
Disallow: #запретов нет |
Для запрета файлов указываем путь относительного домена.
Disallow: /zapretniy.php #запрет к индексации файла zapretniy.php
Disallow: /zapretniy.php #запрет к индексации файла zapretniy.php |
Запрет разделов осуществляется аналогичным образом.
Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta
Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta |
Если нам нужно запретить разные разделы и страницы, содержащие одинаковые признаки, то используем символ «*». Звездочка означает, что на ее месте могут быть любые символы (любые разделы, любой степени вложенности).
Disallow: */*test #будут закрыты все страницы, в адресе которых содержится test
Disallow: */*test #будут закрыты все страницы, в адресе которых содержится test |
Обратите внимание, что на конце правила звездочка не ставится, считается, что она там есть всегда. Отменить ее можно с помощью знака «$»
Disallow: */*test$ #запрет к индексации всех страниц, оканчивающихся на test
Disallow: */*test$ #запрет к индексации всех страниц, оканчивающихся на test |
Выражения можно комбинировать, например:
Disallow: /test/*.pdf$ #закрывает все pdf файлы в разделе /test/ и его подразделах.
Disallow: /test/*.pdf$ #закрывает все pdf файлы в разделе /test/ и его подразделах. |
3. Как разрешить индексацию в Robots.txt
По-умолчанию, все разделы сайта открыты для поисковых роботов. Директива, разрешающая индексацию нужна в тех случаях, когда вам необходимо открыть какой-либо кусочек из блока закрытого директивой disallow.
Для открытия служит директива Allow. К ней применяются те же самые атрибуты. Пример работы может выглядеть вот так:
User-agent: * # для всех роботов Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta Allow: *.pdf$ #разрешает индексировать pdf файлы, даже в разделе /razdel-sajta
User-agent: * # для всех роботов Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta Allow: *.pdf$ #разрешает индексировать pdf файлы, даже в разделе /razdel-sajta |
Теорию мы изучили, переходим к практике.
Как создать и проверить Robots.txt
Проверить, что содержит ваш файл на данный момент можно в сервисе Яндекса — Проверка Robots.txt. Введете там адрес своего сайта, и он покажет всю информацию.
Если у вас такого файла нет, то необходимо срочного его создать. Открываете текстовый редактор (блокнот, notepad+, akelpad и т.д.), создаете файл с названием robots, заполняете его нужными директивами (ниже я расскажу, как выглядит правильный код для WordPress) и сохраняете с txt расширением.
Дальше, помещаем файл в корневую папку вашего сайта (рядом с index.php) с помощью файлового менеджера вашего хостинга или ftp клиента, например, filezilla.
Если у вас WordPress и установлен All in One SEO Pack, то в нем все делается прямо из админки, в этой статье я рассказывал как.
Robots.txt для WordPress
Под особенности каждой CMS должен создаваться свой правильный файл, так как конфигурация системы отличается и везде свои служебные папки и документы.
Мой файл robots.txt имеет следующий вид:
User-agent: * Disallow: /wp-admin Disallow: /wp-content Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: /xmlrpc.php Disallow: */feed Disallow: */author Allow: /wp-content/themes/папка_вашей_темы/ Allow: /wp-content/plugins/ Allow: /wp-includes/js/ User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ host: biznessystem.ru Sitemap: http://biznessystem.ru/sitemap.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | User-agent: * Disallow: /wp-admin Disallow: /wp-content Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: /xmlrpc.php Disallow: */feed Disallow: */author Allow: /wp-content/themes/папка_вашей_темы/ Allow: /wp-content/plugins/ Allow: /wp-includes/js/
User-agent: Googlebot-Image Allow: /wp-content/uploads/
User-agent: YandexImages Allow: /wp-content/uploads/
host: biznessystem.ru
Sitemap: http://biznessystem.ru/sitemap.xml |
Первый блок действует для всех роботов, так как в строке User-agent стоит «*». Со 2 по 9 строки закрывают служебные разделы самого вордпресс. 10 – удаляет из индекса страницы RSS ленты. 11 – закрывает от индексации авторские страницы.
По последним требованиям поисковиков, необходимо открыть доступ к стилям и скриптам. Для этих целей в 12, 13 и 14 строках прописываем разрешение на индексирование папки с шаблоном сайта, плагинами и Java скриптами.
Дальше у меня идет 2 блока, открывающих доступ к папке с картинками роботам YandexImages и Googlebot-Image. Можно их не выделять отдельно, а разрешающую директиву для папки с картинками перенести выше на 15 строку, чтобы все роботы имели доступ к изображениям сайта.
Если бы я не использовал All-in-One-Seo-Pack, то добавил бы правило, закрывающее архивы (Disallow: */20) и метки (Disallow: */tag).
При использовании стандартного поиска по сайту от WordPress, стоит поставить директиву, закрывающую страницы поиска (Disallow: *?s=). А лучше, настройте Яндекс поиск по сайту, как это сделано на моем блоге.
Обратите внимание на 2 правила:
1. Все директивы для одного робота идут подряд без пропуска строк.
2. Блоки для разных роботов обязательно разделяются пустой строкой.
В самом конце есть директивы, которые мы ранее не рассматривали – это host и sitemap. Обе эти директивы называют межсекционными (можно ставить вне блоков).
Host – указывает главное зеркало ресурса. Обязательно стоит указать какой домен является главным для вашего сайта – с www или без www. Если у сайта есть еще зеркала, то в их файлах тоже нужно прописать главное. Данную директиву понимает только Яндекс.
Sitemap – это директива, в которой прописывается путь к XML карте вашего сайта. Ее понимают и Гугл и Яндекс.
Дополнения и заблуждения
1. Некоторые вебмастера делают отдельный блок для Яндекса, полностью дублируя общий и добавляя директиву host. Якобы, иначе yandex может не понять. Это лишнее. Мой файл robots.txt известен поисковику давно, и он в нем прекрасно ориентируется, полностью отрабатывая все указания.
2. Можно заменить несколько строк, начинающихся с wp- одной директивой Disallow: /wp-, я не стал такого делать, так как боюсь – вдруг у меня есть статьи, начинающиеся с wp-, если вы уверены, что ваш блог такого не содержит, смело сокращайте код.
3. Переиндексация файла robots.txt проходит не мгновенно, поэтому, ваши изменения поисковики могут заметить лишь спустя пару месяцев.
4. Гугл рекомендует открывать доступ своим ботам к файлам темы оформления и скриптам сайта, пугая вебмастеров возможными санкциями за несоблюдение этого правила. Я провел эксперимент, где оценивал, насколько сильно влияет это требование на позиции сайта в поиске — подробности и результаты эксперимента тут.
Резюме
Правильный файл Robots.txt для WordPress является почти шаблонным документом и его вид одинаков для 99% проектов, созданных на этом движке. Максимум, что требуется для вебмастера — это внести индивидуальные правила для используемого шаблона.

- 5
- 4
- 3
- 2
- 1
biznessystem.ru
Идеальный Robots.txt для WordPress сайта с протоколом https
Здравствуйте уважаемые читатели видео портала KladProraba.com. В этой статье (без видео), я на примере своего файла robots.txt покажу вам, каким должен быть идеальный Robots.txt для WordPress сайта с протоколом https.

Каждый вебмастер знает о том, что наличие таких файлов, как карта ресурса sitemap.xml и robots.txt, является обязательным условием для правильной индексации любого интернет-магазина, сайта, блога.
При переходе сайта с http на https (как правильно осуществить переход читайте здесь) с файлом sitemap.xml всё в порядке, вмешательства не требуется. Иначе обстоят дела с файлом robots.txt. После осуществления перехода ресурса, необходимо внести небольшие изменения в файл robots.txt. Ниже, я привожу примеры файлов robots.txt до и после перехода моего сайта на защищённый протокол https.
Правильный файл robots.txt для сайта на WordPress с обычным http
User-agent: *Disallow: /wp-adminDisallow: /wp-includesDisallow: /wp-content/pluginsDisallow: /wp-content/cacheDisallow: /wp-content/themesDisallow: /trackbackDisallow: */trackbackDisallow: */*/trackbackDisallow: */*/feed/*/Disallow: */feedDisallow: /*?*Disallow: /tag
User-agent: YandexDisallow: /wp-adminDisallow: /wp-includesDisallow: /wp-content/pluginsDisallow: /wp-content/cacheDisallow: /wp-content/themesDisallow: /trackbackDisallow: */trackbackDisallow: */*/trackbackDisallow: */*/feed/*/Disallow: */feedDisallow: /*?*Disallow: /tagHost: мойсайт.comSitemap: http://мойсайт.com/sitemap.xml.gzSitemap: http://мойсайт.com/sitemap.xml
Правильный файл robots.txt для сайта на WordPress с протоколом https
User-agent: *Disallow: /wp-adminDisallow: /wp-includesDisallow: /wp-content/pluginsDisallow: /wp-content/cacheDisallow: /wp-content/themesDisallow: /trackbackDisallow: */trackbackDisallow: */*/trackbackDisallow: */*/feed/*/Disallow: */feedDisallow: /*?*Disallow: /tag
User-agent: YandexDisallow: /wp-adminDisallow: /wp-includesDisallow: /wp-content/pluginsDisallow: /wp-content/cacheDisallow: /wp-content/themesDisallow: /trackbackDisallow: */trackbackDisallow: */*/trackbackDisallow: */*/feed/*/Disallow: */feedDisallow: /*?*Disallow: /tagHost: https://мойсайт.comSitemap: https://мойсайт.com/sitemap.xml.gzSitemap: https://мойсайт.com/sitemap.xml
Результат проверки файла robots.txt в гугл вебмастер – ошибок нет.
Результат проверки файла robots.txt в яндекс вебмастер – ошибок нет.
Файл robots.txt без ошибок
Как видно по результатам – проблем нет, ошибок нет. Да, вот ещё один момент: я запретил индексацию тегов на своём сайте, посредством добавления в файл robots.txt запрета – Disallow: /tag. Вы так же можете запретить индексацию тегов, или можете удалить запрет – выбор за вами. Надеюсь, моя статья с примером помогла решить вашу проблему с определением идеального файла robots.txt для вашего ресурса. Всего доброго и удачи 🙂
С уважением Ярослав
Идеальный Robots.txt для WordPress сайта с протоколом https
Ваша оценка?kladproraba.com