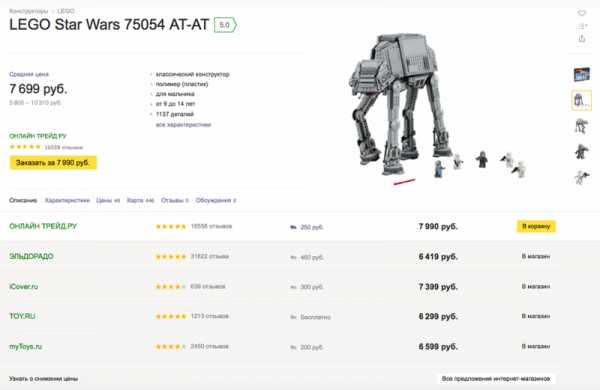
Алгоритм текстового ранжирования Яндекса: правила, актуальные более 10 лет. Формула ранжирования
Формула ранжирования «Яндекса для коммерческих сайтов»
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Алгоритмы работы поисковиков похожи на дремучий лес, в котором проложена одна, но хорошо освещенная тропка. И дорогу видно, и куда она ведет известно, но никогда не знаешь, там ли повернул, кто смотрит на тебя из чащобы и не схватит ли тебя из кустов какой-нибудь «Минусинск». Поэтому сегодня говорим о формуле коммерческого ранжирования «Яндекса»: разбираемся, что о ней известно и выясняем, как она работает. Если не знаете, как работает самая популярная в России поисковая машина, читайте.
Что о ней известно?
Точного принципа коммерческого ранжирования «Яндекса» не знает никто, даже сами сотрудники компании. Это не потому, что она хранится в секретном бункере с полком охраны, а потому что люди уже давно ее не разрабатывают – за них это делает машина. Но это не значит, что об алгоритме неизвестно совсем ничего. Начнем с основ.
Что такое ранжирование и как устроена формула «Яндекса»?
Ранжирование – это упорядочивание страниц по наибольшему соответствию поисковому запросу. Поисковая машина анализирует все страницы с подходящим содержанием и расставляет по убыванию полезности для пользователя. Самые крутые, информативные, качественные и популярные сайты занимают первые строчки, а те, что чуть похуже, опускаются ниже.
Формула ранжирования «Яндекса» – это алгоритм, который определяет порядок страниц в поисковой выдаче. Он работает в полуавтоматическом режиме. Специальные сотрудники «Яндекса» (асессоры) выставляют оценки работе робота: если выдача по какому-то случайному запросу составлена грамотно, робот получает заслуженную «пятерку» и просит у мамы карманные деньги. Если не очень, делает работу над ошибками и пробует снова.
Алгоритм определяет порядок выдачи при помощи факторов – вручную заданных критериев оценки качества страницы. В формуле ранжирования поисковой системы «Яндекс» их около 800, причем никто, кроме самих работников «Яндекса», не видел полного перечня. SEO-специалисты знают много, но не все. Большинство второстепенных факторов вывести просто невозможно, потому что никто не может влезть в голову сотрудникам «яндексоидам».

Когда асессор ставит оценку сформированной роботом выдаче, последний пытается понять, почему оценка именно такая. Например, алгоритм не учел, что у какого-то сайта просто ужасно неудобная структура и вырвиглазный дизайн, но при прочих равных поставил его выше конкурентов. После нескольких повторений робот поймет ошибку и свяжет низкую оценку именно с этим фактором.
Формула ранжирования «Яндекса» постоянно меняется: перерассчитывает «вес» факторов и ценность уже имеющихся страниц на основе новой информации о поведении пользователей. Это необходимо, чтобы компенсировать постоянные изменения, происходящие в сети. Например, через год люди могут полюбить сайты со встроенными чатами и поисковая машина начнет ранжировать их выше. Не без помощи асессоров.
Формула ранжирования «Яндекса» огромна – это огромный массив данных и алгоритмов, написать который живой человек был бы не в состоянии. Она учитывает регион пользователя, текущую ситуацию с предпочтениями посетителей, качество ресурсов, их авторитетность, юзабилити и черт знает, что еще. Но никто не отчаивается, потому что некоторые подсказки о принципе ее работы дает сам «Яндекс». Например, с коммерческими сайтами все достаточно прозрачно. Поговорим о том, по какому принципу они ранжируются.
Формула коммерческого ранжирования «Яндекса»
В 2013 году «Яндекс» ввел новое понятие – коммерческая релевантность. Она отличается от «обычной» тематической тем, что оценивается в первую очередь полезность ресурса для потенциального покупателя. В общем случае ситуация с ранжированием продающих сайтов стандартная – в топ попадает самые полезные, удобные и релевантные страницы. Различия – в ключевых факторах. Внимание обращается на:
- Пользовательское доверие.
- Удобство использования.
- Качество ресурса.
- Сервис.
Понятно, что машина не всегда правильно оценивает качество сайта, потому что она не человек. С технической точки зрения все может быть логично и продумано, но на деле пользоваться сайтом будет тяжело. Чтобы помочь алгоритму разобраться, нужен человеческий взгляд. За него отвечают асессоры, о которых писалось выше. Они помогают системе научиться отличать плохие сайты от хороших самостоятельно.
Работа асессоров делится на два этапа: оценка тематической и коммерческой релевантности. Первый этап достаточно простой: сотрудник «Яндекса» присваивает странице конкретную оценку. Ресурсы бывают:
- Нерелевантными.
- Релевантными.
- Высокорелевантными.
- Полезными.
- Витальными.
Потом оценивается коммерческая релевантность. Витальные и полезные сайты из выборки исключаются, потому что у них и так все хорошо. Асессоры смотрят на:
- Количество и разнообразие товаров и услуг по конкретному поисковому запросу. Ассортимент может быть маленьким, стандартным или большим (это официальная шкала оценок). Критерии, по которым сайту присваивается одна из них покрыты тайной.
- Надежность и качество обслуживания. Здесь возможных оценки четыре: спам, стандарт, хорошо и отлично. «Стандартные» ресурсы держат среднюю температуру по больнице, «хорошие» предлагают чуть лучшее качество, а «отличные» выделяются на фоне и тех, и других. Со спамными все понятно – это фейковые страницы, на которых ничего нельзя купить.
- Юзабилити и дизайн. Возможных оценки три: плохо, хорошо и отлично.

В конечном итоге, все оценки асессоров трансформируются в доработки формулы коммерческого ранжирования «Яндекса» и она начинает видеть все промахи сама. Поэтому даже если сейчас вы в топе и думаете, что все в порядке, не факт, что так будет через полгода.
В общем виде формула коммерческой релевантности выглядит так:
Сделаем понятней:
Коммерческая релевантность = (Разнообразие и количество товаров) х (2х(надежность) + (дизайн) + (юзабилити) + 2х(качество сервиса).
По мнению «Яндекса», хороший коммерческий сайт предлагает много товаров, хорошо выглядит, надежен и удобен в использовании. При этом формула коммерческого ранжирования «Яндекса» очень чувствительна к надежности сайта и качеству сервиса – они умножаются на два. Это логично, потому что в интересах поисковика отвечать на запросы пользователей максимально точно.
Коммерческие факторы в формуле ранжирования «Яндекса»
Общая релевантность ресурса складывается из коммерческой и тематической. С последней все понятно – если контент соответствует запросу, то все хорошо. С первой сложнее – нужно, чтобы страница была оформлена по критериям качества самого «Яндекса». Это:
- Подробная информация о контактах. Все должно быть максимально полно: телефоны, e-mail, Skype, адрес, карта проезда, «как добраться», график работы. Если телефонов несколько – укажите все. Если у вас несколько филиалов или отделов, оформите их контакты отдельно.
- Ссылки на странички в социальных сетях. Они должны быть живыми и без накруток. Есть и требования к регулярности обновления. Ссылка на группу «Вконтакте», где вы постите раз в год, ничего не даст.
- Отсутствие рекламы. Здесь все просто – если вы сами что-то продаете и при этом рекламируете другие коммерческие сайты, это минус. То же самое с собственными всплывающими баннерами. Особенно сильно «Яндекс не любит popunder-баннеры.
- Возможность и удобство доставки товаров (для магазинов). Информация о доставке должна быть всегда на виду. Плюсом будет, если продублировать ее в карточках товаров. Обязательно укажите все способы, сроки, стоимость и регионы доставки, адреса пунктов самовывоза.
- Способы оплаты. Чем больше и разнообразнее, тем лучше.
- Подробные карточки товаров. В хорошую карточку входят информативные описания, возможность сравнения, блоки «похожие», видеообзоры, отзывы, рейтинги, информация о наличии, сопутствующие товары и так далее.
- Работающая служба поддержки клиентов. Это могут быть телефоны call-центра, разделы «Помощь», FAQ, форма заказа обратного звонка.
- Подключенный онлайн-консультант. Все просто – он должен быть и он должен работать.
- Скидки. Выгодные предложения ранжируются выше, поэтому если делаете скидку, укажите ее размер и срок окончания.
- Простое и запоминающееся доменное имя. Чем проще его запомнить и чем лучше оно связано с вашей тематикой, тем лучше.
- Короткие и логичные URL. Пользователь должен понимать, в каком разделе сайта оказался.
- Оптимальная средняя длина тега title. В сниппете отображается только 70 символов. В них нужно упаковать все, что нужно и не заспамить его ключами.
- Соответствие контента страницы заявленному title. Здесь все просто – если в тайтле написано, что на странице есть цены или видео, то и на странице они должны быть.
- Средняя вложенность страниц. Лишних категорий и разделов быть не должно.
Формула коммерческого ранжирования «Яндекса» уже научилась отличать технически хорошие сайты от технически плохих. Алгоритм умеет анализировать удобство сайта почти с человеческой точки зрения. Осталось только научить ее думать совсем как человек, чтобы она захватила весь мир. К этой цели «Яндекс» стремится давно и делает поразительные успехи. Может, через пару лет мы перестанем натыкаться в выдаче на сайты, которые выглядят так, будто 2002 год никогда не закончился и предлагают нам контент такого же качества.
semantica.in
как поставить машинное обучение на поток (пост #1) / Блог компании Яндекс / Хабр
Сегодня мы начинаем публиковать серию постов о машинном обучении и его месте в Яндексе, а также инструментах, которые избавили разработчиков поисковой системы от рутинных действий и помогли сфокусироваться на главном — изобретении новых подходов к улучшению поиска. Основное внимание мы уделим применению этих средств для улучшения формулы релевантности, и более широко — для качества ранжирования.
Качество поиска — это комплексное понятие. Оно состоит из множества взаимосвязанных элементов: ранжирования, сниппетов, полноты поисковой базы, безопасности и многих других. В этой серии статей мы рассмотрим только один аспект качества — ранжирование. Как многим уже известно, оно отвечает за порядок предоставления найденной информации пользователю.
Даже самая простая идея, которая может его улучшить, должна проделать сложный многошаговый путь от обсуждения в кругу коллег до запуска готового решения. И чем более автоматизированным (а значит быстрым и простым для разработчика) будет этот путь, тем быстрее пользователи смогут воспользоваться этим улучшением и тем чаще Яндекс сможет запускать такие нововведения.
Возможно, вы уже читали о платформе распределённых вычислений Yet Another MapReduce (YAMR), библиотеке машинного обучения Матрикснет и основном алгоритме обучения формулы ранжирования. Теперь мы решили рассказать и о фреймворке FML (friendly machine learning — «машинное обучение с человеческим лицом»). Он стал следующим шагом в автоматизации и упрощении работы наших коллег — поставил работу с машинным обучением на поток. Вместе FML и Матрикснет являются частями одного решения — технологии машинного обучения Яндекса.
Рассказывать о FML достаточно сложно, а сделать это мы хотим обстоятельно. Поэтому разобьём наш рассказ на несколько постов:
- Что такое ранжирование и какие задачи оно решает. Здесь мы расскажем о проблематике ранжирования и основных сложностях, возникающих в этой области. Даже если вы никогда не занимались этой темой, этого введения будет достаточно для понимания всего последующего материала. А уже знакомые с ранжированием смогут свериться с нами в используемой терминологии.
- Подбор формулы ранжирования. Вы узнаете о том, как FML стал конвейером по подбору формул (да-да, их много!), чтобы оперативно учитывать большой объём асессорских оценок и новых факторов при минимальном участии человека. А также о созданном в Яндексе кластере на GPU-процессорах, который вполне может войти в сотню самых мощных суперкомпьютеров в мире.Разработка новых факторов и оценка их эффективности. Как правило, публикации в сфере машинного обучения уделяют основное внимание самому процессу подбора формул, а разработку новых факторов обходят стороной. Однако сколько бы замечательной ни была технология машинного обучения, без хороших факторов ничего не получится. В Яндексе существует даже отдельная группа разработчиков, занятая исключительно их созданием. Здесь речь пойдёт о том, из чего состоит технологический цикл, в результате которого появляются новые факторы, и каким образом FML помогает оценить пользу от внедрения и себестоимость каждого из них.
- Мониторинг качества уже внедрённых факторов. Интернет постоянно меняется. И вполне возможно, что факторы, которые ещё несколько лет назад очень помогли поднять качество, на сегодняшний день утратили свою ценность и впустую расходуют вычислительные ресурсы. Поэтому мы расскажем о том, как FML поддерживает постоянную эволюцию, в которой слабые факторы погибают и уступают место сильным.Конвейер распределённых вычислений. Машинное обучение — лишь одна из задач, которые хорошо решает FML. Более широко его применяют для того, чтобы упростить работу с распределёными вычислениями на кластере в несколько тысяч серверов над большим массивом данных, меняющимся во времени. На сегодняшний день около 70% вычислений в разработке Яндекс.Поиска находится под управлением FML.Области применения и сравнение с аналогами. FML используется в Яндексе для машинного обучения целым рядом команд и для решения далёких от поиска задач. Мы полагаем, что наша разработка может пригодиться и коллегам по отрасли, имеющим дело с задачами машинного обучения, да и просто с расчётами на больших объёмах данных. Мы обозначим круг задач, для решения которых FML может оказаться полезным и за пределами Яндекса, и сравним его с аналогами, доступными на рынке. Мы также расскажем, как применение FML в CERN может открыть дорогу Нобелевской премии.
Что такое ранжирование и какую задачу оно решает
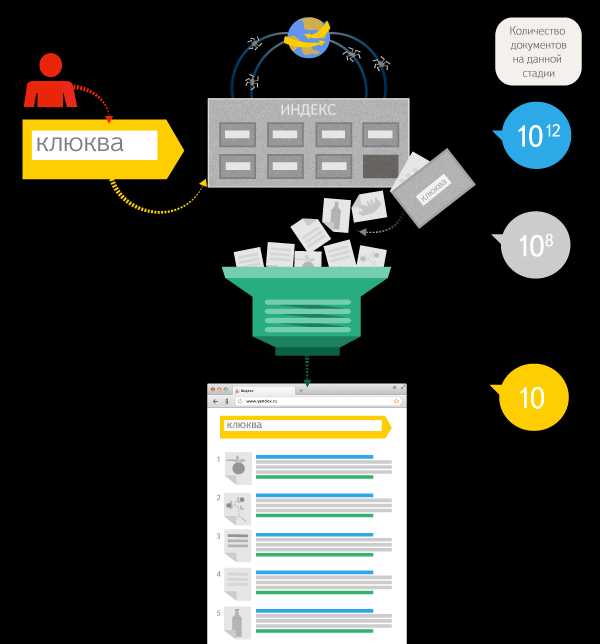 После того как поисковая система приняла запрос пользователя и нашла все подходящие страницы, она должна упорядочить их по принципу наибольшего соответствия запросу. Алгоритм, выполняющий эту работу, и называется функцией ранжирования (в СМИ её иногда называют формулой релевантности). Именно в том, чтобы выделить наиболее важные из найденных страниц и определить «правильный» порядок их выдачи, и заключается задача ранжирования. Его улучшение — первое и главное место, где используются FML и Матрикснет.
После того как поисковая система приняла запрос пользователя и нашла все подходящие страницы, она должна упорядочить их по принципу наибольшего соответствия запросу. Алгоритм, выполняющий эту работу, и называется функцией ранжирования (в СМИ её иногда называют формулой релевантности). Именно в том, чтобы выделить наиболее важные из найденных страниц и определить «правильный» порядок их выдачи, и заключается задача ранжирования. Его улучшение — первое и главное место, где используются FML и Матрикснет.Когда-то давно в Яндексе функция ранжирования выражалась одной единственной формулой, подобранной вручную. Её размер растёт экспоненциально (на графике шкала Y — логарифмическая).
Помимо того, что со временем формула грозила достичь неуправляемых размеров, появились и другие причины перехода от ручного подбора к машинному обучению. Например, в какой-то момент нам потребовалось иметь одновременно несколько формул, чтобы одинаковые запросы обрабатывались по-разному в зависимости от региона пользователя.
Формально в ранжировании, как и в любой задаче машинного обучения с учителем, нам нужно построить функцию, которая наилучшим образом соответствует экспертным данным. В ранжировании эксперты определяют порядок, в котором нужно показывать документы по конкретным запросам. Таких запросов десятки тысяч. И чем лучше, с точки зрения экспертных оценок, оказался порядок документов, сформированный формулой, тем лучшее ранжирование мы получили. Эти данные называются оценками и, как многие знают, готовятся отдельными специалистами — асессорами. Для каждого запроса они оценивают, насколько хорошо тот или иной документ отвечает на него.
Входными данными для обучаемой функции, по которым она должна определить порядок документов для любого другого запроса, выступают так называемые факторы — различные признаки страниц. Эти признаки могут как зависеть от запроса (например, учитывать, сколько его слов содержится в тексте страницы), так и нет (например, отличать стартовую страницу сайта от внутренних). Среди факторов, используемых для обучения, есть также признаки самого запроса, которые едины для всех страниц — к примеру, на каком языке задан запрос, сколько в нём слов, насколько часто его задают пользователи.
Машинное обучение использует обучающую выборку, чтобы установить зависимость между порядком страниц для запроса, полученным исходя из их оценки людьми, и признаками этих страниц. Полученная функция используется для ранжирования по всем запросам, независимо от наличия по ним экспертных оценок.
Для построения хорошей формулы ранжирования важно не только получить оценки релевантности, но и правильным образом отобрать запросы, по которым их делать. Поэтому мы берём такое их подмножество, которое бы наилучшим образом представляло интересы пользователей.
Существует несколько технологий получения асессорских оценок, и каждая из них даёт свой вид суждений. В данный момент в Яндексе асессоры оценивают релевантность документа запросу по пятибалльной шкале. Этот метод основан на методологии Cranfield II. В других задачах мы используем и иные виды экспертных данных — например, в классификаторах могут применяться бинарные оценки.
Почему стандартные методики неприменимы в ранжированииОднако, даже собрав достаточное число оценок и рассчитав для каждой пары (запрос + документ) набор факторов, построить ранжирующую функцию стандартными методами оптимизации не так просто. Основная сложность возникает из-за кусочно-постоянной природы целевых метрик ранжирования (nDCG, pFound и т.п.). Это свойство не позволяет использовать здесь, например, известные градиентные методы, которые требуют дифференцируемости функции, которую мы оптимизируем. Существует отдельная научная область, посвященная метрикам ранжирования и их оптимизации — Learning to Rank (обучение ранжированию). А в Яндексе есть специальная группа, которая занимается реализацией и совершенствованием различных методов решения этого достаточно узкого, но очень важного для поиска класса оптимизационных задач. Итак, функция ранжирования строится по набору факторов и по обучающим данным, подготовленным экспертами. Её построением и занимается машинное обучение — в случае Яндекса библиотека Матрикснет. В следующих постах мы расскажем о том, откуда берутся поисковые факторы, и как всё это связано с FML.habr.com
как ранжироваться по тысячам ключевых слов
Посмотрите внимательно на следующие сайты и их показатели:
Что общего у этих двух сайтов? Разное количество ссылок, разный ссылочный профиль, разные ранги и т.д. - казалось бы, у них нет ничего общего, кроме одного показателя: огромное количество ключевых слов, по которым они ранжируются поисковыми системами.
Что они сделали для того, чтобы достичь таких показателей?
Все начинается с поиска подходящих ключевых слов.
Как занимаются этим большинство маркетологов и специалистов по поисковому продвижению? Они используют инструменты вроде SEMRush или Ubersuggest для подбора ключевых слов и вводят ключевые слова по типу “SEO” или “Интернет-маркетинг”. Как результат, они получают списки из тысяч ключевых слов, подходящих для этой тематики.
И как только ключевые слова будут собраны, маркетологи начинают делать все то же, что и другие - выстраивать сайт и создавать контент вокруг этих ключей.
Звучит знакомо, не правда ли? Это так, поскольку именно такому способу продвижения и учат большинство агентств и специалистов.
Что не правильно в этом процессе?
Дело в том, что этот процесс напоминает по своей сути карточную игру. Вы не знаете наверняка, сможете ли вы хорошо ранжироваться по этим ключам, и хуже того - вы не можете быть наверняка уверены, что эти ключи приведут вам клиентов и повысят продажи.
К счастью, у нас есть гайд, который поможет ранжироваться по тысячам ключевых слов и даже более того - поможет выбрать именно те ключевые слова, по которым будет переходить только качественный, конвертируемый трафик.
Далее - четыре составляющих идеально SEO формулы для ранжирования, которая подойдет практически любому сайту.
1. Фокусируйтесь на страницах, которые приносят прибыль
Использование только правильных ключевых слов не гарантирует получение прибыли.
Если вы хорошо ранжируетесь по статье с низкой конверсией, вы получите хороший трафик, но этот трафик будет нерелевантным и потому не принесет высокой прибыли.
Вместо этого ориентируйтесь на страницах, которые потенциально способны принести не столько трафик, сколько хорошую конверсию. К примеру, это может быть страница регистрации, покупки и т.д. Мы рекомендуем ориентироваться на такие страницы, как:
- Страницы описания товара/услуги;
- Страница регистрации;
- Страницы с контентом, которые ведут на вышеперечисленные страницы.
2. Изучите информацию в Google Search Console
После того, как вы перейдете в GSC, вам необходимо пройти по пути: Search Traffic >> Search Analysis. Вы получите информацию о трафике следующего вида:
Далее выполните сортировку страниц по количеству кликов и посмотрите информацию по странице, которая имеет наибольшее число кликов и наибольший CTR в разделе “Запросы”. Вы увидите информацию о поисковых запросах, которые приводят трафик на ваш сайт.
Далее выгрузите полученные данные в CSV-формате и откройте их в Excel - они будут выглядеть следующим образом:
Обратите внимание на слова с наибольшей конверсией, поскольку именно эти ключевики имеют наибольший потенциал для вашего сайта.
Если эти слова релевантны к продукту или услуге, которую вы предлагаете, разместите их в тайтле вашего сайта.
Конечно, вы не разместите все ключи в тайтле страницы, поскольку он ограничен 60 символами, но ориентируясь на наиболее релевантные ключи и запросы, вы можете выбрать лишь самые подходящие.
Аналогичная ситуация и для мета-тега description - он позволяет разместить уже 156 символов, поэтому тут можно включить еще большее количество релевантных ключевых слов.
Вернемся к нашей таблице - в ней вы должны провести анализ ссылок по показателям количества кликов, средней позиции и CTR, после чего выбрать те слова, которые являются оптимальными и наиболее перспективными по имеющимся показателям.
Проведя сортировку, вы можете ориентироваться на них в дальнейшем и продвигать сайт именно по ним.
3. Добавляйте релевантные (схожие) ключи
Как и в предыдущем случае, перейдите в Google Search Console и пройдите по пути: Search Traffic >> Search Analysis. Вы получите информацию о трафике, как и в предыдущем пункте.
Далее соберите 10 ключевых слов, которые приносят больше всего трафика на сайт, после чего - перейдите в Google, введите ключи вручную и перейдите на самый низ страницы поиска, где увидите релевантные ключи, которые пользователи вводят в поиске:
В данном случае использование этих ключевых слов и/или фраз будет вам только на пользу: во-первых, они принесут вам куда больше трафика, во-вторых - вы уже ранжируетесь по основному ключевому слову, поэтому вам будет намного легче ранжироваться по схожим запросам.
Подбирая ключи, вы можете значительно расширить кластер запросов. Так, выбрав только 8 схожих запросов для одного ключевого слова, для 10 ключей вы получите уже 80 дополнительных ключевых слов/фраз. Они, в свою очередь, могут использоваться по аналогичному принципу в дальнейшем - таким образом, вы будете расширять кластер запросов, по которому вас находят в поисковой системе.
4. Выводите в ТОП-10 ключи, которые сейчас в ТОП-20
Как известно, 91% посетителей никогда не переходят на 2 страницу поиска. Иначе говоря, 2 страница поиска - это место, где еще есть шанс получить трафик, но он настолько незначителен, что очень часто о таких страницах попросту забывают.
С одной стороны, такие страницы действительно вряд ли соберут трафик и дадут хорошую конверсию, если их оставить на прежних позициях.
С другой стороны, если вы находитесь на 11-12-13 позиции по запросу, который способен приносить хороший трафик и конверсию, то вам необходимо “подтянуть” эти ключи для попадания в ТОП-10 по запросу.
Главный нюанс в данном случае - убедиться в том, что ключи, по которым вы хотите ранжироваться выше, способны увеличить ваши продажи, количество лидов и конечную прибыль.
Вышеприведенный способ работы с ключевыми словами достаточно сложный и громоздкий по сравнению с классическими методами отбора ключевых слов. Но вместе с этим данный способ работает, причем работает хорошо.
Создание нового контента - это хорошо, но лучше - усовершенствование контента и материалов, которые уже приносят наибольший трафик.
spyserp.com
Алгоритмы и технологии Яндекса. Как работает поиск?
В прошлой статье мы рассмотрели наиболее интересные технологии Яндекса, применяемые для обеспечения качественного поиска в интернете. Теперь разберем более подробно, как устроена поисковая машина Яндекса. Что же происходит после того, как пользователь вводит запрос в строку поиска?
MatrixNet
Технология поиска Яндекс устроена сложно. Поисковая выдача формируется на основе формулы ранжирования, построенной на нескольких сотнях факторов, каждый из которых может включаться с индивидуальным коэффициентом, а также в различных комбинациях с прочими факторами.
Формула ранжирования — это функция, построенная на множестве факторов, при помощи которых определяется релевантность сайта поисковому запросу и его очередность в выдаче
Для обеспечения качественного поиска факторы и коэффициенты в формуле ранжирования должны регулярно обновляться. Построением такой формулы в Яндексе занимается MatrixNet (Матрикснет) - метод машинного обучения, введенный Яндексом в 2009 году с целью сделать поиск более точным.
«Матрикснет» — метод машинного обучения, с помощью которого подбирается формула ранжирования Яндекса. Входными данными являются факторы и обучающие данные, подготовленные асессорами (экспертными сотрудниками Яндекса).
Основная его особенность заключается в том, что он устойчив к переобучению и позволяет построить сложную формулу ранжирования с десятками тысяч коэффициентов, которая учитывает множество различных факторов и их комбинаций без увеличения количества асессорских оценок и опасности найти несуществующие закономерности.
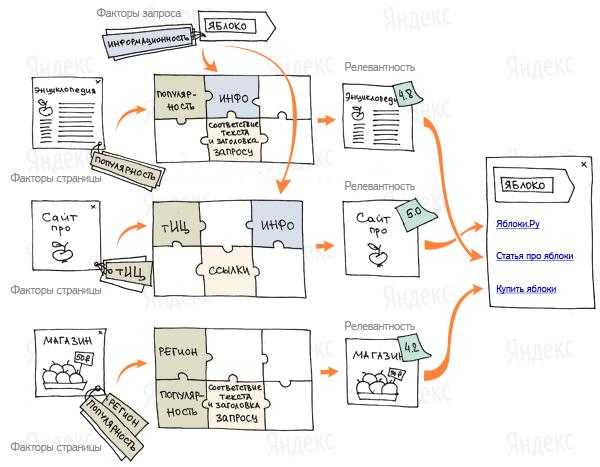
Архитектура поиска
Ежедневно пользователи посылают Яндексу десятки миллионов запросов. Для формирования ответа под какой-нибудь один запрос поисковой машине необходимо проверить миллионы документов, определить их релевантность и упорядочить при помощи формулы ранжирования так, чтобы наиболее подходящие страницы сайтов оказались вверху выдачи. Для ускорения этого процесса Яндекс использует заранее подготовленные данные — индекс.
Индекс — база поисковой системы, содержащая сведения о запросах и их позициях на страницах сайтов в сети. Индекс формируется поисковым роботом, который обходит сайты и собирает информацию с заданной периодичностью.
Размер индекса в поиске огромен, чтобы быстро обработать такой объем данных используются тысячи серверов, объединенные в кластеры.
После того, как пользователь вводит запрос в строку поиска, он анализируется компьютерной системой «Метапоиск» на предмет региональной привязки, класса запроса и т.д. Там же запрос проходит лингвистическую обработку. Далее «Метапоиск» проверяет кэш на наличие поискового ответа по данному запросу. По часто задаваемым запросам результаты поиска хранятся в памяти поисковика в течение какого-то времени, а не формируются каждый раз заново.
«Метапоиск» — это программа, которая принимает и разбирает поисковые запросы, передает их соответствующим «Базовым поискам», обеспечивает агрегацию и ранжирование найденных документов, а также производит кеширование части ответов, которые впоследствии возвращаются пользователям без обращения к «Базовому поиску».
Если же ответ не найден, «Метапоиск» передает запрос другой компьютерной системе – «Базовому поиску». Там же хранится поисковая база Яндекса (индекс). Так как это огромный объем данных, индекс разбивается на части, которые хранятся на разных серверах. Такой подход позволяет производить поиск одновременно по нескольким частям базы данных, что заметно ускоряет процесс. Каждый сервер имеет несколько копий, это дает возможность распределять нагрузку и не терять данные. При передаче запроса «Метапоиск» выбирает наименее загруженные сервера «Базового поиска».
«Базовый поиск» обеспечивает поиск по всей части индекса (базе поисковой системы), содержащей сведения о запросах и их позициях на страницах сайтов в сети.
Каждый сервер базового поиска отдает список документов, содержащих поисковый запрос, обратно в «Метапоиск», где они ранжируются по сформированной «Матрикснетом» формуле. Результаты такой работы мы видим на странице выдачи.

Использование индекса в качестве источника данных, многостадийный подход к формированию ответа и дублирование данных позволяют Яндексу обеспечивать поиск за доли секунды.
Оценка качества поиска
Помимо скорости поиска не менее важно и его качество. Для этого у Яндекса существует система оценки качества поиска, которая также помогает улучшить это качество.
Релевантность – свойство документа, определяющее степень его соответствия поисковому запросу. Вычисляется на основе формулы ранжирования.
Релевантность документа поисковому запросу вычисляется на основе формулы ранжирования – функции от множества факторов. Сейчас в Яндексе более 800 различных факторов, таких как возраст сайта, региональная привязка, взаимодействие пользователей с сайтом (поведенческий фактор), уникальность контента и т.д. В случае с персонализированным поиском релевантность документа зависит непосредственно от предпочтений пользователя, отправившего запрос.
Формула ранжирования постоянно обновляется, так как меняются потребности пользователей и индекс поисковика. Для ее обновления применяется методы машинного обучения. На основе экспертных данных выявляются зависимости между характеристиками документов и порядком их включения в выдачу, которые вносятся в формулу для ее корректировки.
Оценка качества поиска — удовлетворенность пользователей результатами поиска и порядком их следования.
Экспертными данными для машинного обучения являются оценки асессоров, которые также применяются для оценки качества поиска.
Асессоры — специалисты, оценивающие по ряду критериев релевантность представленного в выдаче документа поисковому запросу.
Асессоры оценивают поисковые результаты в выдаче по ряду критериев, которые позволяют определить, присутствует ли на сайте полный ответ на запрос, является ли сайт брендовым, не переспамлен ли текстовый контент и т.д. В основном асессоры работают с наиболее популярными поисковыми запросами (порядка 150 тыс.), при этом оцениваются первые 30 позиций выдачи. Это наиболее авторитетная оценка, так как ее проводит человек, а не машина, т.е. сайт получает оценку с точки зрения пользователя.
Актуализация и улучшение правил ранжирования в комплексе с оценкой качества поиска помогают Яндексу формировать выдачу, соответствующую ожиданиям пользователей.
www.iseo.ru
Алгоритм текстового ранжирования Яндекса на РОМИП-2006: актуальность правил
SEO – сфера, в которой все крайне подвижно. Настолько подвижно, что если намеренно не следить за трендами, запросто можно упустить из виду что-то важное.
В течение всего одного месяца может произойти множество изменений. Буквально на прошлой неделе, 23 марта, Яндекс запустил алгоритм – Баден-Баден, направленный на борьбу с переоптимизацией текстов. Такие тексты никуда не годятся – в них нет пользы, что уж говорить о смысле: они не нравятся ни людям, ни умным поисковикам.
Эта новость нагнала жути многим владельцам сайтов, ведь подобный спам можно найти чуть ли не на каждом втором ресурсе. Неужели SEO теперь – это прошлый век?
Прошлый век – это использование огромного количества ключевых слов как придется и где придется – бездумно.
Как мы уже выяснили, без перемен в нашей сфере никуда. Но в SEO также есть и своя так называемая классика: то, что будет важным и неизменным всегда. Или как минимум 10 лет. Ведь 10 лет для seo – целая вечность.
В связи с запуском Баден-Баден актуальной сегодня становится тема текстового ранжирования в поисковиках. Подробно описано это явление в статье для Российского семинара по Оценке Методов Информационного Поиска (далее РОМИП-2006). Несмотря на то, что алгоритмы значительно усложнились и теперь предъявляют гораздо больше требований, база осталось базой – все так же неизменной. В результате исследования сформировались, по сути, слагаемые, которых можно и нужно придерживаться по сей день, и вряд ли они поменяются еще лет 10 точно.
Суть исследования заключалась в следующем: на основании факторов определения текстовой релевантности страница-запрос пользователя был создан с нуля экспериментальный поиск ATR – для улучшения ранжирования документов в Яндексе. Цель ATR – довести до совершенства соответствие документов запросу.
В эксперименте для каждого запроса вычисляли значение документа – числовой показатель соответствия документа запросу.
Вот так выглядит универсальная формула ранжирования:

В формулу включены самые важные факторы ранжирования – слагаемые, про которые подробнее расскажем ниже.
Список показателей-факторов текстовой релевантности, учтенных в формуле статьи РОМИП-2006
Всего их 5:
- Частотность слова (леммы – основной формы слова) по тексту.
- Употребление пар слов из запроса.
- Использование всех слов запроса (более редкие слова дают плюс к общему показателю).
- Использование прямого вхождения для длинных запросов.
- Использование предложений, в которых содержится значительное количество слов запроса.
Рассмотрим каждый из них подробнее.
1. Частота встречаемости слов (Wsingle)
Показатель, который больше всего влияет на результаты выдачи. Здесь используется понятие «лемматизация» – приведение всех словоформ из текста к исходной.
Например:Красная, красную, красное → красныйКупивший, купите, купленный → купитьКровати, кровать, кроватью → кровать
Соответственно, результат поиска без лемматизации будет значительно отличаться от результата поиска с учетом данного параметра.
Сегодня это обязательно учитывается при проверке тошноты текста любым из сервисов. Сразу видно, какие слова были приоритетны при продвижении и как можно повлиять на оптимизацию: добавить либо убрать из текста ключи.
Вот пример из сервиса Advego.ru. Заходим в раздел «Seo-анализ текста» и вставляем свой текст в пустое окно. Ниже смотрим таблицу «Слова»: там отображаются все леммы, их количество и частота.

Напоминаем, что мы рекомендуем придерживаться показателя тошноты в 10% по «Адвего». На 2000 символов – 3 ключевых слова в естественном употреблении, примерная повторяемость каждого ключа – 2-3 раза.
Логичный вывод: переспам, особенно по прямым вхождениям,– зло. Поисковики уже в 2006 году умели понимать намерения авторов текстов и различать нелепо вписанные запросы. Что говорить о сегодняшнем дне, когда Яндекс и Google перешли на новый уровень с использованием искусственного интеллекта – видят смысл и пользу текста.
Например, новый алгоритм Баден-Баден Яндекса жестоко наказывает за переоптимизацию: сайтам, злоупотребляющим ключевыми словами, грозит просадка на 10-40 позиций, в зависимости от конкуренции по запросу. Алгоритм долго тестировали, поэтому обмануть искусственный интеллект не получится. Верный выход – руководствоваться смыслом при написании любого текста, расширять словарный запас синонимами, не забывать про УТП, осваивать приемы LSI-копирайтинга и дорабатывать/переписывать тексты по его канонам. Как было указано в официальном оповещении Яндекса: «Думайте о пользователях, пишите для людей и «Баден-Баден» не тронет ваш сайт».
Примеры текстов, когда частота встречаемости слов в документе превышена:
Сразу видно, что тексты написаны ради ключевых слов. Ничего полезного для потенциального покупателя в них просто нет.
Было бы как минимум странно, если от своего собеседника в обычной жизни мы бы услышали подобную фразу: «Глядя на картины маслом моря, можно получить моральное успокоение» =). Поэтому прежде чем вписать ключ в предложение, подумайте, сказали бы вы так своему клиенту при личном общении.
Хороший пример:

Нет никаких сомнений, что здесь ключевые слова вписаны естественно. «Оказываем содействие по организации обучения в Китае» – подозрений не возникает.
Пишите естественные тексты. 10 ключевых слов на 500 символов – это перебор. Спамные фразы, нелепо вписанные ключи не вызывают доверия даже у поисковиков с искусственным интеллектом, что говорить про здравомыслящего человека.
Особый вес имеет правильное вхождение ключевых слов в первый абзац, title, description, h2-h4
Важно не только количество ключей, но и их расположение. Как вы уже поняли из подзаголовка, значительный вес имеют слова, находящиеся в первом абзаце текста и тегах h2-h4. В тегах и заголовках лучше располагать ключи так же в начале.
Мы рекомендуем руководствоваться следующим алгоритмом:
- Title – название страницы: выбираем самое частотное ключевое слово и вставляем его в прямом вхождении в начало предложения. Лучше будет, если использовать 2 ключа. Это если объем позволяет. Но и тут вновь не забываем про естественность фразы, не спамим.
<title>Питомник бенгальских кошек в Москве. Цена бенгальской кошки от 20 000 руб. Тел. +7 (925) 420-32-80</title>
- Description – описание страницы, в нем используем все 3 ключа. Тоже не спамим, пишем красиво, естественно. В начало помещаем второй по частотности запрос.
<meta name="description" content="Бенгальская кошка в Москве. Питомник бенгальских кошек Бенвояж предлагает котят с родословной. Вы можете купить бенгальскую кошку или кота с общительным характером. Цена бенгальской кошки – от 20 000 рублей. Тел. +7 (925) 420-32-80">
- Заголовки.
Для первого заголовка тоже выбираем самый частотный ключ. Главное, чтобы он не дублировал title, если вы не преследуете определенную цель – получение быстрых ссылок.
<h2>Питомник бенгальских кошек «Бенвояж»</h2><strong>Заведите себе верного и активного друга</strong>
<h3>Купите бенгальскую кошку в «Бенвояж»</h3><strong>Необычные и общительные питомцы</strong>
К заголовку с ключом обязательно придумываем оригинальный подзаголовок. Ведь все любят красивые слоганы, привлекающие внимание. Это и от клиентов плюс, и от поисковых систем с их искусственным интеллектом.
- Ну и про первый абзац не забываем, сюда тоже обязательно помещаем ключевые слова.

«Меня зовут Оксана, я русскоговорящий гид во Франции» – тоже все прекрасно, никакого намека на спамность.
2. Вхождение пар слов из запроса (Wpair)
Рабочий прием, но используем его по возможности. Комбинируем и объединяем словосочетания.

Проще говоря, используйте ключевые слова в словосочетаниях. Постарайтесь сделать несколько разных сочетаний ключевого слова. Это расширит охват аудитории и сделает страницу более релевантной тем запросам, которые попадут в ваши пары.
3-4. Наличие всех слов запроса в тексте и наличие точного вхождения фразы для многословных запросов (Wphrase+ Wallwords)
Здесь нужно сосредоточиться на семантическом ядре, учитывать новые поисковые запросы и их обновление. Необходимы слова из потенциальных запросов, которые, возможно, в дальнейшем будут популярными. Допустимо ориентироваться на конкурентов из топа выдачи.
Для экспериментального поиска использовались все слова из поисковой фразы, поскольку это давало + 0,2 к ранжированию. Если этого правила не придерживаться, бонус уменьшится до 0,03. Но, вероятно, этот показатель не учитывается в основном поиске.
Тут вновь важна разнообразность: одинаковых форм слова должно быть как можно меньше.
Также не забываем один раз употребить фразу в точном вхождении, как мы уже говорили, желательно где-нибудь в начале текста.
5. Наличие предложений, содержащих значительное количество слов запроса (Whalfphrase)
Вдобавок учитывается количество предложений в тексте, содержащих значительное количество слов запросов – больше половины всех слов, учет части запроса. Не забываем, что в одном предложении они должны быть связаны по смыслу, а не употребляться абы как.
Чтобы не усложнять себе задачу при написании и не задумываться над каждым ключом, удобнее сначала написать сам текст, а потом уже подумать, как красиво вставить ключ, далее проанализировать все словоформы и вхождения. Потом проверить себя по списку, все ли условия выполнены. Но без фанатизма. Ведь тексты в первую очередь пишутся для людей, а потом только для машин. Тем более машины с каждым днем становятся все умнее – уже много сказано об LSI-копирайтинге, подавляющее большинство активно его использует.
Когда наши копирайтеры пишут тексты для клиентских сайтов, обязательно учитывают все эти параметры. Это само собой разумеющееся, прям как таблица умножения. Держим в голове чек-лист, которого всегда придерживаемся.
Убедитесь сами, посмотрев примеры и результаты наших текстов.
Если нужна помощь в написании или хотите узнать, соответствует ли текст на вашем сайте требованиям поисковых систем и правилам копирайтинга – обращайтесь, дадим рекомендации или напишем новый качественный текст.
© 1PS.RU, при полном или частичном копировании материала ссылка на первоисточник обязательна.
1ps.ru
как поставить машинное обучение на поток (пост #2) / Блог компании Яндекс / Хабр
Мы продолжаем серию публикаций о нашем фреймворке FML, который автоматизировал работу с машинным обучением и позволил разработчикам Яндекса использовать его в своих задачах проще и чаще. Предыдущий пост рассказывал о том, что такое функция ранжирования и как мы научились строить её, имея на входе лишь достаточно большое число оценок от асессоров и достаточно разнообразный набор признаков (факторов) документов по большому количеству запросов.Из этого поста вы узнаете:
- Почему нам нужно подбирать новую формулу ранжирования очень часто, и как именно нам в этом помогает FML;
- Как мы разрабатываем новые факторы и оцениваем их эффективность.
Подбор формулы ранжирования
Одно дело — подобрать формулу один раз, а совсем другое — делать это очень часто. И мы расскажем о причинах того, почему в наших реалиях так необходимо второе.Как уже было упомянуто, интернет быстро меняется и нам нужно постоянно повышать качество поиска. Наши разработчики непрерывно ищут, какие новые факторы могли бы нам помочь в этом. Наши асессоры каждый день оценивают тысячи документов, чтобы оперативно обучать алгоритмы новым видам закономерностей, появляющимся в интернете, и учитывать изменения в полезности уже оцененных ранее документов. Поисковый робот собирает в интернете массу свежих документов, что постоянно меняет средние значения факторов. Значения могут изменяться даже при неизменных документах, так как алгоритмы расчета факторов и их реализация постоянно совершенствуются.
Чтобы оперативно учитывать в формуле ранжирования этот поток изменений, нужен целый технологический конвейер. Желательно, чтобы он не требовал участия человека или был для него максимально простым. И очень важно, чтобы внесение одних изменений не мешало оценке полезности других. Именно таким конвейером и стал FML. В то время, как Матрикснет выступает «мозгом» машинного обучения, FML является удобным сервисом на его основе, использование которого требует гораздо меньше специальных знаний и опыта. Вот за счёт чего это достигается.
Во-первых, под каждую конкретную задачу, с которой к нам приходит разработчик, FML рекомендует параметры запуска Матрикснета, наилучшим образом соответствующие условиям и ограничениям задачи. Сервис сам подбирает настройки, оптимальные для конкретного объёма оценок — например, помогает выбрать целевую функцию (pointwise или pairwise) в зависимости от размера обучающей выборки.
Во-вторых, FML обеспечивает прозрачную многозадачность. Каждая итерация подбора формулы — это многочасовой расчёт, требующий полной загрузки нескольких десятков серверов. Как правило, одновременно происходит подбор десятка разных формул, а FML управляет нагрузкой и обеспечивает каждому разработчику изоляцию его расчётов от расчётов коллег, чтобы они не мешали друг другу.
В-третьих, в отличие от Матрикснета, который нужно запускать вручную, FML обеспечивает распределённое выполнение ресурсоёмких задач на кластере. Это включает и использование всеми единой и самой свежей версии библиотек машинного обучения, и раскладку программы на все машины, и обработку возникающих сбоев, и сохранение уже проведённых расчётов, и верификацию результатов в случае перезапуска вычислений.
Наконец, мы воспользовались тем, что на вычислительно сложных задачах можно получить весьма существенный выигрыш в производительности, если запускать их на графических процессорах (GPU) вместо процессоров общего назначения (CPU). Для этого мы адаптировали Матрикснет под GPU, за счет чего получили более чем 20-кратный выигрыш в скорости расчётов на единицу стоимости оборудования. Особенности нашей реализации алгоритма построения деревьев решений позволяют нам использовать высокую степень параллелизма, доступную на GPU. Благодаря тому, что мы сохранили программные интерфейсы, которыми пользуется FML, нам удалось предоставить коллегам, работающим над факторами, новые вычислительные мощности, не изменяя привычных процессов разработки.
Несколько слов про GPUВообще преимущество процессоров GPU над CPU раскрывается на задачах с большой долей вычислений с плавающей точкой, и машинное обучение среди них ничем не выделяется. Вычислительная производительность измеряется в IOPS для целочисленных вычислений и FLOPS для вычислений с плавающей точкой. И, если вынести за скобки все издержки на ввод-вывод, включая общение с памятью, именно по параметру FLOPS графические процессоры давно ушли далеко вперёд по сравнению с обычными. На некоторых классах задач выигрыш в производительности по сравнению с процессорами общего назначения (CPU) составляет сотни раз.Но именно потому, что далеко не все распространённые алгоритмы подходят под вычислительную архитектуру GPU и не всем программам необходимо большое число вычислений с плавающей точкой, вся отрасль продолжает использовать CPU, а не переходит на GPU.

Разработка новых факторов и оценка их эффективности
Факторы в ранжировании играют даже более важную роль, чем умение подбирать формулу. Ведь чем более разнопланово признаки будут различать разные документы, тем более действенной сможет быть функция ранжирования. В стремлении повышать качество поиска мы постоянно ищем, какие новые факторы могли бы нам помочь.Их создание — очень сложный процесс. Далеко не любая идея выдерживает в нём проверку практикой. Иногда на разработку и настройку хорошего фактора может уйти несколько месяцев, а процент гипотез, подтверждённых практикой, крайне невелик. Как у Маяковского: «В грамм добыча, в год труды». За первый год работы FML для десятков тысяч проверок различных факторов с разными комбинациями параметров были допущены к внедрению лишь несколько сотен.
Долгое время в Яндексе для работы над факторами нужно было, во-первых, глубоко понимать устройство поиска вообще и нашего в частности и, во-вторых, иметь неплохие знания о машинном обучении и информационном поиске в целом. Появление FML позволило избавиться от первого требования, ощутимо снизив тем самым порог входа в разработку факторов. Количество специалистов, которые теперь могут ею заниматься, выросло на порядок.
Но в большом коллективе потребовалась прозрачность процесса разработки. Раньше каждый ограничивался лишь проверками, которые сам считал достаточными, а качество измерял «на глазок». В результате получение хорошего фактора оказывалось скорее предметом искусства. А если гипотеза фактора отвергалась, то по прошествии времени нельзя было ознакомиться с тестами, по которым было принято решение.
С появлением FML разработка факторов стала стандартным, измеримым и контролируемым процессом в большом коллективе. Появилась и перекрёстная прозрачность, когда все смогли увидеть, что делают коллеги, и возможность контролировать качество проведённых ранее экспериментов. Кроме того, мы получили такую систему контроля качества производимых факторов, которая допускает плохой результат с гораздо меньшей вероятностью, чем на ведущих мировых конференциях в области информационного поиска.
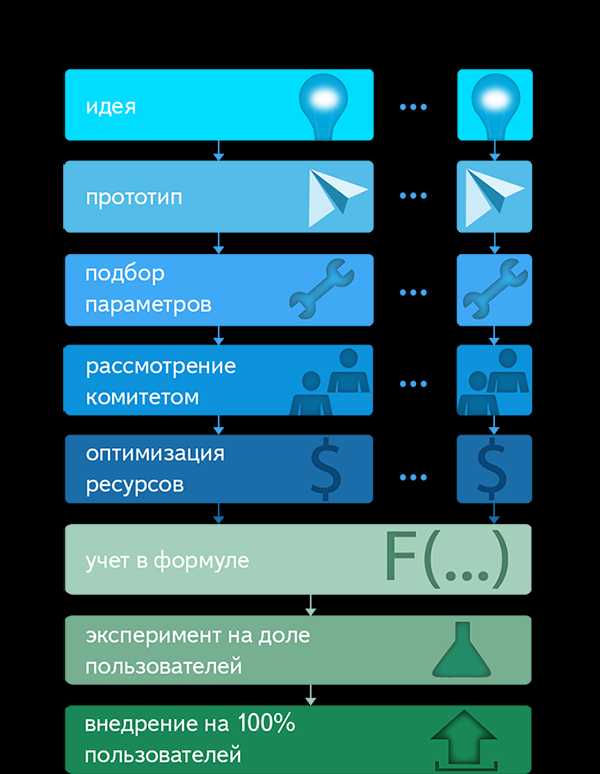
Для оценки качества фактора мы делаем следующее. Разбиваем (каждый раз новым случайным образом) множество имеющихся у нас оценок на две части: обучающую и тестовую. По обучающим оценкам мы подбираем две формулы — старую (без тестируемого фактора) и новую (с ним), а по тестовым — смотрим, какая из этих формул лучше. Процедура повторяется много раз на большом количестве разных разбиений наших оценок. В статистике этот процесс принято называть перекрёстной проверкой (cross-validation). Нам она позволяет убедиться в том, что качество новой формулы лучше старой. В машинном обучении такой метод известен как уменьшение размерности с использованием wrappers. Если оказывается, что в среднем новая формула даёт заметное улучшение качества по сравнению со старой, новый фактор может стать кандидатом на внедрение.
Но даже если фактор доказал свою полезность, нужно понять, какова цена его внедрения и использования. Она включает в себя не только время, которое разработчик потратил на проработку идеи, его реализацию и настройку. Многие факторы необходимо рассчитывать непосредственно в момент поиска — для каждого из тысяч документов, найденных по запросу. Поэтому каждый новый фактор — это потенциальное замедление скорости ответа поисковой системы, а мы следим, чтобы она оставалась в очень жёстких рамках. Это значит, что внедрение каждого нового фактора должно быть обеспечено увеличением мощности кластера, отвечающего на запросы пользователей. Есть и другие аппаратные ресурсы, которые нельзя расходовать безгранично. Например, себестоимость хранения в оперативной памяти каждого дополнительного байта на документ на поисковом кластере составляет порядка 10 000 долларов в год.
Таким образом, нам важно отбирать из многих потенциальных факторов только те, у которых соотношение прироста качества к издержкам на оборудование будет самым лучшим — и отказываться от остальных. Именно в измерении прироста качества и оценке объёма дополнительных затрат и состоит следующая после подбора формул задача FML.
Цена измерения и его точностьПо нашей статистике, на оценку качества факторов перед их внедрением уходит существенно больше вычислительного времени, чем на подбор самих формул. В том числе потому что формулу ранжирования нужно многократно переподбирать на каждый фактор. Например, за прошлый год примерно на 50 000 проверок было потрачено около 10 млн машиночасов, а на подбор формул ранжирования — около 2 млн. То есть большая часть времени кластера тратится именно на проведение исследований, а не на выполнение регулярных переподборов формул.Как на любом зрелом рынке, каждое новое улучшение даётся гораздо тяжелее, чем предыдущее, и каждая следующая «девятка» в качестве стоит кратно дороже предыдущей. У нас счёт идёт на десятые и сотые доли процента целевой метрики качества (в нашем случае это pFound). В таких условиях приборы измерения качества должны быть достаточно точными, чтобы уверенно фиксировать даже такие малые изменения.
Говоря про аппаратные ресурсы, мы оцениваем три составляющих: вычислительную стоимость, объём диска и объём оперативной памяти. Со временем у нас даже выработались «разменные курсы»: насколько мы можем ухудшить производительность, сколько байт диска или оперативной памяти готовы заплатить за повышение качества на 1%. Расходование памяти оценивается экспериментально, прирост качества берётся из FML, а уменьшение производительности оценивается по результатам отдельного нагрузочного тестирования. Тем не менее, некоторые аспекты не удаётся оценивать автоматически — например, не привносит ли фактор сильную обратную связь. По этой причине существует экспертный совет, который имеет право вето на внедрение фактора.Когда приходит время внедрения формулы, построенной с использованием новых факторов, мы проводим A/B-тестирование — эксперимент на небольшом проценте пользователей. Он нужен, чтобы убедиться в том, что новое ранжирование «нравится» им больше, чем текущее. Окончательное решение о внедрении принимается на основе пользовательских метрик качества. В каждый момент времени в Яндексе проводятся десятки экспериментов, и мы стараемся сделать этот процесс незаметным для пользователей поисковой системы. Таким образом мы добиваемся не только математической обоснованности принимаемых решений, но и полезности нововведений на практике.
Итак, FML позволил поставить на поток разработку факторов в Яндексе и дал возможность их разработчикам понятным и регламентированным образом и относительно небольшими усилиями получать ответ на вопрос о том, достаточно ли хорош новый фактор для рассмотрения к внедрению. О том, как мы следим за тем, чтобы качество фактора со временем не деградировало, расскажем в следующем — последнем — посте. Из него же вы узнаете о том, где ещё применима наша технология машинного обучения.
habr.com
Факторы ранжирования Яндекс
Формула ранжирования
Формула ранжирования строится на различных комбинациях нескольких сотен факторов, основные из которых:
Текстовые
- Соответствие запроса и текста на странице сайта.
- Тематическое соответствие.
- Язык и т.д.
Ссылочные
- Цитируемость сайта.
- PageRank.
- Аналоги текстовых факторов по текстам ссылок.
Статические
- Популярность запроса.
- Популярность сайта.
Географические
Временные
Далее поисковая машина сравнивает сайты по этим факторам и определяет максимально релевантные ресурсы. Это и называется формулой ранжирования Яндекса, которая подбирается при помощи Матрикснета — метода машинного обучения.
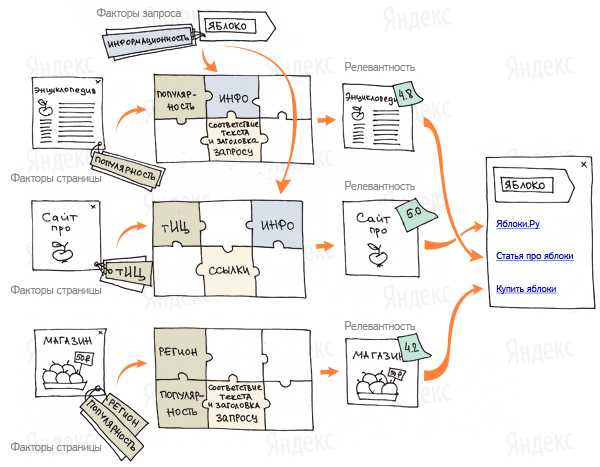
Факторы ранжирования
Итак, из сотен факторов ранжирования Яндекса рассмотрим основные.
Возраст сайта
При ранжировании Яндекс учитывает время существования страниц сайта (именно сайта, а не домена). Почему возраст так важен? Чем старше сайт, тем больше о нем информации в базе данных поисковика, страницы таких сайтов быстрее индексируются, доверие к таким ресурсам естественно выше. О новых сайтах (менее 6 месяцев) Яндекс почти ничего не знает и отправляет их в «песочницу» наращивать свою авторитетность. Именно поэтому молодым сайтам так сложно попасть в ТОП выдачи, особенно по высокочастотным запросам.
О том, как правильно продвигать молодые сайты, читайте в нашей статье «Стратегия продвижения нового сайта. Когда будет ТОП-10 и трафик?».
Правильная привязка сайта к региону, наличие контактной информации
Примерно 30% поисковых запросов являются геозависимыми, иными словами, привязанными к определенному региону.
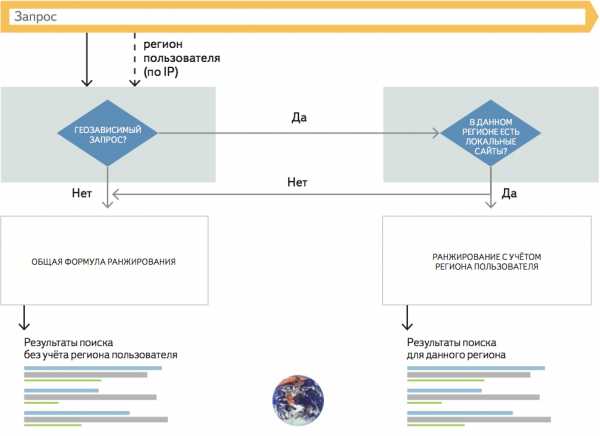
Принадлежность сайта к региону определяется по ряду признаков. В основном это контактная информация и телефон, указанные на сайте, а также такие косвенные признаки, как текст сайта, его IP-адрес и т.п. Для того, чтобы ваш сайт корректно индексировался по геозависмым запросам, необходимо сделать его привязку к региону в «Вебмастере» Яндекса и указать на сайте правильную контактную информацию.
Подробнее о том, как продвигать сайт в регионах, читайте тут.
Оригинальный контент, релевантный целевым поисковым запросам
Поисковая машина также учитывает контент сайта, его качество и уникальность. Если на сайте размещен оригинальный и интересный тематический контент, то это позволит получить органический трафик по низкочастотным запросам без всякого дополнительного продвижения. За копипаст велика вероятность попадания под фильтр Яндекса, также под фильтр могут попасть молодые сайты, использующие чужой контент после небольшого рерайта.
Очень негативно Яндекс относится к переоптимизированным текстам, поэтому не стоит злоупотреблять количеством вхождений ключевых слов. Предпочтительная плотность ключевиков должна составлять от 1% до 3-4%. Слишком длинные тексты также не приветствуются, контент в первую очередь создается для посетителей сайта, а значит, он должен быть легким в восприятии и соответствовать тематике ресурса.
Структурирование информации на сайте
Структура сайта должна быть логичной и понятной. Желательно, чтобы любая страница сайта была доступна максимум в три клика. Это облегчит взаимодействие пользователей с ресурсом, а также позволит ускорить индексацию сайта поисковыми роботами.
Контент желательно делить на абзацы и блоки, и обязательно разбавлять иллюстрациями. Это поможет посетителям легче воспринимать информацию.
Дизайн, юзабилити, скорость работы сайта
Яндекс рекомендует тщательно продумывать дизайн сайта, ведь он должен помогать посетителю найти основную информацию, ради которой и был создан ресурс.
Важны архитектура и юзабилити. Пользователю должно быть удобно и комфортно взаимодействовать с сайтом, ведь это напрямую влияет на поведенческий фактор, который в последнее время в значительной степени учитывается поисковиком. Если сайт нравится его посетителям, то он скорей всего окажется в ТОП поисковой выдачи.
Отсутствие хорошей навигации, сложная или запутанная структура сайта, неудачное расположение элементов, сложности с регистрацией или оформлением заказа, все это повышает коэффициент отказов. Такую же реакцию вызывает медленная работа сайта или частые сбои в его работе.
Яндекс очень негативно относится к агрессивной рекламе на сайте (особенно это касается popup, popunder и clickunder). Реклама имеет право на существование, но не должна мешать пользователю взаимодействовать с ресурсом.
Цитируемость сайта – количество и качество ссылок с других сайтов, тексты внешних ссылок
Значение внешних ссылок на сайт постепенно снижается, но все еще учитываются Яндексом. Поисковику важно, сколько и какие ресурсы ссылаются на веб-страницу сайта.
При региональном продвижении в анкорах ссылок должна быть региональная принадлежность, очень желательно наличие ссылок с региональных доноров.
Яндекс учитывает тематику ссылающихся сайтов; ссылки с тематических ресурсов придают больший вес ресурсу. Поисковик также ратует за разнообразие источников ссылочной массы. Существует понятие «возраста ссылки», чем она старше, тем лучше для Яндекса.
Наличие цен, информации об оплате и доставке для коммерческих сайтов
Яндекс считает, что в ТОП выдачи должны попадать только те сайты, которые помогают решать задачу пользователя. Поэтому, если речь идет об интернет-магазине, то он должен отвечать ряду требований:
- Товары должны содержать описания и фотографии.
- На сайте необходимо указать контактные данные, а также желательны отзывы других посетителей.
- Обязательно наличие информация о стоимости товара, а также условиях доставки и способах оплаты.
- Регистрация и оформление покупки должны быть простыми и понятными.
Отсутствие поискового спама
Любые попытки поискового спама строго пресекаются Яндексом. О том, что лучше избегать «серых» и «черных» методов продвижения сайта, известно всем. Не стоит усердствовать и с оптимизацией контента и продажей ссылок с сайта.
Надежный и безопасный хостинг
При ранжировании поисковик учитывает работоспособность сайта, поэтому сайт должен быть доступен 24 часа 7 дней в неделю. Поисковые роботы ежедневно обходят сайты, и если по каким-то причинам ресурс недоступен, это негативно скажется на его позициях в выдаче. Поэтому необходимо поддерживать хостинг в полной суточной работоспособности и не забывать вовремя продлевать срок регистрации домена. Недоступность сайта более 24 часов грозит серьезными потерями позиций в выдаче!
В заключение
Интернет с каждым годом становится все более персонализированным. На своей последней технологической конференции Яндекс анонсировал платформу «Атом», которая позволит подстраивать содержание страниц сайта индивидуально под каждого пользователя. Поэтому основное правило Яндекса - сайт должен помогать пользователю легко, удобно и быстро решать его проблему, отвечать на запрос. И именно те сайты, которые наиболее точно соответствуют этим требованиям, попадают в ТОП выдачи. Создавая сайт, всегда в первую очередь думайте о тех, для кого он предназначен.
www.iseo.ru