Функции ранжирования в поисковых системах: Okapi BM25, BM25, BM25F. Формула ранжирования bm25
BM25 алгоритм SEO-оценки текста - MegaIndex.
BM25 —семейство функций ранжирования документов, которые оценивают число ключевых запросов в каждом из документов.
Алгоритм имеет формулу, которая показывает релевантность страниц в зависимости от количества и расположения слов (во всех блоках текста, исключая ссылки) относительно других документов.

Функция называется BM25 (англ. "best match"), часто ее называют также Okapi BM25, по названию поисковой системы Okapi, где она была использована впервые.
В SEO Okapi BM25 — одна из функций ранжирования, используемая поисковиками для определения соответствия страницы заданному ключевому слову.
Т.е. если на странице нет фразы, соответствующей поисковому запросу, то не удастся попасть в ТОП в сравнении с конкурентами, которые ее используют.
Пример. Есть несколько запросов состоящих из нескольких слов:
- купить смартфон Samsung
- купить смартфон Samsung Galaxy
Пусть сравниваются два документы и первый документ не содержит слова Galaxy.
Согласно расчетов, оценка релевантности это сумма релевантностей каждого из слов.
Релевантность каждого из слова равна его IDF * на второй множитель.
Релевантность всего поискового запроса равна сумме релевантностей всех слов.
Таким образом, отсутствие слова или другими словами его частота, равная 0, дает релевантность 0.
Поэтому если по двум первым словам score будет одинаково то более релевантным будет тот документ, который содержит слово Galaxy.
(источник https://habrahabr.ru/post/162937/)
Рекомендуем провести проверку релевантности текста в нашем приложении "Анализ текста".
Более подробно: https://ru.wikipedia.org/wiki/Okapi_BM25
Рекомендуем посмотреть видео по теме:
Функции ранжирования в поисковых системах: Okapi BM25, BM25, BM25F
Что такое ранжирование
Ранжирование — процесс упорядочивания документов в соответствии со степенью их соответствия поисковому запросу. Главной целью ранжирования является размещение наиболее релевантных (соответствующих запросу) документов коллекции на более высокие позиции в выдаче поисковой системы. Для решения задачи поиска используются специальные функции, на основе которых и рассчитывается релевантность.

Что такое релевантность
Релевантность является функцией от набора переменных (факторы ранжирования). В качестве таких факторов выступают различные числовые характеристики документа, при помощи которых можно различать релевантные документы и не релевантные. Количество факторов ранжирования не является фиксированным числом и может изменяться. К примеру, Google в настоящее время при ранжировании не учитывает мета-тег «keywords» — хотя ранее он имел значение.
Функции ранжирования
Поисковые системы Yandex и Google используют значительно больше таких факторов — функция ранжирования учитывает более чем 150 компонентов на сегодняшний день. Большая часть этих факторов представляет собой простые числовые характеристики документа. Ключевым моментом в ранжировании является способ комбинации факторов — вид функции релевантности.
Okapi BM25
В современных поисковых системах расчет релевантности документов базируется на функции Okapi BM25, основанной на вероятностной модели, разработанной в 1970-х и 1980-х годах Стивеном Робертсоном и Карен Спарк Джоунс.
BM25 и BM25F
BM25 и его более современные модификации (например, BM25F) представляют собой TF-IDF-подобные функции ранжирования. TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, которая используется для оценки важности слова в контексте документа (являющегося в свою очередь частью определенной коллекции документов). Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
К примеру, если в документе содержится 100 слов и слово «дерево» встречается в нём 5 раз, то частота слова (TF) для слова «дерево» в документе будет 0,05 (5/100). Частоту документа (DF) определяют как количество документов, содержащих слово «дерево», разделенное на количество всех документов. Т.е., если слово «дерево» содержится в 1000 документов из 10 000 000 документов, то DF для него будет равен 0,0001 (1000/10000000). Для окончательного расчета веса слова TF делят на DF. В нашем примере, TF-IDF вес для слова «дерево» будет 500 (0,05/0,0001).
В реальном веб-поиске эти функции ранжирования зачастую входят как компоненты в гораздо более сложную функцию ранжирования. BM25F — модификация BM25, в которой документ рассматривается уже как совокупность нескольких полей (заголовки, основной текст, ссылочный текст и т.д.), каждому из которых присваивается своя степень значимости в конечном виде функции ранжирования.
Коммерческая тайна
Полный список критериев, как и конкретный вид модифицированной формулы ранжирования Okapi BM25, был и остаётся главной коммерческой тайной крупных поисковых систем. Это вызвано естественным сопротивлением поисковых систем заинтересованности оптимизаторов в данной информации с целью воздействия на алгоритмы ранжирования с максимальной эффективностью.
fortress-design.com
Алгоритм BM25 / Хабр
Впервые данный алгоритм встретил на Википедии и не обратил на него особого внимания. Позже изучая научные труды сотрудников Яндекса, я обратил внимание на то, что они ссылаются на него, например, в статье Сегаловича об алгоритмах определения нечетких дубликатов, поэтому решил разобраться, в чем смысл его использования. Постараюсь на простых примерах это объяснить. Итак, для чего этот алгоритм?Первое. Вводится зависимость релевантности от вхождения или не вхождения слов в запросах с более чем одного слова. Пусть есть несколько запросов состоящих из нескольких слов, например (пример чисто иллюстративный):
- купить смартфон Samsung
- купить смартфон Samsung Galaxy
Релевантность каждого из слова равна его IDF * на второй множитель в выражении выше. Релевантность всего поискового запроса равна сумме релевантностей всех слов. Таким образом, отсутствие слова или другими словами (его частота) равна 0 дает релевантность 0. Поэтому если по двум первым словам score будет одинаково то более релевантным будет тот документ, который содержит слово Galaxy.
Второе. Преимущество при поиске в запросах с более чем 2-ух слов, одно из которых менее употребительно (более узкоспециализированное) будет отдаваться документам которые содержат это узкоспециализированное слово. Например, есть запрос купить Samsung Galaxy Note 2 (чисто иллюзорный пример). Пусть Note 2 – это более редкое слово (меньше раз встречается в коллекции чем Samsung и Galaxy). Пусть есть 2-а документа каждый из которых релевантен запросу и каждый из них содержит кроме Samsung и Galaxy также Note 2. При этом в первом документе note 2 употребляется только один раз, тогда как во втором – 3 раза (подразумевается, что документ содержит больше информации о Note 2). Но сначала рассмотрим, результат вычисление релевантности алгоритмом, если частоты всех указанных слов в документах одинаковы. Вот что получается по BM25 в Excel.
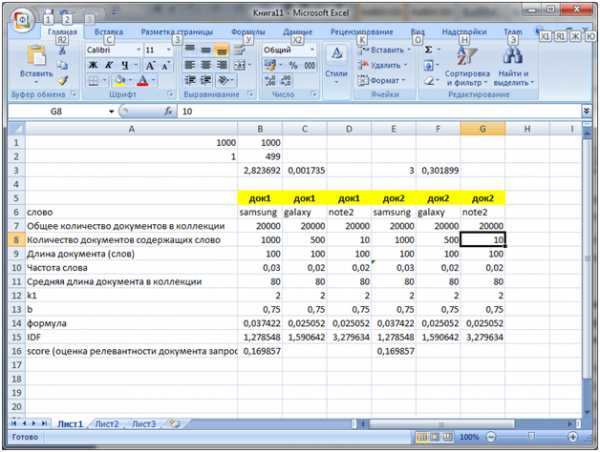
Обратите также внимание, что из-за того, что количество документов содержащее слово Note 2 меньше равно в 50 раз от содержащих слово galaxy (500) мы получаем IDF равный 3,279634 что значительно больше IDF для слова galaxy.
Пока что у нас были одинаковые значения частот для слова note 2 (для других слов также). Теперь давайте в Excel увеличим частотность слова note 2 для док2, вместо 0,02 сделаем 0,05 (5 вхождений слова).

Обратите внимание, что значение IDF не изменяется но значение формула (второй множитель на изображении в самом вверху) теперь стало равно 0,061856 и именно это значение участвует в вычислении score, которое теперь для док2 равно уже 0,290559
Теперь самое главное. Увеличим частоту вхождения слова galaxy до 5 в док 1
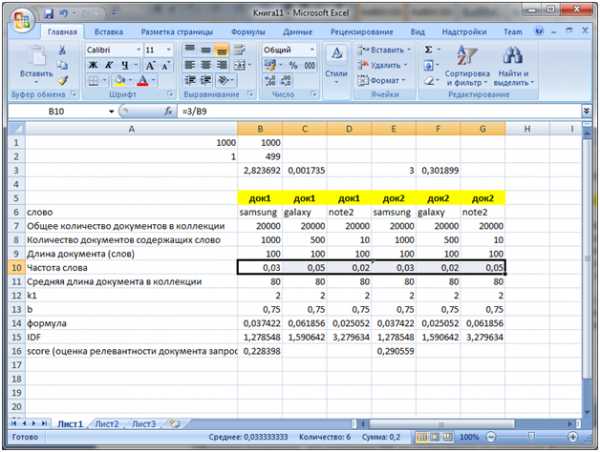
Как мы видим суммарная частота каждого из слов в док1 и док2 одинакова. Но значение score (релевантность) выше у док2, потому что слово note2 является более редко встречающимся соответственно его результирующее влияние больше чем слово galaxy.
На практике наличие слов в многосложных запросах очень важно. Конечно же релевантность современных поисковых систем определяется не только исходя из частот как это было показано на примере формулы BM25, но все же некоторые корреляции провести можно. В основном это касается того, что если в документе нет слова из поискового запроса то такому документу значительно сложнее подняться в ТОП по запросу по сравнению с теми, у которых это слово содержится. Давайте рассмотрим пример на поисковой системе Яндекс.
Вводим запрос Samsung galaxy. У меня выдача касалась Samsung galaxy в целом (2 сайта, как обычно Википедия) остальное модели, картинки и т.д.
Вводим запрос samsung galaxy note 2. Выдача полностью меняется, теперь представлены страницы, которые содержат информацию не просто о Samsung galaxy, а о Samsung galaxy note 2.
Вводим запрос samsung galaxy note 2 ценаОпять выдача меняется теперь в выдаче страницы, которые уже содержат слово цена, а не просто Samsung galaxy.
Вводим запрос samsung galaxy note 2 цена Харьков. Выдача кардинально меняется, все страницы в ТОП10 содержат слово Харьков.
Можно ли сказать, что слово Харьков является более узкоспециализированным, как это приводилось в алгоритме BM25 выше? IDF cлова Харьков знает только поисковая система, но в контексте поискового запроса Samsung galaxy note 2 оно без сомнения сужает область поиска. Может быть пример с Яндексом немного неудачен, в силу того, что в приведенном случае большую роль будет играть учет региональности запроса, но я думаю со мной согласится любой сеошник, что слово из поискового запроса обязательно должно быть в тексте, я же всего лишь постарался показать работу алгоритма BM25 и раскрыть 2-а важных его аспекта.
Ссылка на xls документ — книга11.xls
habr.com
Функция ВМ25: ранжирование в поисковых системах
4.5 из 5 на основе 2 оценок
24.11.2011
Ранжирование - процесс упорядочивания документов в соответствии со степенью их соответствия поисковому запросу. Главной целью ранжирования является размещение наиболее релевантных (соответствующих запросу) документов коллекции на более высокие позиции в выдаче поисковой системы. Для решения задачи поиска используются специальные функции, на основе которых и рассчитывается релевантность.
Релевантность является функцией от набора переменных (факторы ранжирования). В качестве таких факторов выступают различные числовые характеристики документа, при помощи которых можно различать релевантные документы и не релевантные. Количество факторов ранжирования не является фиксированным числом и может изменяться. К примеру, Google в настоящее время при ранжировании не учитывает мета-тег «keywords» - хотя ранее он имел значение.
Поисковые системы Yandex и Google используют значительно больше таких факторов — функция ранжирования учитывает более чем 150 компонентов на сегодняшний день. Большая часть этих факторов представляет собой простые числовые характеристики документа. Ключевым моментом в ранжировании является способ комбинации факторов - вид функции релевантности.
В современных поисковых системах расчет релевантности документов базируется на функции Okapi BM25, основанной на вероятностной модели, разработанной в 1970-х и 1980-х годах Стивеном Робертсоном и Карен Спарк Джоунс.
BM25 и его более современные модификации (например, BM25F) представляют собой TF-IDF-подобные функции ранжирования. TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, которая используется для оценки важности слова в контексте документа (являющегося в свою очередь частью определенной коллекции документов). Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
К примеру, если в документе содержится 100 слов и слово «дерево» встречается в нём 5 раз, то частота слова (TF) для слова «дерево» в документе будет 0,05 (5/100). Частоту документа (DF) определяют как количество документов, содержащих слово «дерево», разделенное на количество всех документов. Т.е., если слово «дерево» содержится в 1000 документов из 10 000 000 документов, то DF для него будет равен 0,0001 (1000/10000000). Для окончательного расчета веса слова TF делят на DF. В нашем примере, TF-IDF вес для слова «дерево» будет 500 (0,05/0,0001).
В реальном веб-поиске эти функции ранжирования зачастую входят как компоненты в гораздо более сложную функцию ранжирования. BM25F — модификация BM25, в которой документ рассматривается уже как совокупность нескольких полей (заголовки, основной текст, ссылочный текст и т.д.), каждому из которых присваивается своя степень значимости в конечном виде функции ранжирования.
Полный список критериев, как и конкретный вид модифицированной формулы ранжирования Okapi BM25, был и остаётся главной коммерческой тайной крупных поисковых систем. Это вызвано естественным сопротивлением поисковых систем заинтересованности оптимизаторов в данной информации с целью воздействия на алгоритмы ранжирования с максимальной эффективностью.
Всему об информационном поиске и поисковой оптимизации вы можете обучится посетив наши курсы SEO в Харькове по адресу ул. Короленко, 11/13, Seo Education. Корпоративным клиентам, желающим обучить персонал поисковой оптимизации и аналитике предоставляются скидки!
seosolution.ua
Оценка качества текста, Закон Ципфа, алгоритмы TF-IDF, BM25, BM25F
Качество текста является одним из основных показателей ценности информации, содержащихся на страницах сайтов в Интернете. Со стороны пользователя, качество текста оценивается с точки зрения простоты и полноты изложения, читабельности, актуальности информации.
Со стороны пользователя, качество текста оценивается с точки зрения простоты и полноты изложения, читабельности, актуальности информации.
Другими словами человек, пришедший на сайт, должен получить полноценный ответ на интересующий его вопрос в простой, наглядной и доступной форме.
Поисковые системы пытаются подобрать для пользователя страницу, позволяющую наиболее полно удовлетворить его любопытство.
Для оценки качество текста на страницах используется целый набор сложных алгоритмов обработки, которые оценивают текст и формируют ключевые показатели, определяющие позиции страниц по тем или иным запросам.
К таким ключевым показателям относят релевантность текста, его естественность, уникальность и так далее.В этой статье мы рассмотрим некоторые алгоритмы, по которым происходит оценка качества текста поисковыми системами.
Хочу сразу заметить, что эта информация дается Вам не как рекомендации к прямому действию, а, скорее, для общего развития.
Закон Ципфа
Закон Ципфа или Зипфа представляет собой метод оценки естественности текста.Смысл его заключается в определении закономерности распределения частоты слов.
Для этого берется какой-то текст и подсчитывается число вхождений всех слов, которые в нем встречаются. Затем слова упорядочиваются по убыванию частоты их использования в этом тексте.
Так вот, по закону Ципфа второе слово должно встречаться в тексте в два раза реже, чем первое, третье – в три раза реже, чем первое и так далее.
Если эта закономерность соблюдается, то текст по закону Ципфа написан естественно.
В интернете для оценки естественности текста используются специальные программы и сервисы. Одним из них я периодически пользуюсь, его адрес – 1y.ru.
Этот сервис бесплатный и здесь можно проверить тексты для любой страницы своего сайта, либо любой текст, еще не размещенный в Интернете.
Я проверил текст этой статьи и получил вот какие результаты: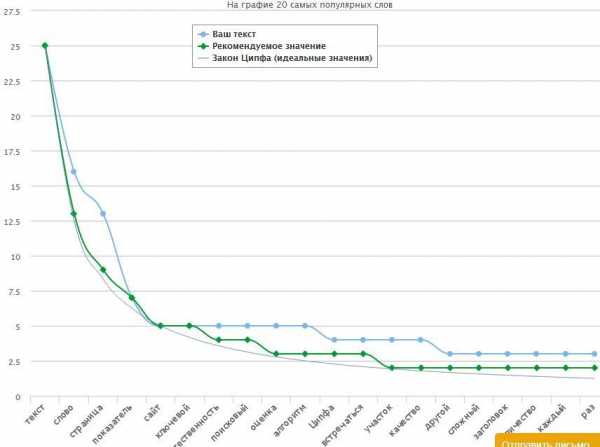 Вверху график частотности слов по закону Ципфа. А ниже заключение сервиса. Как видим, получилось 80%, что является хорошим показателем. Признаюсь честно, никакими доработками я не занимался. Написал, проверил и разместил.Проверку текста на этом сервисе я делаю довольно редко, больше из любопытства.
Вверху график частотности слов по закону Ципфа. А ниже заключение сервиса. Как видим, получилось 80%, что является хорошим показателем. Признаюсь честно, никакими доработками я не занимался. Написал, проверил и разместил.Проверку текста на этом сервисе я делаю довольно редко, больше из любопытства.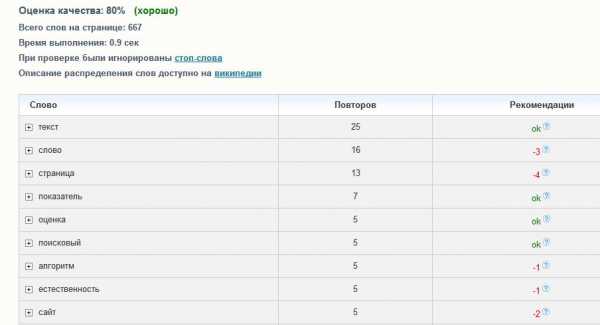
Таким же образом Вы можете оценить естественность текста на сайтах своих конкурентов и лидеров в Вашей нише бизнеса.Практически сервис 1y.ru можно использовать для оценки своих текстов и их доработке. Но не стоит стремиться к стопроцентному результату, иначе можно исказить Ваш текст до потери смысла.
Реагировать следует лишь при очень низких показателях. Это может Вас уберечь от различных огрехов, таких как перенасыщении текста ключевыми фразами и т.п.
Оцените тексты лидеров поисковой выдачи и Вы увидите насколько они соответствуют показателям естественности и к чему следует стремиться.
Алгоритм TF-IDF
Алгоритм TF-IDF используется для расчета важности слова в документе или, говоря другими словами, веса слова.
Этот показатель прямо пропорционален количеству вхождений слова в анализируемый текст и обратно пропорционален частоте употреблению этого слова в других текстах интернета.
Например. Наша страница состоит из 2000 слов, из них 20 раз встречается слово «закон».
TF соответственно будет равен 20/2000 = 0.01.
Затем имеем количество страниц в интернете, к примеру, 8 000 000 000, и в 4 000 000 из них встречается слово «закон».
DF будет равен 4000000/8000000000 = 0.0005.
Вычисляем Вес слова TF/DF = 0.01/0,0005 = 20
В этом примере цифры я взял условные, но в каждой поисковой системе есть реальные цифровые показатели по каждому слову.
Оценивать Вес слов приходится не часто. Это следует делать при разбавлении ключевых фраз при заполнении тегов Title, метатегов, заголовков публикаций, околоссылочного текста.
В этом случае рекомендуют использовать слова с меньшим весом.
Для основного текста заниматься определением веса используемых слов заниматься нет смысла. Пишите как считаете нужным и не отвлекайтесь на эти расчеты.
Для определения веса слов можно воспользоваться сервисом tools.promosite.ru. Там есть еще различные функции, но в данном случае нас интересует раздел, который так и называется «Вес слов».
Алгоритм BM25 и BM25F
Формула или формулы расчета по этим алгоритмам значительно сложнее. Да и поисковые системы их постоянно дорабатывают и оптимизируют, поэтому копаться в этих формулах практического смысла нет. За поисковиками не угонишься, а мозги себе можно и перенапрячь.
Алгоритм BM25 пришел на смену TF-IDF. Он белее сложный и продвинутый и его суть заключается в оценке текста на странице, основываясь на количестве и месторасположении ключевых слов, без учета ссылок.
Алгоритм BM25F учитывает не только сам текст, но и его отдельные участки или зоны.
К таким участкам относят тег Title, метатеги, заголовки и подзаголовки, околоссылочный текст.
Подробнее о таких участках и о рекомендациях по их заполнению можно прочитать на странице «Структура страницы сайта».Причем каждый участок текста имеет свою значимость для ранжирования страницы, что в конечном итоге влияет на окончательные позиции страницы в поисковой выдаче.
Поэтому просто грамотно заполнив Title, метатеги, заголовки, можно сразу повысить позиции сайта, особенно по НЧ запросам.
Полезные Материалы:
inetmkt.ru
Алгоритмы ранжирования текстов | Статьи о поисковом продвижении сайта от компании «Веб-Эталон»

12.03.2013
Ранжирование текстов является одной из важнейших частей современного поиска.
Основанием считается формула TF-IDF, принадлежащая Солтону. Ее идея совершенно проста:
- Чем больше слов запроса в тексте, тем лучше;
- Чем весомее слово, тем лучше.
Но в ней есть существенные недостатки, например, не учтено, что если документ будет очень длинный и в нем будет очень много вхождений, то такой документ не обязательно должен быть более релевантен, чем его короткий аналог. Допустим, мы возьмем все страницы Википедии и соединим их в один текст, то у него будет очень высокий TF-IDF, т.к. вхождение всех слов в нем будет огромным. Поэтому в эту формулу было совершенно необходимо добавить нормирование на длину документа. Кроме того, есть еще один существенный недостаток формулы. Она не учитывает, что если слово в одном документе встретилось 50 раз, а в другом – 49 раз, то не факт, что первый документ релевантнее второго. Т.е. необходимо каждому последующему вхождению придавать все меньше и меньше веса.
Эти две эвристики были учтены в формуле, принадлежащей Робертсону, которая называется BM25 (Okapi).
k1 и b – это некие нормировочные коэффициенты.
Эта формула дает:
- Пенальти документам, содержащим большое число слов;
- Пенальти большому количеству вхождений термина.
Интересно, что в работе Робертсона утверждается, что есть некая вероятностная модель, из которой получается эта формула. Но многие специалисты по ранжированию утверждают, что в данном случаем математика родилась подгонкой под ответ, т.е модель «притянута за уши». Кроме того, наибольший эффект дает определение коэффициентов k1 и b как неких эвристических величин, т.е. без разметки вручную не получится найти наиболее подходящие значения коэффициентов.
Но это еще не все. Современные поисковые машины учитывают куда больше факторов:
Морфология.
Это значит, что если в запросе написано одно слово, а документ находится по другому слову, которое имеет тесную морфологическую связь с исходным термином. Кстати, так на первых порах Яндекс отобрал значительную долю поиска у Google в России. Т.к. у Гугла не было морфологии, а у Яндекса была. Это очень помогало найти большее количество релевантных документов, если в них нет слов запроса (этап фильтрации). По большому счету, это всего лишь увеличение полноты, но тогда это было крайне важно, ведь документов на русском языке было не так много как сейчас.
Тезаурусы (словари).
Это также работа над полнотой. Здесь можно будет находить документы, в которых написаны слова, означающие тоже самое, что и запрос (синонимы). Понятно, что ценность тезаурусов и морфологии тем выше, чем меньше коллекция документов.
BM25F - Зоны.
Та же формула, но учитывающая положение термина в документе. Например, словам в заголовке надо давать больше веса, чем всем остальным терминам в документе.
Автор надеется, что данная статья будет полезна всем профессионалам интернет-маркетинга, осуществляющим поисковое продвижение сайтов.
web-etalon.ru
№22 (27-01-2016). Текстовая оптимизация: стоит ли верить в силу TF-IDF и BM25
№22 (26-01-2016)
5 мин 2931 просмотров 0
Раньше основным фактором продвижения в ТОП были ссылки. Теперь важнее всего текстовые факторы и внутренняя оптимизация. Пока ссылки были на коне, составлять ТЗ на тексты для сайта можно было практически «на глазок», щедро рассыпая нужные ключевики — и все работало, сайты ползли наверх. Сейчас же попытки писать тексты, ориентируясь на устаревшие метрики типа «плотности ключевых слов на количество символов», не приведут к хорошим результатам. Теперь одним из самых лучших способов проверить SEO-подрядчика будет поинтересоваться, каким образом составляются технические задания для копирайтеров. Ответ должен быть таким:
- автоматизированная система подбирает полное семантическое ядро по «затравкам», анализируя реальную коллекцию документов индекса;
- проводится автоматизированная кластеризация запросов на основе статистического анализа текущих лидеров ТОПа по соответствующим ключевикам;
- проводится статистический анализ объема документов в ТОПе и их частотных характеристик, также частотных характеристик по зонам документа (!), на основе которых автоматизированно составляется ТЗ, с которым может работать копирайтер.
Как вы видите, речь только о динамических факторах, которые выявляются путем анализа текущих лидеров выдачи, и не по одному, а по множеству критериев. Тем не менее, сообщество оптимизаторов всегда ищет пути полегче. Сейчас, к сожалению, многие становятся на путь проповедования TF-IDF и BM25/BM25F. Формулы расчета этих показателей могут внушить уважение непосвященным, но стоит понимать, что за ними не кроется никакой магии. Забегая вперед, скажем, что использование BM25 вместо динамического анализа реальных лидеров ТОПа по куче текстовых факторов — это путь к потере релевантности и отсутствию возможности бороться за лидирующие позиции по высококонкурентным запросам.
Чтобы не быть голословными, давайте разберем популярные сейчас подходы для, грубо говоря, составления ТЗ на тексты: BM25 и TF-IDF. Мы также дополним этот теоретический ликбез сведениями из последних статей SEO-эксперта Kokoc.com Алексея Чекушина, посвященных текстовым факторам ранжирования.
Сразу подчеркнем: мы не говорим, что поисковые системы не используют BM25. Очень существенная часть из 50 текстовых факторов ранжирования Яндекса — это, вероятнее всего, пороговые условия if/else по уже давно известным стандартным метрикам текстового анализа, в том числе и BM25. Однако будет наивно писать все тексты в соответствии с BM25 и думать, что это решает задачу. Текстовых факторов не один, а, по заявлениям «Яндекса», около 50. Да и машинное обучение вносит заметные корректировки. Так что если хотите в ТОП, простой (пусть и непонятной на первый взгляд) формулой не обойтись. Тем не менее, знать о базовых метриках необходимо. Для начала рекомендуем освежить в памяти наши предыдущие статьи о текстовом ранжировании:
TF-IDF — оценка важности слова в тексте Поисковые системы не понимают текст, а обсчитывают его метрики. Одна из типичных задач для такого обсчета: определить самые главные слова текста, которые дадут возможность отнести документ (страницу) к той или иной тематике, кластеризовать тексты/запросы, включить в ранжирование по каким-то критериям. Ну и прочее: например, сделать пессимизационные выводы при наличии в тексте двух и более главных сочетаний абсолютно разных тематик — например, «купить пластиковые окна» и «свиноводство».
Итак, TF — это term frequency (частота вхождений в тексте), IDF — inverse document frequency (отношение общего количества текстов в коллекции к количеству текстов, содержащих рассматриваемое словосочетание).
TF-IDF — это TF, умноженное на IDF.
TF = количество вхождений слова / сумма слов в тексте
IDF = общее количество текстов / количество текстов, в которых встречается слово
Что нам дают эти вычисления? TF позволяет понять, насколько слово важно в конкретном тексте, а IDF дает возможность «отфильтровать» часто употребляющиеся слова и рассматривать только «значащие».
BM25 — более продвинутая версия TF-IDF BM — это Best Match, то есть «наилучшее совпадение». Это уже мера релевантности текста запросу. Распространенный вариант этой функции таков: берем IDF запроса и умножаем на частное TF и суммы TF и отношения длины текста и средней длины текстов в коллекции. Все это дополнено свободными коэффициентами (k и b в формуле), но это уже не так важно. Как видите, BM25 не очень-то сильно отличается от TF-IDF. В функцию добавлен только учет отношения длины рассматриваемого текста к средней длине текста в коллекции.
Так что не стоит пугаться или испытывать лишнее уважение, когда оптимизатор показывает формулу. Ничего особенно крутого в ней нет. Давайте еще раз поясним, почему эту формулу нельзя использовать для составления ТЗ для копирайтера: во-первых, у Яндекса не один текстовый фактор, а 50. Во-вторых, машинное обучение может, например, вывести в ТОП по определенным запросам страницы с заметно отличающейся совокупностью весов важности текстовых факторов. Стандартная формула BM25 не дает возможности учесть это.
Стоит также упомянуть о BM25F — модификации меры релевантности по фактору частотности, которая учитывает различную важность зон документа — например, заголовок вносит больший вклад, чем предложение в середине текста.
Эксперимент Алексея Чекушина подтверждает отсутствие возможности использовать простую формулу BM25 для продвижения по средне- и высококонкурентным запросам:
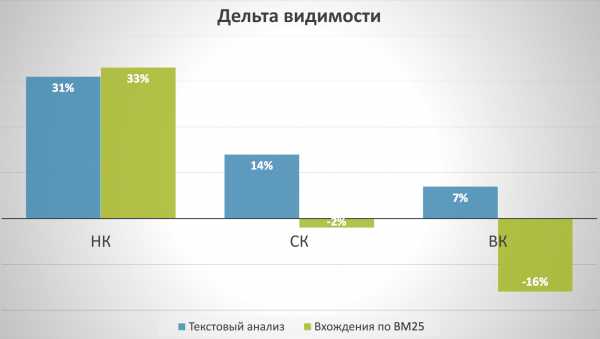
Тексты, созданные по ТЗ, подготовленному через продвинутый текстовый анализ, увеличивают видимость страниц в поисковиках (то есть приводят к росту позиций). Тексты, написанные по ТЗ, составленному через расчет BM25 — снижают видимость.
Вывод
Теперь если ваши оптимизаторы попытаются продать вам BM25 как нечто потрясающее инновационное и эффективное, вы сможете с пониманием вынести отрицательное оценочное суждение об их компетенции. Эта функция была разработана в 1980-х годах, она очень мало отличается от простого «берем количество вхождений и делим на объем текста. Сейчас уже нет никакой возможности результативно продвигать сайты силами школьника Васи — чтобы добиться вывода в ТОП, нужна математика и продвинутая автоматизация обсчета вполне серьезных объемов данных. Вот, например, известная инфографика — «что нужно выучить специалисту по анализу данных»: Возможность делать эффективное SEO сейчас есть только у крупных компаний, которые могут позволить себе работать с ведущими специалистами и вкладывать деньги в разработку и обкатку соответствующего софта (внутреннего инструментария).
Возможность делать эффективное SEO сейчас есть только у крупных компаний, которые могут позволить себе работать с ведущими специалистами и вкладывать деньги в разработку и обкатку соответствующего софта (внутреннего инструментария).
Узнать больше о продукте
Понравилась статья? Поделись ей в социальных сетях:
Возможно, вам понравится:
№6 (09-06-2015). Защита сайта от SEO-атак№6 (19-06-2015)
Могут ли конкуренты потопить ваш сайт ссылочной атакой? Изучаем инструменты для мониторинга и методы защиты.
5903 просмотров 0
№4 (12-05-2015). Всё о title, keywords и description№4 (19-06-2015)
Учимся защищать сайт от склейки страниц с помощью добавления title, keywords и description при публикации каждой новой страницы
5527 просмотров 0
kokoc.com








