Oracle - оптимизировать запрос, большую таблицу базы данных, поле CLOB. Oracle оптимизация запросов с большими объемами данных
оптимизируйте запрос, таблицу с большими базами данных, поле CLOB
Итак, я навел на это свой мозг и, по общему признанию, не очень хорошо разбираюсь в Oracle. У нас есть таблица, на которой хранится около 60 миллионов записей со значениями, хранящимися в ней для зданий. Добавили соответствующие индексы, которые, по моему мнению, были пригодны, но все же плохие показатели. Вот запрос, который должен помочь:
SELECT count(*) FROM viewBuildings INNER JOIN tblValues ON viewBuildings.bldg_id = tblValues.bldg_id WHERE bldg_deleted = 0 AND (bldg_summary = 1 OR (bldg_root = 0 AND bldg_def = 0) OR bldg_parent = 1) AND field_id IN (207) AND UPPER(dbms_lob.substr(v_value, 2000, 1)) = UPPER('2320')Таким образом, приведенное выше является лишь одним примером запроса, который может быть построен. Он ищет в tblValues в поле CLOB v_value для соответствия «2320». Он охватывает верхние строчки, поскольку он может искать как числовые, так и текстовые значения. tblValues имеет 60 миллионов записей. Он индексируется идентификатором здания, а также идентификатором поля.
Возможно, мне нужно будет предоставить дополнительную информацию, но, насколько статистика идет, число, которое выскочило мне, было «последовательно получает». Согласованный get = 74069. Это большое количество?
Любые советы были бы замечательными, прежде всего, при работе с полем CLOB на большой таблице базы данных. Невозможно использовать индексирование типа индекса, так как мне нужны точные соответствия, и просматриваемые данные могут быть числовыми или строковыми.
EDIT (больше информации): tblBuildings является частью viewBuildings (вид), имеет 80000 записей tblValues имеет значения каждого здания, имеет 68000000 записей tblValues имеет около 550 полей в здании (field_id)
Желаемый результат: Запрос, чтобы вернуть результаты в < 5 секунд. Это необоснованно? Иногда это будет бесконечно работать, иногда может быть 80 секунд.
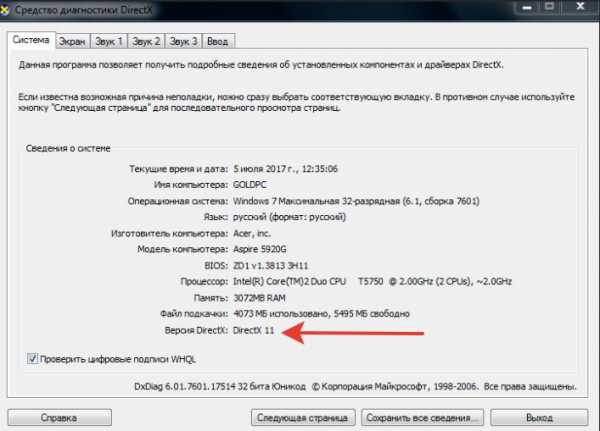
Объяснить план результаты
Plan hash value: 1480138519 ----------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -----------------------------------------------------------------------------------------------------------------------| | 0 | SELECT STATEMENT | | 1 | 192 | 32 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 192 | | | | 2 | NESTED LOOPS | | 1 | 192 | 15 (0)| 00:00:01 | | 3 | NESTED LOOPS | | 1 | 183 | 12 (0)| 00:00:01 | |* 4 | FILTER | | | | | | | 5 | NESTED LOOPS OUTER | | 1 | 64 | 10 (0)| 00:00:01 | |* 6 | TABLE ACCESS BY INDEX ROWID | TBLBUILDINGS | 1 | 60 | 9 (0)| 00:00:01 | |* 7 | INDEX RANGE SCAN | SAA_4 | 17 | | 3 (0)| 00:00:01 | | 8 | NESTED LOOPS | | 1 | 21 | 3 (0)| 00:00:01 | | 9 | TABLE ACCESS BY INDEX ROWID| TBLBUILDINGSTATUSES | 1 | 15 | 2 (0)| 00:00:01 | |* 10 | INDEX RANGE SCAN | IDX_BUILDINGSTATUS_EXCLUDEQUERY | 1 | | 1 (0)| 00:00:01 | |* 11 | INDEX RANGE SCAN | IDX_BUILDING_STATUS_ASID_DELETED | 1 | 6 | 1 (0)| 00:00:01 | | 12 | TABLE ACCESS BY INDEX ROWID | TBLBUILDINGSTATUSES | 1 | 4 | 1 (0)| 00:00:01 | |* 13 | INDEX UNIQUE SCAN | PK_TBLBUILDINGSTATUS | 1 | | 0 (0)| 00:00:01 | |* 14 | TABLE ACCESS BY INDEX ROWID | TBLVALUES | 1 | 119 | 2 (0)| 00:00:01 | |* 15 | INDEX UNIQUE SCAN | PK_SAA_6 | 1 | | 1 (0)| 00:00:01 | | 16 | INLIST ITERATOR | | | | | | |* 17 | INDEX RANGE SCAN | SAA_7 | 1 | 9 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): 4 - filter("TBLBUILDINGSTATUSES"."BUILDING_STATUS_HIDE_REPORTS" IS NULL OR "TBLBUILDINGSTATUSES"."BUILDING_STATUS_HIDE_REPORTS"=0) 6 - filter("TBLBUILDINGS"."BLDG_SUMMARY"=1 OR "TBLBUILDINGS"."BLDG_SUB_BUILDING_PARENT"=1 OR "TBLBUILDINGS"."BLDG_BUILDING_DEF"=0 AND "TBLBUILDINGS"."BLDG_ROOT"=0) 7 - access("TBLBUILDINGS"."BLDG_DELETED"=0) filter(NOT EXISTS (SELECT 0 FROM "TBLBUILDINGSTATUSES" "TBLBUILDINGSTATUSES","TBLBUILDINGS" "TBLBUILDINGS" WHERE "TBLBUILDINGS"."BLDG_ID"=:B1 AND "TBLBUILDINGSTATUSES"."BUILDING_STATUS_ID"="TBLBUILDINGS"."BUILDING_STATUS_ID" AND "TBLBUILDINGSTATUSES"."BUILDING_STATUS_EXCLUDE_QUERY"=1)) 10 - access("TBLBUILDINGSTATUSES"."BUILDING_STATUS_EXCLUDE_QUERY"=1) 11 - access("TBLBUILDINGS"."BLDG_ID"=:B1 AND "TBLBUILDINGSTATUSES"."BUILDING_STATUS_ID"="TBLBUILDINGS"."BUILDING_STATUS_ID") filter("TBLBUILDINGSTATUSES"."BUILDING_STATUS_ID"="TBLBUILDINGS"."BUILDING_STATUS_ID") 13 - access("TBLBUILDINGSTATUSES"."BUILDING_STATUS_ID"(+)="TBLBUILDINGS"."BUILDING_STATUS_ID") 14 - filter(UPPER("DBMS_LOB"."SUBSTR"("TBLVALUES"."V_VALUE",2000,1))=U'2320') 15 - access("TBLVALUES"."FE_ID"=207 AND "TBLBUILDINGS"."BLDG_ID"="TBLVALUES"."BLDG_ID") 17 - access("TBLINSPECTORBUILDINGMAP"."IN_ID"=1 AND ("TBLINSPECTORBUILDINGMAP"."IAM_BUILDING_ACCESS_LEVEL"=0 OR "TBLINSPECTORBUILDINGMAP"."IAM_BUILDING_ACCESS_LEVEL"=1) AND "TBLBUILDINGS"."BLDG_ID"="TBLINSPECTORBUILDINGMAP"."BLDG_ID") 44 rows selected Plan hash value: 2137789089 --------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 | | 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 | ---------------------------------------------------------------------------------------------Оптимизация и администрирование БД Oracle : Оптимизация Oracle EBS
Оптимизация Oracle EBS Кем: Владимир Гончаров (23397 Прочтений)
«Тушение пожаров»
Через два года после внедрения системы стало понятно, что решать проблемы по мере их возникновения становится опасным для бизнеса клиента. Поначалу, еще в апреле 2006, мы старались устранять все то, что создает наибольшие неприятности на продуктивных серверах, и при этом требует наименьших трудозатрат. Перво-наперво, наладили ежедневный анализ отчетов STATSPACK с целью выявления наиболее "тяжелых" запросов. "Тяжелые" запросы определяли по количеству логических (buffer gets) и физических (physical reads) чтений.Уже через пару месяцев картина изменилась и по отчету STATSPACK, и по дефектам по производительности, которые вдруг пропали на тот момент.
Вот некоторые методы, которыми мы пользовались для ускорения "тяжелых" запросов:1) Сбор гистограмм по некоторым колонкам.2) Удаление неправильных хинтов и "кастомизированного" кода.Хинты в SQL запросах, поставленные в 2004 году, на тот момент были эффективны, но по прошествии лет картина данных в БД поменялась, и зачастую от таких "хинтов" мы получали больше вреда, чем пользы. Большинство подобных "оптимизированных" запросов мы исправляли простым удалением хинта. Конечно, прежде мы наладили регулярный сбор статистики для оптимизатора Oracle.3) Переписывание запросов.Обнаружив плохо написанный запрос, мы создавали технические дефекты и назначали их на авторов запроса. Этим убивали двух зайцев: a. проблема производительности у пользователей исправлялась еще до того, как пользователь успевал завести инцидент, а b. разработчик волей-неволей учился на своих ошибках, опять же, без вреда для клиента.4) Замена переменных привязок на литеральные значения и наоборот.Ради объяснения этого способа мы создали впоследствии семинары для всех разработчиков проекта.5) Поиск и установка исправлений для EBS, улучшающих производительность.Этот метод применим только к стандартому, не "кастомизированному" коду.6) Создание индексов. Стоит отметить, что к созданию "кастомизированных" индексов на проекте относились крайне неприветливо. Однако, первый такой опыт по оптимизации системы был охарактеризован фразой "два индекса, которые перевернули STATSPACK", когда парой индексов размером 65K мы значительно ускорили с десяток самых "тяжелых" "кастомных" запросов модуля "Запасы". В настоящее время мы по-прежнему не приветствуем таких решений по оптимизации, если предварительно не проверены другие способы.
Работа с администраторами
Параллельно с устранением "тяжелых" запросов на проекте налаживали взаимодействие "настройщика" с администраторами для выполнения ряда работ. Что-то делалось сразу, в чем-то приходилось использовать весь свой дар убеждения.Приведу некоторые виды проделанных администраторами работ. Какие-то из этих работ уже выполнены и завершены, а какие-то, требующие большего времени, еще выполняются.1) Наладили регулярный сбор статистики для оптимизатора БД. a. Так исторически сложилось, что статистика для оптимизатора собиралась время от времени, по мере возникновения проблем и лишь по отдельным схемам. Это привело к тому, что оптимизатор при выборе планов запросов постоянно ошибался, так как основывался на устаревшей информации. b. После первого сбора статистики из первой десятки самых "тяжелых" запросов исчезли почти все стандартные, "некастомизированные" запросы. c. К сожалению каждого "настройщика", пользователи системы не заводят инцидентов, когда их отчеты начинают работать значительно быстрее. Они тут же привыкают к хорошему. С этим приходится мириться и оценивать достигнутый эффект техническими способами.2) Переход БД с версии 9.2.0.5 на версию 9.2.0.8. Читатели правильно отметят, что "на дворе" уже версия 10.2. Но полтора года назад делать резких изменений никто не хотел, так как Oracle продолжает оказывать техподдержку 9i и до сего дня.3) Переход версии БД с 32-битной на 64-битную. Это был знаменательный шаг. После него, можно сказать, началась эра стабильности. Шутка ли: на сервере с 60Гб оперативной памяти работал 32-битный Oracle, у которого максимальный размер SGA составляет всего 3.75Гб.4) Увеличение параметра INITRANS некоторых сегментов.
Редкий администратор ответит, не задумываясь, на вопрос о том, что такое ITL Waits. А это именование ожидания, одной из причин простоя серверов, аналог пробки на дорогах, когда и асфальт прекрасный, и машины дорогие, но никто не едет. Эти ожидания можно увидеть, если собирать отчет STATSPACK седьмого уровня, а не пятого (по умолчанию). Неправильный параметр INITRANS может стать серьезной проблемой на большом проекте. Например, российская локализация Oracle создает пару индексов на таблицу GL_JE_LINES с параметром INITRANS по умолчанию. Для сервера Oracle это означает, что в одном блоке индекса гарантированно могут сосуществовать только две активные транзакции, а остальные станут смиренно ждать в очереди (ожидание enqueue), которое в представлении V$SEGSTAT идентифицируется как ITL Waits.5) Изменение количества экстентов в сегментах базы данных, путем изменения значения STORAGE для некоторых сегментов.Первый анализ картины экстентов произвел яркое впечатление: 1% от всех сегментов состоял из 95% экстентов от общего их числа в БД.6) Правильное решение предыдущей проблемы - переход на новую модель табличных пространств (OATM). Но это требует большого "даунтайма", поэтому переход на новую модель идет постепенно, приложение за приложением.7) Настройка "buffer cache".Чтобы не утомлять читателя техническими подробностями отмечу лишь, что были настроены три вида буфферного кеша (KEEP, RECYCLE и DEFAULT).8) Сжатие некоторых таблиц.Об этом способе оптимизации пока мало известно в широких кругах. Да и применять его надо с осторожностью. Но, несмотря на низкую распространенность метода, можно достичь достаточно неожиданных результатов. Например, сжатием всего 6 таблиц, мы только за один вечер добились снижения общего числа дисковых чтений на "продуктиве" в 2-3 раза. Хочу предупредить читателя, что не стоит применять эту возможность, пока вы не изучите негативные стороны такого метода, а также не проштудируете списки обнаруженных ошибок сжатия в вашей версии Oracle. Консультации с технической поддержкой Oracle по данному вопросу также будут уместны.
Об истории перехода на 64-битный Oracle можно написать отдельную статью. В переговорах о применении этого решения не участвовал разве что генеральный директор "ВымпелКома". Но мы добивались этого не ради искусства: дополнительная память дает широкий простор для администраторов. Например, если возникает проблема с производительностью какой-либо паралельной программы в момент закрытия периода, когда уже нет времени на исследовния и оптимизацию, то за счет использования оперативной памяти можно резко поднять производительность проблемного "конкарента". Сделать это можно, например, поместив в память (KEEP BUFFER POOL) наиболее читаемые этой задачей сегменты. Например, до того, как не нашлось более эффективного решения, мы таким образом ускоряли расчет амортизации с 2-х часов до 15 минут. Позже, в спокойной обстановке, мы ускорили расчет амортизации другими методами, и теперь для этой задачи не требуется много памяти. С того дня, как мы мигрировали на 64-битный Oracle, у нас не было ни одного дефекта первого приоритета по производительности, который мы не решили бы до конца рабочего дня. Теперь у администраторов появилось мощное средство, позволяющее временно ускорять ту или иную задачу, не прерывая ее работы, чтобы позже, никуда не торопясь и не нервируя клиента, разобраться с проблемой и устранить причину ее возникновения.
Взаимодействие с разработчиками
На проекте в "ВымпелКоме" очень интересно работать тем, кто не любит ежедневного однообразия. Бизнес ставит новые задачи с завидной скоростью. На той же скорости функциональные консультанты и разработчики выдают новые решения. Нон-стопом внедряются новые модули, на EBS мигрируют новые регионы, разрабатываются новые "кастомизации".Довольно быстро стало понятно, что в одиночку за всеми проблемы не исправишь. Не смотря на достаточно высокий профессиональный уровень разработчиков, на продуктивной БД постоянно появлялись новые и новые запросы, которые требовали срочной оптимизации.
Поскольку исправлять проблему уже на "продуктиве" - дело неспокойное, мы разработали ряд действенных мер.1) Жизнь по стандартам. a. Написаны правила оформления разработок. Например, при создании таблиц и индексов разработчики уже не забывают указывать параметр INITRANS. b. Написаны автоматические проверки для часто повторяющихся ошибок. Например, если разработчик решит собрать статистику с помощью команды analyze, то он не сможет выложить разработку даже в тестирование. Проблема будет обнаружена автоматически. Это требование Oracle EBS - статистику можно собирать только пакетом FND_STATS.2) Обязательная проверка кода.Код каждой разработки просматривается руководителем группы или опытным коллегой. Свежий взгляд помогает обнаружить многие проблемы еще на этапе разработки.3) Перед установкой на тестирование администратор третьего уровня технической поддержки просматривает обработанные утилитой tkprof трассировки. Например, администратор может контролировать такие моменты, как: a. Количество уникальных SQL-запросов. Если кто-то из разработчиков по ошибке в модуле Payroll укажет предикат для person_id без переменной привязки, то сразу после запуска такого отчета продуктивная БД резко снизит свою производительность, а администраторы в STATSPACK увидят на первом месте ожидания library cache lock и library cache pin. Для предотвращения такой проблемы достаточно посмотреть отчет tkprof и не тратить ресурсы на нагрузочное тестирование. b. Общее число логических чтений. Если его поделить на 131 072, то можно получить количество гигобайт, прочитанных из БД при выполнении задачи. Например, если для подготовки справки НДФЛ-2 по одному человеку считывается 20Гб, в то время как всего данных по этому модулю - не больше 10Гб по всем компаниям и за все периоды, то сразу становится понятно: либо в алгоритме, либо в планах запросов что-то не в порядке. Почему 131 072? Потому что размер блока в БД EBS должен быть 8Кб, и именно столько блоков и есть в одном гигабайте. c. Опытный взгляд быстро определит проблему в top-запросе отчета tkprof. Таким образом, администратору не нужно просматривать весь код. Анализ пары самых "тяжелых" запросов даст нужный эффект. Если вы несколько лет подряд ежедневно анализировали отчеты STATSPACK, то поймете, о чем пишет автор статьи.
Но на этом организация процесса разработки не закончилась. Мы добились эффективного обнаружения проблем в производительности до их попадания на продуктивную среду, но столкнулись с новой проблемой. Команда разработчиков стремительно росла. Поскольку проектов, подобных вымпелкомовскому, в России не слишком много, то новые разработчики, не смотря на умение реализовывать нужный функционал, зачастую не представляли себе, с какой эффективностью их разработки поведут себя на продуктивных серверах.
Мы столкнулись с тем, что количество разработок, которые возвращались на доработку из-за проблем с производительностью, росло с угрожающей скоростью. Поверьте, каждый день говорить своим коллегам: "Вы снова сделали ошибку", - не самое приятное занятие.
И мы сделали семинары для разработчиков.
Семинары
Написано много книг по производительности Oracle. В том числе есть и книжки с однобокими советами, которые хороши для каких-то редких случаев, а у нас на проекте их применение недопустимо.Екклесиаст написал: "Составлять много книг - конца не будет, и много читать - утомительно для тела". Поэтому мы не стали ставить в обязанность всем разработчикам прочтение всех существующих книжек по оптимизации, а решили структурировать и преподать в виде семинаров 10% знаний о производительности Oracle, которые позволяют эффективно решать 99% задач на нашем проекте.
Среди прочего, темы наших семинаров касаются таких областей:
- Различия в конфигурациях тестовых и продуктивных серверов, и особенности их настройки.
- Что такое и как используются BUFFER CACHE и SHARED POOL.
- Как понимать планы запросов. Как оптимизатор выбирает порядок соединения таблиц в запросе; способы соединения таблиц и пути доступа к таблицам.
- Как читать отчеты tkprof, и каким образом сделать вывод о том, нуждается ли задача в дополнительной оптимизации, или нет.
- Как на проекте собирается статистика для оптимизатора.
- Гистограммы, переменные привязки или литеральные знания. Что и в какой момент выбрать, чтобы все работало быстро, и продуктивный сервер при этом не "упал".
- Как определить время выполнения задачи на продуктивном сервере, если доступ есть только к тестовому серверу.
Тестовые серверы
Хочется отдельно рассказать об использовании тестовых серверов. Часто можно услышать о том, что тестовый сервер должен быть точной полной копией продуктива. На это жизнь отвечает всегда одинаково: 1) Это слишком дорого. Тем более, что на большом проекте одним тестовым сервером никак не обойтись (разработка, тестирование, тестирование пользователями и т.д.) 2) Даже если поставить для тестов точную копию продуктива, то 100% совпадения времени работы задачи на тесте и продуктиве никто никогда не получит. По той причине, что нагрузка на эти сервера совершенно разная.Каков же выход? Технически, проблема тестирования производительности без использования продуктива решается просто. Если не вдаваться в технические детали, а прочитать только вывод, то, возможно, вы скажете "ерунда", и распечатаете эту статью для розжига костра на ближайших шашлыках.
Итак, о технических деталях. Они просты, и мы успешно ими пользуемся на нашем проекте. Время работы задачи на любом сервере делится на две основные составляющие: время работы процессоров (CPU) и время различных ожиданий (по-просту - время простоя). Среди известных ожиданий можно назвать дисковые чтения (db file sequential reads), latch free и другие (добро пожаловать к нам на семинары ;-). Зная разницу в мощности процессоров, можно оценить, во сколько раз изменится составляющая CPU на продуктиве. Каждое конкретное ожидание, как правило, на продуктиве либо сократится (это норма для дисковых чтений), либо вырастет, как часто происходит с ожиданием latch free. Таким образом, определив, сколько времени было потрачено на каждое ожидание на тестовом сервере, можно достаточно точно спрогнозировать время выполнения этой задачи на продуктиве. Приведу пример оптимизации процессов расчета зарплаты. Однажды один из менеджеров обеспокоился длительным расчетом зарплаты (около 8 часов по большой операционной единице). Мы оптимизировали эту задачу на самом слабом тестовом сервере и маленькой операционной единице. После окончания оптимизации время расчета на тестовом сервере выросло с 15 до 18 минут. Как вам результат? Вы готовы платить премии своим сотрудникам за такую работу? А напрасно. На продуктиве расчет вместо 8 часов завершился за один час и тридцать пять минут. В чем же дело? Мы сократили ожидания latch free, но увеличили db file sequential reads. На тестовой среде медленные диски, а на продуктиве latch free всегда вырастают, вот и весь секрет.
Что дальше
Разработчики и специалисты по тюнингу должны уметь работать с функциональными специалистами в форме диалога, а не принимать все требования безропотно, заранее ставя последних в известность о возможных проблемах с производительностью. И, естественно, предлагать альтернативные пути решения задачи.Пример: запрещать изменения в предыдущих периодах для того, чтобы избежать необходимости пересчета входящих остатков на текущий период.
Таким образом, оптимизацию производительности не следует ограничивать только техническими средствами Oracle.
О чем же была статья?
Успешные проекты не заканчиваются с окончанием внедрения. За ним идет процесс сопровождения системы, и на этом этапе важно строить процесс оптимизации производительности. Надеюсь, что автору удалось донести до читателя мысль о том, что оптимизация производительности на подобных проектах - это выстраивание целого процесса в проектной команде.novoelba.ru
oracle - Oracle - оптимизировать запрос, большую таблицу базы данных, поле CLOB
Таким образом, я навел на это свой мозг и, по общему признанию, не очень хорошо разбираюсь в Oracle. У нас есть таблица, на которой хранится около 60 миллионов записей со значениями, хранящимися в ней для зданий. Добавили соответствующие индексы, которые, по моему мнению, были пригодны, но все же плохие показатели. Вот запрос, который должен помочь:
SELECT count(*) FROM viewBuildings INNER JOIN tblValues ON viewBuildings.bldg_id = tblValues.bldg_id WHERE bldg_deleted = 0 AND (bldg_summary = 1 OR (bldg_root = 0 AND bldg_def = 0) OR bldg_parent = 1) AND field_id IN (207) AND UPPER(dbms_lob.substr(v_value, 2000, 1)) = UPPER('2320')Таким образом, вышесказанное является всего лишь одним примером запроса, который можно построить. Он ищет в tblValues в поле CLOB v_value для соответствия "2320". Он охватывает верхние строчки, поскольку он может искать как числовые, так и текстовые значения. tblValues имеет 60 миллионов записей. Он индексируется идентификатором здания, а также идентификатором поля.
Мне может потребоваться предоставить больше информации, но, насколько статистика идет, число, которое выскочило мне, было "последовательно получается". Согласованные get = 74069. Это большое число?
Любые советы будут полезны, прежде всего, при работе с полем CLOB в большой таблице базы данных. Невозможно использовать индексирование типа индекса, так как мне нужны точные соответствия, а просматриваемые данные могут быть числовыми или строковыми.
EDIT (дополнительная информация): tblBuildings является частью viewBuildings (вид), имеет 80 000 записей tblValues имеет значения каждого здания, имеет 68 000 000 записей tblValues имеет около 550 полей для каждого здания (field_id)
Желаемый результат: запрос для возврата результатов в < 5 секунд. Это необоснованно? Иногда это будет бесконечно работать, иногда может быть 80 секунд.
Объяснить результаты плана
Plan hash value: 1480138519 ----------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -----------------------------------------------------------------------------------------------------------------------| | 0 | SELECT STATEMENT | | 1 | 192 | 32 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 192 | | | | 2 | NESTED LOOPS | | 1 | 192 | 15 (0)| 00:00:01 | | 3 | NESTED LOOPS | | 1 | 183 | 12 (0)| 00:00:01 | |* 4 | FILTER | | | | | | | 5 | NESTED LOOPS OUTER | | 1 | 64 | 10 (0)| 00:00:01 | |* 6 | TABLE ACCESS BY INDEX ROWID | TBLBUILDINGS | 1 | 60 | 9 (0)| 00:00:01 | |* 7 | INDEX RANGE SCAN | SAA_4 | 17 | | 3 (0)| 00:00:01 | | 8 | NESTED LOOPS | | 1 | 21 | 3 (0)| 00:00:01 | | 9 | TABLE ACCESS BY INDEX ROWID| TBLBUILDINGSTATUSES | 1 | 15 | 2 (0)| 00:00:01 | |* 10 | INDEX RANGE SCAN | IDX_BUILDINGSTATUS_EXCLUDEQUERY | 1 | | 1 (0)| 00:00:01 | |* 11 | INDEX RANGE SCAN | IDX_BUILDING_STATUS_ASID_DELETED | 1 | 6 | 1 (0)| 00:00:01 | | 12 | TABLE ACCESS BY INDEX ROWID | TBLBUILDINGSTATUSES | 1 | 4 | 1 (0)| 00:00:01 | |* 13 | INDEX UNIQUE SCAN | PK_TBLBUILDINGSTATUS | 1 | | 0 (0)| 00:00:01 | |* 14 | TABLE ACCESS BY INDEX ROWID | TBLVALUES | 1 | 119 | 2 (0)| 00:00:01 | |* 15 | INDEX UNIQUE SCAN | PK_SAA_6 | 1 | | 1 (0)| 00:00:01 | | 16 | INLIST ITERATOR | | | | | | |* 17 | INDEX RANGE SCAN | SAA_7 | 1 | 9 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): 4 - filter("TBLBUILDINGSTATUSES"."BUILDING_STATUS_HIDE_REPORTS" IS NULL OR "TBLBUILDINGSTATUSES"."BUILDING_STATUS_HIDE_REPORTS"=0) 6 - filter("TBLBUILDINGS"."BLDG_SUMMARY"=1 OR "TBLBUILDINGS"."BLDG_SUB_BUILDING_PARENT"=1 OR "TBLBUILDINGS"."BLDG_BUILDING_DEF"=0 AND "TBLBUILDINGS"."BLDG_ROOT"=0) 7 - access("TBLBUILDINGS"."BLDG_DELETED"=0) filter( NOT EXISTS (SELECT 0 FROM "TBLBUILDINGSTATUSES" "TBLBUILDINGSTATUSES","TBLBUILDINGS" "TBLBUILDINGS" WHERE "TBLBUILDINGS"."BLDG_ID"=:B1 AND "TBLBUILDINGSTATUSES"."BUILDING_STATUS_ID"="TBLBUILDINGS"."BUILDING_STATUS_ID" AND "TBLBUILDINGSTATUSES"."BUILDING_STATUS_EXCLUDE_QUERY"=1)) 10 - access("TBLBUILDINGSTATUSES"."BUILDING_STATUS_EXCLUDE_QUERY"=1) 11 - access("TBLBUILDINGS"."BLDG_ID"=:B1 AND "TBLBUILDINGSTATUSES"."BUILDING_STATUS_ID"="TBLBUILDINGS"."BUILDING_STATUS_ID") filter("TBLBUILDINGSTATUSES"."BUILDING_STATUS_ID"="TBLBUILDINGS"."BUILDING_STATUS_ID") 13 - access("TBLBUILDINGSTATUSES"."BUILDING_STATUS_ID"(+)="TBLBUILDINGS"."BUILDING_STATUS_ID") 14 - filter(UPPER("DBMS_LOB"."SUBSTR"("TBLVALUES"."V_VALUE",2000,1))=U'2320') 15 - access("TBLVALUES"."FE_ID"=207 AND "TBLBUILDINGS"."BLDG_ID"="TBLVALUES"."BLDG_ID") 17 - access("TBLINSPECTORBUILDINGMAP"."IN_ID"=1 AND ("TBLINSPECTORBUILDINGMAP"."IAM_BUILDING_ACCESS_LEVEL"=0 OR "TBLINSPECTORBUILDINGMAP"."IAM_BUILDING_ACCESS_LEVEL"=1) AND "TBLBUILDINGS"."BLDG_ID"="TBLINSPECTORBUILDINGMAP"."BLDG_ID") 44 rows selected Plan hash value: 2137789089 --------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 | | 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 | ---------------------------------------------------------------------------------------------Хорошо, я собрал статистику, как вы сказали, а затем вот plan_table_output. Похоже, проблема IDX_CURVAL_FE_ID здесь? Это индекс в таблице значений для идентификатора поля.
SQL_ID d4aq8nsr1p6uw, child number 0 ------------------------------------- SELECT /*+ gather_plan_statistics */ count(*) FROM viewAssetsForUser1 INNER JOIN tblCurrentValues ON viewAssetsForUser1.as_id = tblCurrentValues.as_id WHERE as_deleted = :"SYS_B_0" AND (as_summary = :"SYS_B_1" OR (as_root = :"SYS_B_2" AND as_asset_def = :"SYS_B_3") OR as_sub_asset_parent = :"SYS_B_4") AND fe_id IN (:"SYS_B_5") AND UPPER(dbms_lob.substr(cv_value, :"SYS_B_6", :"SYS_B_7")) = UPPER(:"SYS_B_8") Plan hash value: 4033422776 ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 1 |00:08:43.19 | 56589 | 56084 | | | | | 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:08:43.19 | 56589 | 56084 | | | | |* 2 | FILTER | | 1 | | 0 |00:08:43.19 | 56589 | 56084 | | | | | 3 | NESTED LOOPS | | 1 | | 0 |00:08:43.19 | 56589 | 56084 | | | | | 4 | NESTED LOOPS | | 1 | 115 | 0 |00:08:43.19 | 56589 | 56084 | | | | |* 5 | FILTER | | 1 | | 0 |00:08:43.19 | 56589 | 56084 | | | | |* 6 | HASH JOIN RIGHT OUTER | | 1 | 82 | 0 |00:08:43.19 | 56589 | 56084 | 1348K| 1348K| 742K (0)| | 7 | TABLE ACCESS FULL | TBLASSETSTATUSES | 1 | 4 | 4 |00:00:00.01 | 3 | 0 | | | | | 8 | NESTED LOOPS | | 1 | | 0 |00:08:43.19 | 56586 | 56084 | | | | | 9 | NESTED LOOPS | | 1 | 163 | 0 |00:08:43.19 | 56586 | 56084 | | | | |* 10 | TABLE ACCESS BY INDEX ROWID | TBLCURRENTVALUES | 1 | 163 | 0 |00:08:43.19 | 56586 | 56084 | | | | |* 11 | INDEX RANGE SCAN | IDX_CURVAL_FE_ID | 1 | 16283 | 61357 |00:00:05.98 | 132 | 132 | | | | |* 12 | INDEX RANGE SCAN | SAA_1 | 0 | 1 | 0 |00:00:00.01 | 0 | 0 | | | | |* 13 | TABLE ACCESS BY INDEX ROWID | TBLASSETS | 0 | 1 | 0 |00:00:00.01 | 0 | 0 | | | | |* 14 | INDEX UNIQUE SCAN | PK_TBLINSPECTORBRIDGEMAP2 | 0 | 1 | 0 |00:00:00.01 | 0 | 0 | | | | |* 15 | TABLE ACCESS BY GLOBAL INDEX ROWID| TBLINSPECTORASSETMAP | 0 | 1 | 0 |00:00:00.01 | 0 | 0 | | | | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter(:SYS_B_0=0) 5 - filter(("TBLASSETSTATUSES"."ASSET_STATUS_HIDE_REPORTS" IS NULL OR "TBLASSETSTATUSES"."ASSET_STATUS_HIDE_REPORTS"=0)) 6 - access("TBLASSETSTATUSES"."ASSET_STATUS_ID"="TBLASSETS"."ASSET_STATUS_ID") 10 - filter(UPPER("DBMS_LOB"."SUBSTR"("TBLCURRENTVALUES"."CV_VALUE",:SYS_B_6,:SYS_B_7))=SYS_OP_C2C(UPPER(:SYS_B_8))) 11 - access("TBLCURRENTVALUES"."FE_ID"=:SYS_B_5) 12 - access("TBLASSETS"."AS_DELETED"=:SYS_B_0 AND "TBLASSETS"."AS_ID"="TBLCURRENTVALUES"."AS_ID") 13 - filter((("TBLASSETS"."AS_ROOT"=:SYS_B_2 AND "TBLASSETS"."AS_ASSET_DEF"=:SYS_B_3) OR "TBLASSETS"."AS_SUMMARY"=:SYS_B_1 OR "TBLASSETS"."AS_SUB_ASSET_PARENT"=:SYS_B_4)) 14 - access("TBLASSETS"."AS_ID"="TBLINSPECTORASSETMAP"."AS_ID" AND "TBLINSPECTORASSETMAP"."IN_ID"=1) 15 - filter(("TBLINSPECTORASSETMAP"."IAM_ASSET_ACCESS_LEVEL"=0 OR "TBLINSPECTORASSETMAP"."IAM_ASSET_ACCESS_LEVEL"=1))qaru.site