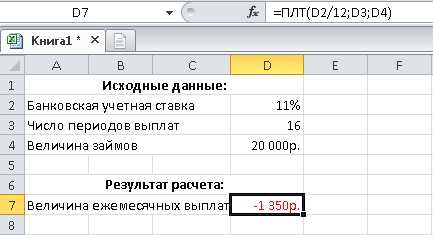
Оптимизация запросов в ORACLE при помощи плана выполнения. Оптимизация oracle
Оптимизация - oracle
Процесс ест слишком много памяти или ресурсов CPU Например мы обнаружили периодически или постоянно возникающий на сервере процесс, который ест слишком много памяти или процессорного времени. Первое что необходимо сделать - это узнать его PID (Process ID). На Unix-подобных системах мы его увидим непосредственно в выводе команды top или ps. На windows часть процессов распараллеливается на нити и их pid не видны в диспетчере задач. Чтобы узнать требуемый PID я предпочитаю использовать программы третьих фирм например Process Explorer от Sysinternals. (в данный момент скачать можно на microsoft technet). Когда PID известен, я делаю запрос к БД вида select ses.*, ps.SPID from v$session ses, v$process ps where ps.ADDR = ses.PADDR and ps.SPID = 'xxxx'где xxxx - это ID "жручего" процесса. В полученных данных сразу можно увидеть много полезного. Первое - это столбцы SID и SERIAL# - этих столбцов достаточно чтобы сделать kill session. В случае взаимодействия типа клиент - сервер интерес представляют столбики USERNAME MACHINE PROGRAM которые сразу дают представление о приложении из которого сделан запрос загрузивший сервер. В случае OEBS эти столбики довольно бесполезны, т.к. там будет практически одна и та же информация, зато в полях MODULE и ACTION можно увидеть модули которые работают в этих сессиях и разобрать пользователя и конкретную форму откуда идёт обращение в случае если пользователь работает внутри форм. Когда проблема локализована вплоть до сессии и модуля, то можно заглянуть в представления в которых можно посмотреть все текущие запросы и длительные запорсы которые были произведены за последнее время : V$SESSION_LONGOPS, V$SQLAREA
Конкретного "тяжёлого" процесс не видно, но система всё равно "тормозит" Причин такого поведения может быть масса. Разбираться конечно нужно в каждом конкретном случае. Но что обычно может сделать администратор не залезая и не оптимизируюя код запросов и хранимых процедур? Настроить параметры физического расположения данных. Физическое расположение данных на дисковой системе лучше наверное планировать с учётом "классических" советов по планированию архитектуры хранилища. Например redo логи не должны лежать вместе с archive логами. И желательно чтобы это всё было отделено от основных файлов с данными. Физическое размещение в памяти в первую очередь зависит от режима работы БД - выделенный (dedicated) сервер или общий (shared). Конечно в зависимости от задач в первую очередь надо выбрать один из этих вариантов а потом уже оптимизировать распределение памяти между процессами и пулами. Помощь в подобного рода оптимизации могут оказать представления sys.v_$pgastat; sys.v_$sgastat.
Попробовать найти "тяжёлые" запросы которые могут появляться в различных сессиях. В этом плане незаменим запрос к представлению V_$SESSION_LONGOPS. Там в идеале должны быть только записями о работе RMAN - т.к. в нём никак не обойтись без полного сканирования таблиц и т.п. Если там появляется нечто другое - это сигнал к началу разбирательства. Как правило все проблемы в запросах решаются более качественным переписыванием оных, созданием индексов и изменениями параметров распределения памяти для процессов.
Витрины данных. Когда нужно представить сложный аналитический отчёт в котором, например, данные собираются из 20-ти представлений и таблиц, и в этих таблицах достаточно большое количество данных, а свяывание происходит не по полю, а , например по какому -либо агрегированному признаку, то тут конечно оптимизировать запрос трудно. Тогда можно поступить иначе - создать "витрину данных". т.е создать отдельную таблицу требуемого вида, а заполнять её например раз в сутки ночью. или повесить триггеры на изменяемые таблицы и добавлять на витрину данные по мере поступления.
oracle.imagenesis.ru
Оптимизация запроса Oracle Безопасный SQL
Этот запрос занимает 153 секунды. есть миллионы строк в VERIFICATION_TABLE .
Я думаю, что запрос занимает много времени из-за функций в where where. Тем не менее, мне нужно сделать ltrim rtrim в столбцах, а также дату необходимо сопоставить в формате MM/DD/YYYY . Как я могу оптимизировать этот запрос?
Хотя в плане объяснения я не вижу индексов / первичного ключа. это проблема?
Попробуй это:
SELECT MAX(verification_id) FROM VERIFICATION_TABLE WHERE head = 687422 AND mbr = 23102 AND TRIM(lname) = '.iq bzw' AND TRUNCATE(dob) = TO_DATE('08/10/2004') AND system_code = 'M';Удалите этот TRUNCATE() если у dob нет времени на него уже, из его взглядов (Дата рождения?) Это может быть не так. В прошлом, вам нужна работа по индексированию. Если вы так много разбираетесь в этом стиле, я бы индексировал mbr и head индекс в 2 столбца, если бы вы сказали, что означают столбцы, это поможет определить наилучшую индексацию здесь.
Единственным индексом, который является возможным кандидатом для использования в вашем запросе, является N_VRFTN_IDX2, поскольку он индексирует четыре столбца, которые вы используете в своем предложении WHERE: HEAD, MBR, DOB и LNAME.
Однако, поскольку вы применяете функции как к DOB, так и LNAME, они не могут быть рассмотрены. Затем оптимизатор может не использовать этот индекс, потому что считает, что HEAD + MBR сам по себе является недостаточно избирательной комбинацией. Если вы удалили вызов TO_CHAR () из DOB, то у вас есть три ведущих столбца на N_VRFTN_IDX2, которые могут сделать его более привлекательным для оптимизатора. Аналогично, необходимо ли TRIM () LNAME?
Другое дело, необходимость поиска SYSTEM_CODE означает, что запрос должен считываться из таблицы (поскольку этот столбец не индексируется). Если N_VRFTN_IDX2 имеет плохую факторизацию кластеризации, оптимизатор может решить пойти в FULL TABLE SCAN, потому что индексированные чтения являются накладными расходами. Если вы добавили SYSTEM_CODE в индекс, весь запрос мог бы быть удовлетворен с помощью INDEX RANGE SCAN, что было бы намного быстрее.
Наконец, насколько свежи ваши статистические данные? Если ваша статистика устарела, это может привести к тому, что оптимизатор примет решение о даффе. Например, более точная статистика может заставить оптимизатора использовать составной индекс даже с двумя ведущими столбцами.
Вы должны превратить литерал в DATE, а не в столбец в VARCHAR2 следующим образом:
AND dob = TO_DATE('08/10/2004','MM/DD/YYYY')Или используйте предпочтительный синтаксис синтаксиса даты ANSI:
AND dob = DATE '2004-08-10'Если столбец dob содержит время (дата рождения не обычно, кроме предположительно в больнице!), То вы можете сделать:
Проверьте типы данных для HEAD и MBR. Значения «687422 и 23102» имеют «чувство», что они достаточно избирательны. То есть, если у вас есть сотни тысяч значений для главы и миллионов записей в таблице, кажется, что HEAD является довольно избирательным. [Это может быть совершенно неверно.]
В любом случае, вы можете обнаружить, что HEAD и / или MBR фактически хранятся как поля VARCHAR2 или CHAR, а не NUMBER. Если это так, сравнение символа с числом будет препятствовать использованию индекса. Попробуйте следующее (и я включил преобразование предиката dob с датой, но добавил маску явного формата).
SELECT MAX(verification_id) FROM VERIFICATION_TABLE WHERE head = '687422' AND mbr = '23102' AND RTRIM(LTRIM(lname)) = '.iq bzw' AND TRUNCATE(dob) = TO_DATE('08/10/2004','MM/DD/YYYY') AND system_code = 'M';Пожалуйста, предоставьте вывод EXPLAIN в этом запросе, чтобы мы знали, где происходит замедление. Две мысли:
изменение
AND TO_CHAR(dob,'MM/DD/YYYY')= '08/10/2004'в
AND dob = <date here, not sure which oracle str2date function you need>Попробуй это:
SELECT MAX(verification_id) FROM VERIFICATION_TABLE WHERE head = 687422 AND mbr = 23102 AND TRIM(lname) = '.iq bzw' AND dob between TO_DATE('08/10/2004') and TO_DATE('08/11/2004') AND system_code = 'M';Таким образом, будет использоваться возможный индекс на dob.
sql.fliplinux.com
optimization - Оптимизация запроса SELECT, который работает медленно в Oracle, который быстро запускается на SQL Server
Я пытаюсь запустить следующий SQL-оператор в Oracle, и для запуска требуется возраст:
SELECT orderID FROM tasks WHERE orderID NOT IN (SELECT DISTINCT orderID FROM tasks WHERE engineer1 IS NOT NULL AND engineer2 IS NOT NULL)Если я запускаю только часть, содержащуюся в предложении IN, которая выполняется очень быстро в Oracle, то есть
SELECT DISTINCT orderID FROM tasks WHERE engineer1 IS NOT NULL AND engineer2 IS NOT NULLПочему весь Oracle занимает такое долгое время в Oracle? В SQL Server весь оператор выполняется быстро.
В качестве альтернативы есть более простой/отличный/лучший оператор SQL, который я должен использовать?
Дополнительная информация о проблеме:
- Каждый заказ выполнен из множества задач
- Каждый заказ будет выделен (одна или несколько его задач будут установлены инженером и инженером2) или порядок может быть нераспределенным (вся его задача имеет нулевые значения для инженерных полей)
- Я пытаюсь найти все идентификаторы orderID, которые нераспределены.
На всякий случай это имеет значение, в таблице есть ~ 120 тыс. строк и 3 задания на заказ, поэтому ~ 40 тыс. разных заказов.
Ответы на ответы:
- Я бы предпочел оператор SQL, который работает как в SQL Server, так и в Oracle.
- Задачи имеют только индекс на идентификаторе orderID и taskID.
- Я попробовал версию NOT EXISTS, но она длилась более 3 минут, прежде чем я отменил ее. Возможно, нужна версия JOIN для утверждения?
- Существует таблица "заказы", а также столбец orderID. Но я пытался упростить вопрос, не включив его в исходный оператор SQL.
Я предполагаю, что в исходном выражении SQL подзапрос запускается каждый раз для каждой строки в первой части инструкции SQL - даже если она статическая и ее нужно запускать только один раз?
Выполнение
ANALYZE TABLE tasks COMPUTE STATISTICS;сделал мой исходный оператор SQL выполняться намного быстрее.
Хотя мне все еще интересно, почему я должен это делать, и если/когда мне нужно будет запустить его снова?
Статистика дает Oracle информацию об оптимизации на основе стоимости, которая ему необходимо определить эффективность различных планов выполнения: для Например, количество строк в таблице, средняя ширина строк, максимальная и наименьшие значения за столбец, количество разные значения для столбца, кластеризация коэффициент индексов и т.д.
В небольшой базе данных вы можете просто настроить каждую неделю собирать статистику и оставить его в покое. На самом деле это значение по умолчанию менее 10g. Для более крупных реализаций, которые вы обычно должны взвешивать стабильность исполнения планы против того, чтобы данные изменения, которые представляют собой сложный баланс.
Oracle также имеет функцию, называемую "динамическая выборка", которая используется для примеры таблиц для определения соответствующих статистика во время выполнения. Это гораздо чаще используется с данными складов, где накладные расходы отбор проб был перевешен потенциальное увеличение производительности для долгосрочный запрос.
qaru.site
Мониторинг Oracle: оптимизация и тюнинг
В случае возникновения проблем с производительностью требуются оптимизация и тюнинг. В большинстве случаев требуется оптимизация собственно кода приложения, но иногда и настройка плохо отлаженной среды может существенно повысить производительность.
В этой заметке пойдет речь о нескольких возможных способах тюнинга. Некоторые из них ориентированы на базы данных Oracle, другие подходят к серверам любых БД, ну а остальные – на любые сервера. Обо всем мы не расскажем, и несомненно существуют другие способы тюнинга, которые могут быть более эффективными для ваших приложений.
Тюнинг предполагает длинный и повторяющийся процесс тестирования и анализа. Любое изменение конфигурации требует тщательной проверки. Прежде чем прибегнуть к любому из перечисленных ниже способов, необходимо проверить его применимость к конфигурации конкретного приложения с помощью анализа параметров и сгенерированной рабочей нагрузки на сервере.
- Убедитесь, что Оптимизатор Затрат Oracle(Cost Based Optimizer) запущен
- Регулярно собирайте статистику оптимизатора
- Оптимизируйте SQL запросы:
- Определите проблемные SQL запросы (то есть те, которые слишком долго выполняются)
- Проанализируйте по ним статистику Oracle оптимизатора (убедитесь, что данные актуальны)
- Проанализируйте план выполнения
- При необходимости измените структуру SQL запросов
- При необходимости измените структуру индекса
- Видоизменяйте планы выполнения с течением времени
- Используйте связанные переменные в SQL запросах. Это поможет сократить количество курсоров, хранящихся в общем пуле.
- Аккуратно используйте индексы. Не стоит индексировать все столбцы, а только те, к которым обращается больше всего запросов.
- Помогите SQL оптимизатору с помощью подсказок (optimization hints). Это следует делать после анализа производительности SQL запросов.
- Оптимизируйте размер структур памяти. Размер Общего Пула, Буферного Кэша и других структур памяти критичен для производительности баз данных.
- Смоделируйте стандартную рабочую нагрузку приложения.
- Мониторьте ожидания, попадания в кэш, подкачку и своп страниц и т.д.
- Вот перечень самых основных параметров, которые нуждаются в тюнинге:
Параметр Описание
db_cache_size – Определяет размер буферного кэша в SGA.
db_keep_cache_size – Объекты, попавшие в этот кэш, остаются в нем навсегда. Сюда помещают те объекты, к которым чаще всего обращаются и которые должны сохраняться в памяти. Например, маленькие часто используемые таблицы поиска. Этот кэш – один из кэшей по умолчанию, и задается параметром DB_CACHE_SIZE. Это обязательный параметр для любой БД.
shared_pool_size – Определяет размер Общего Пула.
pga_aggregate_target – Задает общую целевую память PGA, доступную для всех серверных процессов связанных с экземпляром БД.
log_buffer – Определяет размер буфера журнала изменений.
query_rewrite_enabled – Определяет, может ли Oracle изменить SQL оператор, прежде чем его выполнить.
cursor_sharing – Определяет, какие SQL операторы могут иметь общие курсоры.
db_file_multiblock_read_count – Один из параметровиспользуемых для минимизации операций ввода/вывода во время полного сканирования таблицы. Определяет максимальное количество чтений блоков за одну операцию ввода/вывода на протяжении последовательного сканирования.
hash_multiblock_io_count – Определяет, сколько последовательных блоков соединение хэшированием может прочесть или записать за операцию ввода/вывода.
- Чтобы уменьшить количество операций ввода/вывода, необходимо стремиться получить высокий коэффициент buffer-cache hit. В среде OLTP он должен быть больше 80 в среде OLTP. Ну а идеал – 99.
- Коэффициент Dictionary cache hit должен быть около 90%. Записей по dc_table_grants, d_user_grants, и dc_users должно быть меньше 5% в колонке MISS RATE %.
- Monitor Sorts показывает соотношение между сортировкой на диске и памятью. Этот показатель должен быть меньше 0.10.
- Сведите к минимуму борьбу за ресурсы базы данных. Проанализируйте количество блокировок и устраните все возможные.
devopshub.net
Оптимизация запросов в ORACLE при помощи плана выполнения — Life in Code
Сразу уточню, что описывать буду на примере использования фри утилиты OraDeveloper Studio. Почему? Потому что обычными запросами этого сделать не удалось, а времени и желания разбираться не было, раз уж есть способ проще. 😉
Итак, для чего это вообще нужно? Опишу вам конкретный пример, из-за которого я и был вынужден проводить оптимизацию.Задача — грузить в базу десятки тысяч строк данных. Для каждой строки необходимо предварительно по базе найти дополнительные данные одним довольно громоздким запросом (4 таблицы через джойны).Проблема — загрузка 15 тысяч строк занимает 8-9 часов. Так как по условиям задачи загружать надо часто, а не один раз в пятилетку… В общем, надо довести время до приемлемого.
Что я сделал?1. Выяснил, что тормозит именно селект (данные вставляются и обновляются в таблицах, где куча строк и часть из таблиц не имеет ни индексов, ни ключей — отсюда и сомнения в вине селекта).2. Проверил наличие индексов на используемых запросом полях. Добавил отсутствующие.3. Спросил помощи у знающих. 🙂
Знающие посоветовали проанализировать план выполнения запроса и объяснили, как это сделать в OraDev.Создаём новое окно запроса (Ctrl+N). Копируем в него наш запрос. Жмём Alt+G. Выбираем уже существующую либо создаём новую таблицу плана.После выполнения появится дерево плана выполнения. Самостоятельно и без поллитры в нём разобраться не так просто. 😉
Что же нас интересует в этом дереве? Нас интересуют узлы (шаги), для которых указан большой Cost шага. Цену шага вы можете увидеть в свойствах шага (у меня окошко свойств постоянно открыто и потому мне надо лишь выбрать нужный шаг; вам же может потребоваться выбирать свойства по правому клику на шаге). Отыскиваем медленный шаг (самый верхний узел, корень дерева плана, в расчёт особенно не берём — там будет указана общая цена запроса, а мы итак уже знаем, что проблема именно в этом запросе). Нашли? Теперь смотрим, с какой таблицей, какими её полями и с каким количеством строк работает шаг — это есть в свойствах и имени шага. Смотрим и думаем, почему у нас так медленно?У меня, например, один из шагов работал с 4000 записей вместо одной-трёх записей (не тысяч). Такого быть не должно было в принципе — я же ограничиваю выборку именно для того, чтобы выбирать из нужного диапазона, а не из кучи лишнего барахла. Внимательно присмотревшись к условию джойна, я заметил, что упустил одно из полей. Добавил поле в запрос и всё встало на свои места. Цена запроса (полная) уменьшилась с 531 до 6. 🙂
Спасибо камрадам nest и detect за помощь.
P.S. Извините, что не приводу скриншоты. С ними было бы намного нагляднее, но… Из-за конфиденциальности некоторой информации пришлось бы замазывать 80% и тогда опять вышло бы малопонятно.P.P.S. Общее время загрузки существенно сократилось. На загрузку в базу 17.5 тысяч строк данных ушло 12 минут. В сравнении с 8-9 часами… Ну, вы и сами всё уже поняли. 😉
life-in-code.com
Об Oracle на русском: Oracle Database 11g: Настройка производительности
Генератор планов исследует множество планов выполнения запроса для блока запроса используя разные пути доступа к данным, методы и порядок объединения. В конечном счете генератор планов передает на исполнение вашего выражения лучший план. НА рисунке представлен файл трассировки оптимизатора для выполняемого запроса. Как видно на рисунке генератор планов построил 6 возможных планов выполнения запроса: два порядка соединения, и для каждого из них три разных типа соединения. Предполагается, что для таблиц, к которым обращается выражение нет индексов.
В примере выше соединяются две таблицы: DEPARTMENTS и EMPLOYEES. Для данного выражения может быть использовано 3 возможных метода соединения: Nested Loop, Sort Merge или HASH JOIN. Для каждого из планов указана стоимость. В данном случае оптимальным является план с методом соединения № 1.
Генератор планов использует внутренний механизм, который позволяет отбросить планы с более высокой стоимостью для сокращения времени обработки выражения. Если текущий оптимальный план имеет высокую стоимость, генератор планов более детально исследует планы исполнения и пытается сгенерировать более оптимальный план. Как только достигнута оптимальная стоимость выполнения для запроса, генератор планов останавливает поиск планов исполнения.
Контроль поведения оптимизатора
Поведение оптимизатора можно контролировать используя следующие параметры инициализации:
CURSOR_SHARING: определяет каким образом SQL выражение может разделить (повторно использовать) существующие курсоры:
- FORCE: Заставляет разделять курсор выражения, которые могут отличаться в нескольких символах без изменения смысла выражения.
- SIMILAR: Заставляет разделять курсор выражения, которые могут отличаться в нескольких символах без изменения смысла выражения или степени оптимизации плана выполнения выражения. Может влиять на производительность в DSS системах которые используют опорные линии для оптимизации планов выполнения.
- EXACT: Разделяют курсоры только полностью идентичные выражения. Значение по умолчанию.
DB_FILE_MULTIBLOCK_READ_COUNT - один из параметров, который можно использовать для минимизации ввода/вывода в процессе сканирования таблиц или быстрого сканирования индексов (index fast full scan). Он определяет максимальное число блоков, считываемых за одну операцию ввода / вывода при последовательном сканировании. Общее число операций ввода/вывода, необходимое для сканирования объекта зависит от таких факторов, как размер сегмента и использование параллельного выполнения для операции обработки. Значением по умолчанию этого параметра является значение, которое соответствует максимальному размеру ввода / вывода, который может быть выполнен эффективно. Это значение зависит от платформы и рассчитывается при запуске экземпляра для большинства платформ.
Поскольку параметр измеряется в блоках, он автоматически вычисляет значение, равное максимальному размеру ввода / вывода, который может быть выполнен эффективно, деленному на стандартный размер блока. Обратите внимание, что если число сессий очень велико,значение счетчика мультиблочного чтения уменьшается, чтобы избежать переполнения кэша буферов. Несмотря на то что значение по умолчанию может быть большим, оптимизатор не выбирает большие планы, если не установить этот параметр. Он будет делать это, только если явно установить этот параметр в большое значение. В принципе, если этот параметр не задан явно (или установлен 0), оптимизатор использует значение по умолчанию 8 при определении затрат на полные сканирования таблиц и индексов быстрого полного сканирования. Системы обработки транзакций (OLTP) и пакетные среды, как правило, имеют значения в диапазоне от 4 до 16 для этого параметра. DSS и среды хранения данных, как правило, получают наибольшую выгоду от максимизации значения этого параметра. Оптимизатор более вероятно, выберет полное сканирование таблицы вместо использования индекса, если значение этого параметра высокое.
PGA_AGGREGATE_TARGET - указывает количество памяти, выделяемое для PGA и доступное для всех серверных процессов подключенных к экземпляру. Установка параметра PGA_AGGREGATE_TARGET в не нулевое значение вызывает автоматическую установку параметра WORKAREA_SIZE_POLICY в значение AUTO. Это значит, что размер рабочих областей памяти используемых SQL операциями, затрачивающими большое количество ресурсов, такими как сортировка, группировка, HASH объединение или создание битовой карты будет управляться автоматически. По умолчанию значение параметра PGA_AGGREGATE_TARGET установлено в значение равное 20% от SGA.
STAR_TRANSFORMATION_ENABLED Определяет возможность использования трансформации типа "звезда" в процессе обработки запросов.
Оптимизатор запросов использует механизм кеширования результатов в зависимости от значения параметра RESULT_CACHE_MODE. Возможные значения параметра: MANUAL и FORCE
- Когда установлено значение MANUAL, вы должны в ручную указать HINT для оптимизатора, чтобы результат выполнения был помещен в кэш результатов.
- Когда параметр установлен в значение FORCE все результаты сохраняются в кэше результатов. Выражения в тексте которых указан HINT [NO_]RESULT_CACHE имеют более высокий приоритет перед значением системного параметра.
Размер памяти, выделенной для кэша результатов зависит от объема памяти SGA, а также системы управления памятью. вы можете изменить размер, выделяемый для кэша результатов установив соответствующее значение параметра RESULT_CACHE_MAX_SIZE.
Параметр RESULT_CACHE_MAX_RESULT определяет максимальное количество памяти в кэше результатов, которое может занимать один результат. Значение по умолчанию - 5%, можно указать любое значение от 1 до 100%.
Используя параметр RESULT_CACHE_REMOTE_EXPIRATION можно установить время (в минутах), которое будет действителен результат использующий удаленные объекты. Значение по умолчанию - 0, кеширование результатов обработки удаленных объектов запрещено. Установка этого параметра в не нулевое значение может заставить СУБД хранить в кэше результатов устаревшие результаты, например, если удаленная таблица используемая в результате изменяется в удаленной базе данных.
OPTIMIZER_INDEX_CACHING Этот параметр управляет расчетом стоимости кеширования индекса в сочетании с вложенным циклом или inlist итератором. Диапазон значений от 0 до 100 OPTIMIZER_INDEX_CACHING определяет процент блоков индексов в буферном кэше, который указывает оптимизатору на возможность кэширования индекса для вложенных циклов и inlist итераторов. Значение 100 предполагает, что 100% из блоков индексов, вероятно, будут найдены в кэше буферов и оптимизатор регулирует стоимость сканирования индекса или применения вложенного цикла соответственно. По умолчанию значение для этого параметра равно 0, что приводит к поведению оптимизатора по умолчанию. Будьте осторожны при использовании этого параметра, поскольку планы выполнения могут измениться в пользу кэширования индекса.
OPTIMIZER_INDEX_COST_ADJ позволяет управлять поведением оптимизатора в части выбора путей доступа с использованием индексов, то есть, чтобы сделать оптимизатор более или менее склонным к выбору пути доступа через индекс вместо полного сканирования таблицы. Диапазон значений составляет от 1 до 10000. Значение по умолчанию для этого параметра составляет 100 процентов, при этом оптимизатор оценивает пути доступа через индекс по обычной стоимости. Любое другое значение заставляет оптимизатор оценивать путь доступа на указанный процент от обычной стоимости. Например, значение 50 делает доступ по индексу в два раза дороже, его нормальной стоимости.
OPTIMIZER_MODE устанавливает режим работы по умолчанию для выбора подхода к оптимизации для любого экземпляра или сессии. Возможные значения:- ALL_ROWS: Оптимизатор использует стоимостной подход для всех SQL выражений сессии независимо от наличия статистики и оптимизирует их для достижения максимально возможной пропускной способности (минимальное использование ресурсов для обработки выражения). Значение по умолчанию.
- FIRST_ROWS_n: Оптимизатор использует стоимостной подход для всех SQL выражений сессии независимо от наличия статистики и оптимизирует их для достижения максимально быстрого времени ответа возвращая n количество строк. N может принимать значения 1,10,100,1000.
- FIRST_ROWS: Оптимизатор использует смешанный стоимостной и эвристический анализ для нахождения оптимального плана выполнения, задачей которого является вывод первых строк клиенту. Использование эвристики иногда приводит к генерации оптимизатором плана с значительно более высокой стоимостью, чем без использования эвристики. FIRST_ROWS работает только для обратной совместимости, рекомендуется использовать FIRST_ROWS_n.
Возможности оптимизатора в разных релизах СУБД Oracle
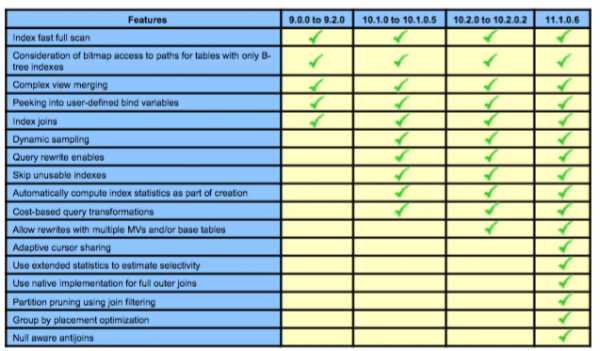
oracleonrussian.blogspot.com
sql - Оптимизация запросов Oracle
Использование аналитики, а затем применение оператора DISTINCT - это не путь, когда вам нужно агрегировать.
Вот более простая и более эффективная версия, использующая только агрегаты:
SQL> select a.id 2 , max(t.type_id) keep (dense_rank last order by t.create_date) max_create_date_type_id 3 , max(a.assign_id) keep (dense_rank last order by t.create_date) assign_id 4 from assignment a 5 , type t 6 where a.type_id = t.type_id 7 group by a.id 8 / ID MAX_CREATE_DATE_TYPE_ID ASSIGN_ID -- ----------------------- ---------- 1x 3 664 2x 4 514 2 rows selected.И вот тест, чтобы доказать его более высокую производительность:
SQL> exec dbms_stats.gather_table_stats(user,'assignment') PL/SQL procedure successfully completed. SQL> exec dbms_stats.gather_table_stats(user,'type') PL/SQL procedure successfully completed. SQL> select /*+ gather_plan_statistics */ 2 distinct 3 a.id, 4 first_value(t.type_id) 5 over (partition by a.id order by t.create_date desc) 6 as max_create_date_type_id, 7 first_value(a.assign_id) 8 over (partition by a.id order by t.create_date desc) 9 as assign_id 10 from assignment a, type t 11 where a.type_id = t.type_id 12 / ID MAX_CREATE_DATE_TYPE_ID ASSIGN_ID -- ----------------------- ---------- 2x 4 514 1x 3 664 2 rows selected. SQL> select * from table(dbms_xplan.display_cursor(null,null,'allstats last')) 2 / PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------- SQL_ID fu520w4kf2bbp, child number 0 ------------------------------------- select /*+ gather_plan_statistics */ distinct a.id, first_value(t.type_id) over (partition by a.id order by t.create_date desc) as max_create_date_type_id, first_value(a.assign_id) over (partition by a.id order by t.create_date desc) as assign_id from assignment a, type t where a.type_id = t.type_id Plan hash value: 4160194652 ------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.01 | 6 | | | | | 1 | HASH UNIQUE | | 1 | 4 | 2 |00:00:00.01 | 6 | 898K| 898K| 493K (0)| | 2 | WINDOW SORT | | 1 | 4 | 4 |00:00:00.01 | 6 | 2048 | 2048 | 2048 (0)| | 3 | WINDOW SORT | | 1 | 4 | 4 |00:00:00.01 | 6 | 2048 | 2048 | 2048 (0)| |* 4 | HASH JOIN | | 1 | 4 | 4 |00:00:00.01 | 6 | 898K| 898K| 554K (0)| | 5 | TABLE ACCESS FULL| ASSIGNMENT | 1 | 4 | 4 |00:00:00.01 | 3 | | | | | 6 | TABLE ACCESS FULL| TYPE | 1 | 4 | 4 |00:00:00.01 | 3 | | | | ------------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 4 - access("A"."TYPE_ID"="T"."TYPE_ID") 28 rows selected. SQL> select /*+ gather_plan_statistics */ 2 a.id 3 , max(t.type_id) keep (dense_rank last order by t.create_date) max_create_date_type_id 4 , max(a.assign_id) keep (dense_rank last order by t.create_date) assign_id 5 from assignment a 6 , type t 7 where a.type_id = t.type_id 8 group by a.id 9 / ID MAX_CREATE_DATE_TYPE_ID ASSIGN_ID -- ----------------------- ---------- 1x 3 664 2x 4 514 2 rows selected. SQL> select * from table(dbms_xplan.display_cursor(null,null,'allstats last')) 2 / PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------- SQL_ID 156kpxgxmfjd3, child number 0 ------------------------------------- select /*+ gather_plan_statistics */ a.id , max(t.type_id) keep (dense_rank last order by t.create_date) max_create_date_type_id , max(a.assign_id) keep (dense_rank last order by t.create_date) assign_id from assignment a , type t where a.type_id = t.type_id group by a.id Plan hash value: 3494156172 ----------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ----------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.01 | 6 | | | | | 1 | SORT GROUP BY | | 1 | 2 | 2 |00:00:00.01 | 6 | 2048 | 2048 | 2048 (0)| |* 2 | HASH JOIN | | 1 | 4 | 4 |00:00:00.01 | 6 | 898K| 898K| 594K (0)| | 3 | TABLE ACCESS FULL| ASSIGNMENT | 1 | 4 | 4 |00:00:00.01 | 3 | | | | | 4 | TABLE ACCESS FULL| TYPE | 1 | 4 | 4 |00:00:00.01 | 3 | | | | ----------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("A"."TYPE_ID"="T"."TYPE_ID") 25 rows selected.Как вы можете видеть, оба полностью сканируют таблицы и выполняют хеш-соединение. Разница заключается в следующем шаге. Агрегатный вариант занимает 4 строки и объединяет их в 2 строки с помощью команды SORT GROUP By. Аналитическая первая сначала сортирует 4-рядный набор, а затем применяет HASH UNIQUE, чтобы уменьшить набор до 2 строк.
С уважением, Роб.
qaru.site