ASUS RT-AC5300 и ASUS RT-AC88U: сверхскоростные высокопроизводительные маршрутизаторы. Asus оптимизация агрегации ampdu
Настройка роутера Asus RT-N16 (Asus WL-500gV2.) (часть 3). « Blog of Khlebalin Dmitriy
Настройка роутера Asus RT-N16 (Asus WL-500gV2.) (часть 3).
Пришло время продолжить ранее начатую настройку, описанную мною здесь:
https://khlebalin.wordpress.com/category/wi-fi/
Режим фильтрации MAC-адресов – Отключено – принимать всех, верно указавших пароль доступа к Wi-Fi роутерf, Принимать – принимать только тех, кто верно указал пароль доступа к сети Wi-Fi роутера и у которых MAC-адрес указан в списке ниже – рекомендованный режим – даже если и подберут пароль к вашей wi-fi сети – роутер не разрешит подключится (не забудьте добавить свои mac-адреса устройств), Отклонять – не разрешать подключатся к wi-fi сети роутера, mac-адресам указанным в списке, даже если они верно указали пароль доступа.
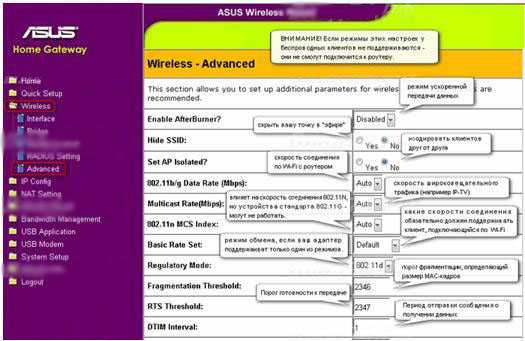
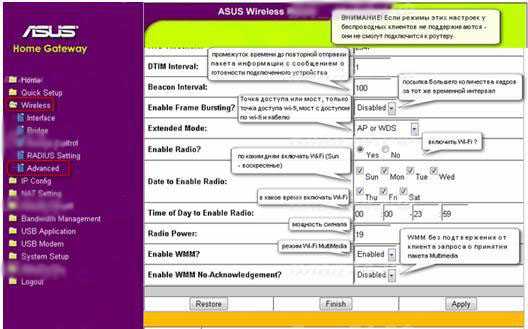
Внимание! изменение настроек в этой секции могут привести к тому, что вы не попадете в web-интерефейс роутера через Wi-Fi, сохраните предварительно настройки роутера в файл!!!
Скрыть SSID – При поиске Wi-Fi сетей – ваш роутер может быть скрыт, подключится можно будет, только если явно указать идентификатор SSID
Включить радиомодуль – Включить беспроводную сеть ?
Дата включения – По каким дням включать беспроводную сеть
Время включения – В какое время следует включать беспроводную сеть
Установить изолированную точку доступа – Если разрешить – клиенты беспроводной сети не будут «видеть» друг друга (в том числе файлы и папки)
Скорость многоадресной передачи – скорость многоадресной передачи в беспроводной сети – оставьте Auto
Установленная базовая скорость – оставьте Default
Порог фрагментации — порог фрагментации, определяющий размер MAC-кадров (из которых состоят пакеты), пере
ASUS RT-AC5300 и ASUS RT-AC88U: сверхскоростные высокопроизводительные маршрутизаторы
Компания ASUS начала продажи в России сверхскоростных высокопроизводительных маршрутизаторов ASUS RT-AC5300 и ASUS RT-AC88U. Главная отличительная особенностей этого оборудования: высокая скорость доступа к сети, высокая производительность, а также полный комплект функций, который ожидает получить опытный пользователей от современных моделей сетевых маршрутизаторов.
Новые модели относятся к линейке трех- и двухдиапазонных маршрутизаторов. Они являются примером «квалифицированного» выбора надежных и функциональных устройств при построении сложных беспроводных сетей для абсолютно любых целей. Это может быть как домашний офис или домашний игровой центр, так и офисный Интернет и интранет.
Новую линейку продуктов представил Алексей Дегтярев, менеджер по сетевому оборудованию компании ASUS.
ASUS RT-AC88U
Двухдиапазонный маршрутизатор ASUS RT-AC88U можно использовать для работы в домашних и офисных сетях. Однако его высокая эффективность будет проявляться в среде, когда к маршрутизатору подключено большое количество устройств, использующих разные стандарты беспроводного соединения. Если обычный маршрутизатор будет попеременно «молотить» данные, получаемые от каждого устройства, то ASUS RT-AC88U предоставляется большой набор функциональных средств для оптимизации передачи.
Одной из особенностей новой модели является наличие восьми портов Gigabit Ethernet. С их помощью можно создавать проводные LAN-подсоединение для компьютеров и других сетевых устройств.
Модель ASUS RT-AC88U оборудована четырьмя внешними антеннами, имеющие высокий коэффициент усиления и задействующие для передачи данных отдельный поток для каждой антенны. Рекомендованная цена маршрутизатора – 25 399 руб.
На первый взгляд, это смотрится как «много». Возникает естественный вопрос: зачем нужен маршрутизатор за 25 тыс. рублей, если на рынке можно спокойно купить устройство для аналогичных целей, которое будет стоить не более 6-8 тыс. руб.
Ответ очевиден: богатый набор дополнительных функций, который требует предварительных вложений, но который с лихвой оправдывается более высокой продуктивностью, скоростью и надежности полученной в итоге системы.
Функция агрегации портов
Смысл этой функции достаточно прост. При отключенной агрегации портов суммарная скорость передачи данных не превышает пропускной способности используемого порта. Например, если к маршрутизатору подсоединены беспроводным путем два компьютера, то работая через один порт, они не смогут использовать преимущества двухканальной архитектуры маршрутизатора ASUS RT-AC88U.
При включенной агрегации портов трафик от каждого подключенного устройства может передаваться сразу по двум каналам.
Приведем в качестве примера следующий вариант: два компьютера подключены к Интернету через маршрутизатор. Пусть загрузка его отдельного порта на прикладной трафик не может превышать 80% от пропускной способности. Тогда при наличии 1 Гбит/с порта максимальная скорость передача данных с каждого компьютера не будет превышать (при равной загрузке) 400 Мбит/с.
Если же включить режим агрегации двух имеющихся у ASUS RT-AC88U портов, то суммарная пропускная способность машрутизатора возрастет (при заданных условиях) до 2 Гбит/с х0,8= 1,6 Гбит/с,т.е. на каждый компьютер будет приходиться в среднем по 800 Мбит/с.
AirTime Fairness
Эта функция касается оптимизации обработки пакетов, передаваемых различными клиентами.
Суть технологии опять несложная, но она встречается только в качественных маршрутизаторах. Простой маршрутизатор, получая данных с разных устройств, обрабатывает их по очереди, пакет за пакетом. Это достаточно близко к эффективному режиму работы только при условии, что пакеты, получаемые из разных источников, имеют одинаковую длину.
Но в жизни все бывает значительно сложней. Главная причина: в условиях дома или небольшого офиса к маршрутизатору подключаются устройства, выполняющие разные целевые задачи. Например, с одного компьютера могут идти запросы на прием потокового видео, а одновременно с мобильного телефона вестись разговор по технологии VoIP. В результате пакеты от этих устройств будут разными по длине, и клиент, стремящийся получить потоковое видео может «задушить» всех остальных клиентов, сидящие на той же точке доступа.
Этот процесс можно регулировать, например, включать QoS для определенных портов и протоколов (или даже для определенных клиентов, таких как VoIP-телефоны). Но в любом случае при использовании простого маршрутизатора трафик для одного устройства может мешать трафику для другого.
Решение дает технология AirTime Fairness. Маршрутизатор ведет статистику отправляемых и получаемых пакетов с учетом, например, адресата, и предугадывая заранее заранее длину пакетов, может изменить последовательность перебора обслуживаемых устройств, объединив, например короткие пакеты в один, соразмерный другим пакетам в трафике, или с учетом более высокого QoS, заданного администратором. Это позволяет в итоге более важные данные пропустить быстрей, и реализовать поддержку, например, разговор по VoIP, тогда как на простом маршрутизаторе он получается совсем низкого качества.
Интерфейс
Об интерфейсе маршрутизаторов ASUS ходят легенды, что это – лучшее, что можно встретить на рынке. Пожалуй, с этой оценкой можно согласиться. Во всяком случае многообразие параметров и удобство их представления на экране без сомнения присутствует.
На общей панели можно наблюдать, например, загрузку процессора и памяти. Это позволяет рационально управлять и нагружать устройство, отыскивать причины снижения быстродействия.
Другой пример, это обслуживание работы функции ASUS AiCloud. Благодаря наличию интерфейса USB 2.0, к маршрутизатору можно подключить внешний накопитель, принтер или модем. Технология ASUS AiCloud в этом случае позволит применить удаленный доступ к файлам, хранящимся в домашней сети и в облачных хранилищах.
ASUS WRT 2.0
Это – новый графический интерфейс, позволяющий быстро установить необходимые средства поддержки для маршрутизатора. Процесс установки занимает не более 30 секунд и состоит из трех простых этапов. В процессе установки осуществляется конфигурация всех поддерживаемых функций.
Анализатор трафика
Традиционная установка простого маршрутизатора выполняется в режиме «установил и забыл». Это хорошо для начинающих пользователей, но если сетевое устройство используется для игр, поддержки телефонии, удобной и эффективной работы в Интернете, обслуживании систем «умного» дома, то сразу возникает вопрос: «Что делать, если вдруг оказывается, что Интернет стал работать плохо».
В этой ситуации начинающие пользователи предпочитают звонить провайдеру Интернета. Однако получив ответ: «С нашей стороны все в порядке», остаются ни с чем.
В этой ситуации требуется понять, что же реально происходит на клиентской стороне. Для этого используется такой инструмент, как «Анализатор трафика».
Имея перед глазами диаграмму текущей загрузки маршрутизатора и развития ее динамики в истории, можно оценить, что же реально произошло с сетью в течение нескольких прошедших дней или целого месяца.
Можно также отыскивать периоды, когда система не могла справиться с возросшей нагрузкой, что позволяет лучше понять, можно ли что-то улучшить или нет.
Адаптивный QoS
Это одна из самых удобных и эффективных, с точки зрения пользвоателя функций маршрутизатора ASUS RT-AC88U. QoS – это параметр, описывающий качество обслуживания того или иного подключенного устройства.
Однако пользователь отстранен от необходимости понимать особенностей настройки. Ему предлагаются простые инструменты, с помощью которых он может выстроить элементы системы под свой вкус и задачи.
Например, ему предлагаются на выбор базовые задачи, обслуживаемые маршрутизатором: просмотр потокового видео и аудио, запуск игровых программ, просмотр Интернета, поддержка VoIP-телефонии и сервиса обмена сообщений, передача файлов (этот список можно дополнить). Теперь остается только выстроить эти функции в порядке убывания приоритета в их обслуживании, и после этого маршрутизатор будет автоматически придерживаться выбранного порядка, подбирая такое выстраивание потока пакетов, чтобы никогда не наносить ущерба задачам, поставленным в более приоритетную позицию.
Используя аналогичный принцип, можно выстроить подключаемые устройства, обеспечив, например, приоритет в обслуживании трафика, получаемого от ноутбука, по сравнению со смартфоном.
Если более привычно работать с программами, то приоритетный список можно выстроить и наих уровне.
Главное, что в распоряжении пользователя есть разнообразные средства для визуализации реального трафика от того или иного источника или типа. Это позволяет выбирать не вслепую, а как настоящий «системный администратор в большой компании».
Другие функции
Как можно видеть, ASUS снабдила свое сетевое устройство самыми разнообразными диагностическими и управляющими инструментами. Только упомянем еще следующие функции, которые пока не вошли в этот обзор:
- AiProtection – шлюз безопасности. Он построен на базе защитного механизма, разработанного компанией Trend Micro. Это - эксклюзивная функция, которая встречается только на маршрутизаторах ASUS. Она позволяет блокировать вредоносные сайты, вредоносное ПО, другие угрозы по безопасности. Она также предупреждает пользователя, если к его внутренней сети пробует подключиться инфицированное устройство, обеспечивая тем самым надежную защиту персональных данных.
- Dual WAN – эта функция стала уже стандартной для маршрутизаторов ASUS среднего и высокого сегмента. Она обеспечивает баланс загрузки между несколькими портами. Так, один из портов можно использоваться для подключения к WAN (Интернету) или LAN, другой может быть отдельной выделенной локальной сетью, например, для выполнения задач резервного копирования и синхронизации.
- Roaming assist: эта функция обеспечивает автоматическое переключение на самый мощный сигнал. Она удобна, если маршрутизатор применяется при перемещении пользователя. Ситуация встречается не часто, но если это происходит, то альтернативы маршрутизатору ASUS практически нет.
ASUS RT-AC5300
Маршрутизатор ASUS RT-AC5300 (цена 32,290 руб.) является топовой моделью в линейке ASUS. Он во-многом похож на модель среднего класса (маршрутизатор ASUS RT-AC88U). Но у него есть и свои отличия. Главным образом – это дополнение к тому, что можно увидеть на средней модели.
Если в общем, ASUS RT-AC5300 – это трехдиапазонный маршрутизатор и Интернет-шлюз, который может работать в двух частотных диапазонах: 2,4 и 5 ГГц, также как и все остальные модели. ASUS уверенно относит данную модель к системам 5G, которые должны заменить существующие маршрутизаторы. Так ли получится в итоге или нет, пока не известно. Но уже сегодня почувствовать, что такое реальный 5G - это, наверное, понравится многим.
Благодаря наличию восьми внешних антенн и фирменной технологии ASUS AiRadar, маршрутизатор ASUS RT-AC5300 поддерживает надежную работу беспроводной сети в условиях сложной планировки помещений. Это может быть многокомнатная квартира большой площади или небольшой склад с рядами стоек.
Применение технологий Broadcom NitroQAM и ASUS Tri-band Smart Connect позволило объединить все передающие каналы, добившись в итоге суммарной пропускной способности в 5,3 Гбит/с. На сегодняшний день это является рекордным показателем.
Впрочем, надо учитывать, что технологии 5G еще не получили официальной сертификации в России. Поэтому применение таких маршрутизаторов разрешено пока только в условиях закрытых помещений, не на улице.
blogs.pcmag.ru
NIC teaming in ESXi. Агрегирование каналов
NIC teaming in ESXi. Агрегирование каналов. ТеорияАгрегирование каналов - Wikipedia
Обзор объединения сетевых карт - technet
NIC Teaming - является процессом объединения нескольких сетевых карт вместе для повышения производительности и избыточности. Microsoft называет это NIC Teaming , однако другие производители могут называть это соединение, балансирование или агрегации. Процесс тот же, независимо от того, какое решение будет использоваться или как называется.
Link Aggregation Control Protocol (LACP) — протокол, предназначенный для объединения нескольких физических каналов в один логический в сетях Ethernet. Агрегированные каналы LACP используются как для повышения пропускной способности, так и повышения отказоустойчивости. Использование LACP в некоторых случаях позволяет обнаружить повреждённый канал, который бы при использовании обычной статической агрегации обнаружен бы не был. Описывается стандартом IEEE 802.3ad.
В Linux поддержка LACP осуществляется с помощью модуля bonding, как и всякая другая агрегация на канальном уровне. Режим агрегации: 4.
Link Aggregation Control Protocol (LACP) (802.3ad) for Gigabit Interfaceshttp://www.cisco.com/c/en/us/td/docs/ios/12_2sb/feature/guide/gigeth.htmlConfiguring LACP (802.3ad) for Gigabit Interfaces http://www.cisco.com/c/en/us/td/docs/ios/12_2sb/feature/guide/gigeth.html#wp1089298
SUMMARY STEPS from Cisco
- enable
- configure terminal
- interface port-channel number
- ip address ip_address mask
- interface type slot/subslot/port
- no ip address
- channel-group number mode {active | passive}
- exit
- interface type slot/subslot/port
- no ip address
- channel-group number mode {active | passive}
- end
VMware ESXi
VMware Knowledge Base (KB). NIC teaming in ESXi and ESX (1004088) http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1004088
Цель Эта статья содержит информацию о настройке объединения сетевых адаптеров.
Объединение сетевых карт может распределить нагрузку трафика между физическими и виртуальными сетями среди некоторых или всех его членов, а также обеспечить пассивный переход на другой ресурс в случае отказа оборудования или сбоя в работе сети.
Решение
Чтобы использовать NIC Teaming, два или более сетевых адаптеров должны быть подключены к виртуальному коммутатору. Основными преимуществами NIC Teaming являются: • Увеличение пропускной способности сети для виртуального коммутатора хоста группы. • Пассивная отказоустойчивость в случае отказа одного из адаптеров в группе.
bga68.livejournal.com
Надежный (неэкстремальный) разгон процессора и памяти для материнских плат ASUS с процессором i7
Рассматриваются UEFI настройки для ASUS Z77 материнских плат на примере платы ASUS PZ77-V LE с процессором Ivy Bridge i7. Оптимальные параметры выбирались для некоторых сложных UEFI-настроек, которые позволяют получить успешный разгон без излишнего риска. Пользователь последовательно знакомится с основными понятиями разгона и осуществляет надежный и не экстремальный разгон процессора и памяти материнских плат ASUS Z77. Для простоты используется английский язык UEFI.Пост прохладно принят на сайте оверклокеров. Это понятно, так как на этом сайте в основном бесшабашные безбашенные пользователи, занимающиеся экстремальным разгоном.
AI Overclock Tuner
Все действия, связанные с разгоном, осуществляются в меню AI Tweaker (UEFI Advanced Mode) установкой параметра AI Overclock Tuner в Manual (рис. 1).
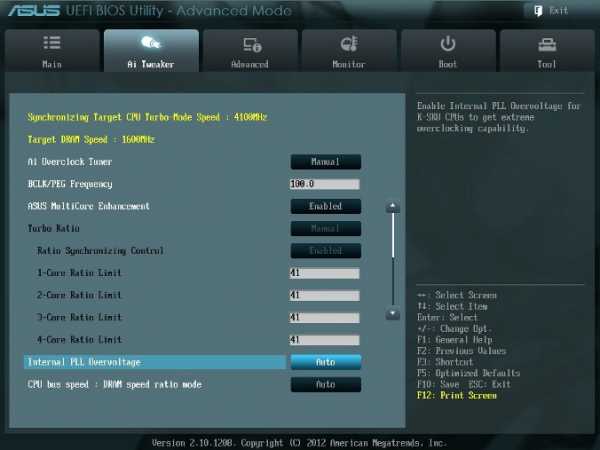 Рис. 1
Рис. 1
BCLK/PEG Frequency
Параметр BCLK/PEG Frequency (далее BCLK) на рис. 1 становится доступным, если выбраны Ai Overclock TunerXMP или Ai Overclock TunerManual. Частота BCLK, равная 100 МГц, является базовой. Главный параметр разгона – частота ядра процессора, получается путем умножения этой частоты на параметр – множитель процессора. Конечная частота отображается в верхней левой части окна Ai Tweaker (на рис. 1 она равна 4,1 ГГц). Частота BCLK также регулирует частоту работы памяти, скорость шин и т.п.Возможное увеличение этого параметра при разгоне невелико – большинство процессоров позволяют увеличивать эту частоту только до 105 МГц. Хотя есть отдельные образцы процессоров и материнских плат, для которых эта величина равна 107 МГц и более. При осторожном разгоне, с учетом того, что в будущем в компьютер будут устанавливаться дополнительные устройства, этот параметр рекомендуется оставить равным 100 МГц (рис. 1).
ASUS MultiCore Enhancement
Когда этот параметр включен (Enabled на рис. 1), то принимается политика ASUS для Turbo-режима. Если параметр выключен, то будет применяться политика Intel для Turbo-режима. Для всех конфигураций при разгоне рекомендуется включить этот параметр (Enabled). Выключение параметра может быть использовано, если вы хотите запустить процессор с использованием политики корпорации Intel, без разгона.
Turbo Ratio
В окне рис. 1 устанавливаем для этого параметра режим Manual. Переходя к меню Advanced...CPU Power Management Configuration (рис. 2) устанавливаем множитель 41.
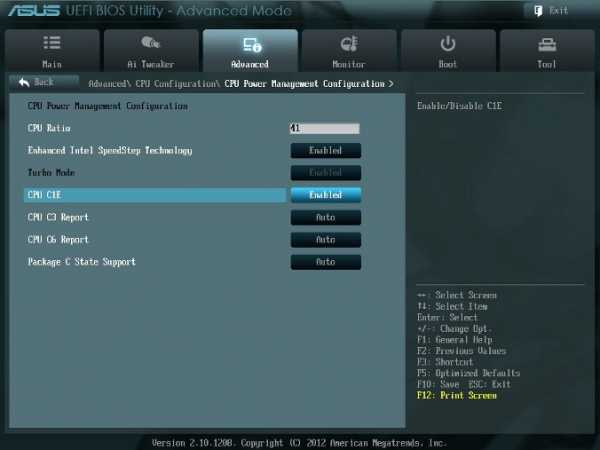 Рис. 2Возвращаемся к меню AI Tweaker и проверяем значение множителя (рис. 1).Для очень осторожных пользователей можно порекомендовать начальное значение множителя, равное 40 или даже 39. Максимальное значение множителя для неэкстремального разгона обычно меньше 45.
Рис. 2Возвращаемся к меню AI Tweaker и проверяем значение множителя (рис. 1).Для очень осторожных пользователей можно порекомендовать начальное значение множителя, равное 40 или даже 39. Максимальное значение множителя для неэкстремального разгона обычно меньше 45.
Internal PLL Overvoltage
Увеличение (разгон) рабочего напряжения для внутренней фазовой автоматической подстройки частоты (ФАПЧ) позволяет повысить рабочую частоту ядра процессора. Выбор Auto будет автоматически включать этот параметр только при увеличении множителя ядра процессора сверх определенного порога.Для хороших образцов процессоров этот параметр нужно оставить на Auto (рис. 1) при разгоне до множителя 45 (до частоты работы процессора 4,5 ГГц).Отметим, что стабильность выхода из режима сна может быть затронута, при установке этого параметра в состояние включено (Enabled). Если обнаруживается, что ваш процессор не будет разгоняться до 4,5 ГГц без установки этого параметра в состояние Enabled, но при этом система не в состоянии выходить из режима сна, то единственный выбор – работа на более низкой частоте с множителем меньше 45. При экстремальном разгоне с множителями, равными или превышающими 45, рекомендуется установить Enabled. При осторожном разгоне выбираем Auto. (рис. 1).
CPU bus speed: DRAM speed ratio mode
Этот параметр можно оставить в состоянии Auto (рис. 1), чтобы применять в дальнейшем изменения при разгоне и настройке частоты памяти.
Memory Frequency
Этот параметр виден на рис. 3. С его помощью осуществляется выбор частоты работы памяти.
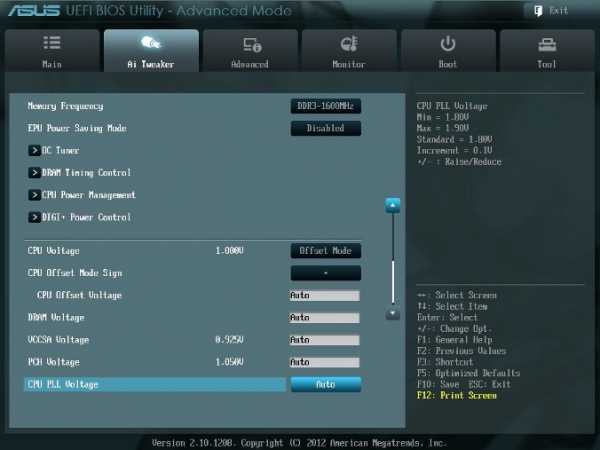 Рис. 3Параметр Memory Frequency определяется частотой BCLK и параметром CPU bus speed:DRAM speed ratio mode. Частота памяти отображается и выбирается в выпадающем списке. Установленное значение можно проконтролировать в левом верхнем углу меню Ai Tweaker. Например, на рис. 1 видим, что частота работы памяти равна 1600 МГц.Отметим, что процессоры Ivy Bridge имеют более широкий диапазон настроек частот памяти, чем предыдущее поколение процессоров Sandy Bridge. При разгоне памяти совместно с увеличением частоты BCLK можно осуществить более детальный контроль частоты шины памяти и получить максимально возможные (но возможно ненадежные) результаты при экстремальном разгоне.Для надежного использования разгона рекомендуется поднимать частоту наборов памяти не более чем на 1 шаг относительно паспортной. Более высокая скорость работы памяти дает незначительный прирост производительности в большинстве программ. Кроме того, устойчивость системы при более высоких рабочих частотах памяти часто не может быть гарантирована для отдельных программ с интенсивным использованием процессора, а также при переходе в режим сна и обратно. Рекомендуется также сделать выбор в пользу комплектов памяти, которые находятся в списке рекомендованных для выбранного процессора, если вы не хотите тратить время на настройку стабильной работы системы.Рабочие частоты между 2400 МГц и 2600 МГц, по-видимому, являются оптимальными в сочетании с интенсивным охлаждением, как процессоров, так и модулей памяти. Более высокие скорости возможны также за счет уменьшения вторичных параметров – таймингов памяти.При осторожном разгоне начинаем с разгона только процессора. Поэтому вначале рекомендуется установить паспортное значение частоты работы памяти, например, для комплекта планок памяти DDR3-1600 МГц устанавливаем 1600 МГц (рис. 3).После разгона процессора можно попытаться поднять частоту памяти на 1 шаг. Если в стресс-тестах появятся ошибки, то можно увеличить тайминги, напряжение питания (например на 0,05 В), VCCSA на 0,05 В, но лучше вернуться к номинальной частоте.
Рис. 3Параметр Memory Frequency определяется частотой BCLK и параметром CPU bus speed:DRAM speed ratio mode. Частота памяти отображается и выбирается в выпадающем списке. Установленное значение можно проконтролировать в левом верхнем углу меню Ai Tweaker. Например, на рис. 1 видим, что частота работы памяти равна 1600 МГц.Отметим, что процессоры Ivy Bridge имеют более широкий диапазон настроек частот памяти, чем предыдущее поколение процессоров Sandy Bridge. При разгоне памяти совместно с увеличением частоты BCLK можно осуществить более детальный контроль частоты шины памяти и получить максимально возможные (но возможно ненадежные) результаты при экстремальном разгоне.Для надежного использования разгона рекомендуется поднимать частоту наборов памяти не более чем на 1 шаг относительно паспортной. Более высокая скорость работы памяти дает незначительный прирост производительности в большинстве программ. Кроме того, устойчивость системы при более высоких рабочих частотах памяти часто не может быть гарантирована для отдельных программ с интенсивным использованием процессора, а также при переходе в режим сна и обратно. Рекомендуется также сделать выбор в пользу комплектов памяти, которые находятся в списке рекомендованных для выбранного процессора, если вы не хотите тратить время на настройку стабильной работы системы.Рабочие частоты между 2400 МГц и 2600 МГц, по-видимому, являются оптимальными в сочетании с интенсивным охлаждением, как процессоров, так и модулей памяти. Более высокие скорости возможны также за счет уменьшения вторичных параметров – таймингов памяти.При осторожном разгоне начинаем с разгона только процессора. Поэтому вначале рекомендуется установить паспортное значение частоты работы памяти, например, для комплекта планок памяти DDR3-1600 МГц устанавливаем 1600 МГц (рис. 3).После разгона процессора можно попытаться поднять частоту памяти на 1 шаг. Если в стресс-тестах появятся ошибки, то можно увеличить тайминги, напряжение питания (например на 0,05 В), VCCSA на 0,05 В, но лучше вернуться к номинальной частоте.
EPU Power Saving Mode
Автоматическая система EPU разработана фирмой ASUS. Она регулирует частоту и напряжение элементов компьютера в целях экономии электроэнергии. Эта установка может быть включена только на паспортной рабочей частоте процессора. Для разгона этот параметр выключаем (Disabled) (рис. 3).
OC Tuner
Когда выбрано (OK), будет работать серия стресс-тестов во время Boot-процесса с целью автоматического разгона системы. Окончательный разгон будет меняться в зависимости от температуры системы и используемого комплекта памяти. Включать не рекомендуется, даже если вы не хотите вручную разогнать систему. Не трогаем этот пункт или выбираем cancel (рис. 3).
DRAM Timing Control
DRAM Timing Control – это установка таймингов памяти (рис. 4).
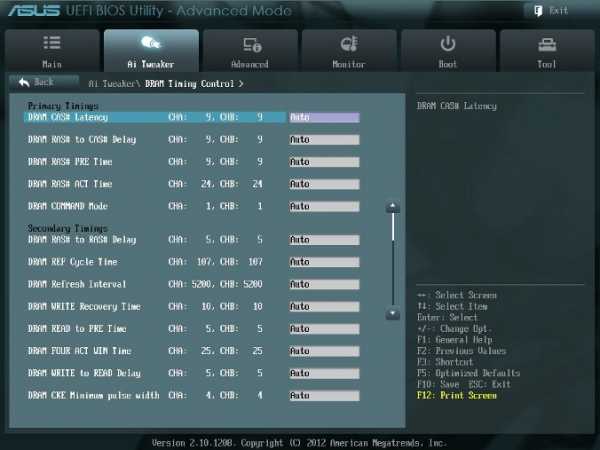 Рис. 4.Все эти настройки нужно оставить равными паспортным значениям и на Auto, если вы хотите настроить систему для надежной работы. Основные тайминги должны быть установлены в соответствии с SPD модулей памяти.
Рис. 4.Все эти настройки нужно оставить равными паспортным значениям и на Auto, если вы хотите настроить систему для надежной работы. Основные тайминги должны быть установлены в соответствии с SPD модулей памяти.
 Рис. 5Большинство параметров на рис. 5 также оставляем в Auto.
Рис. 5Большинство параметров на рис. 5 также оставляем в Auto.
MRC Fast Boot
Включите этот параметр (Enabled). При этом пропускается тестирование памяти во время процедуры перезагрузки системы. Время загрузки при этом уменьшается. Отметим, что при использовании большего количества планок памяти и при высокой частоте модулей (2133 МГц и выше) отключение этой настройки может увеличить стабильность системы во время проведения разгона. Как только получим желаемую стабильность при разгоне, включаем этот параметр (рис. 5).
DRAM CLK Period
Определяет задержку контроллера памяти в сочетании с приложенной частоты памяти. Установка 5 дает лучшую общую производительность, хотя стабильность может ухудшиться. Установите лучше Auto (рис. 5).
CPU Power Management
Окно этого пункта меню приведено на рис. 6. Здесь проверяем множитель процессора (41 на рис. 6), обязательно включаем (Enabled) параметр энергосбережения EIST, а также устанавливаем при необходимости пороговые мощности процессоров (все последние упомянутые параметры установлены в Auto (рис. 6)).Перейдя к пункту меню Advanced...CPU Power Management Configuration (рис. 2) устанавливаем параметр CPU C1E (энергосбережение) в Enabled, а остальные (включая параметры с C3, C6) в Auto.
 Рис. 6
Рис. 6
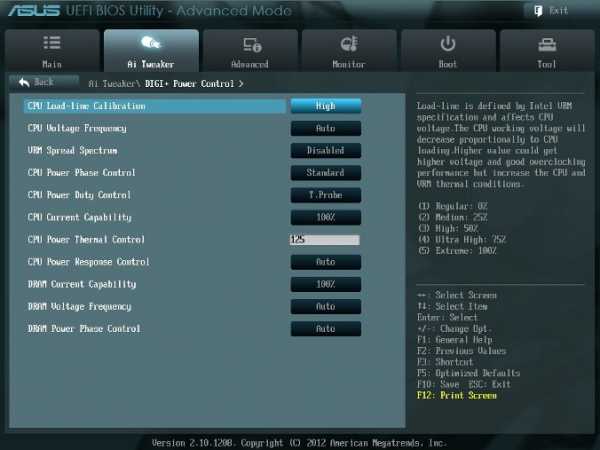 Рис. 7.
Рис. 7.
DIGI+ Power Control
На рис. 7 показаны рекомендуемые значения параметров. Некоторые параметры рассмотрим отдельно.
CPU Load-Line Calibration
Сокращённое наименование этого параметра – LLC. При быстром переходе процессора в интенсивный режим работы с увеличенной мощностью потребления напряжение на нем скачкообразно уменьшается относительно стационарного состояния. Увеличенные значения LLC обуславливают увеличение напряжения питания процессора и уменьшают просадки напряжения питания процессора при скачкообразном росте потребляемой мощности. Установка параметра равным high (50%) считается оптимальным для режима 24/7, обеспечивая оптимальный баланс между ростом напряжения и просадкой напряжения питания. Некоторые пользователи предпочитают использовать более высокие значения LLC, хотя это будет воздействовать на просадку в меньшей степени. Устанавливаем high (рис. 7).
VRM Spread Spectrum
При включении этого параметра (рис. 7) включается расширенная модуляция сигналов VRM, чтобы уменьшить пик в спектре излучаемого шума и наводки в близлежащих цепях. Включение этого параметра следует использовать только на паспортных частотах, так как модуляция сигналов может ухудшить переходную характеристику блока питания и вызвать нестабильность напряжения питания. Устанавливаем Disabled (рис. 7).
Current Capability
Значение 100% на все эти параметры должны быть достаточно для разгона процессоров с использованием обычных методов охлаждения (рис. 7).
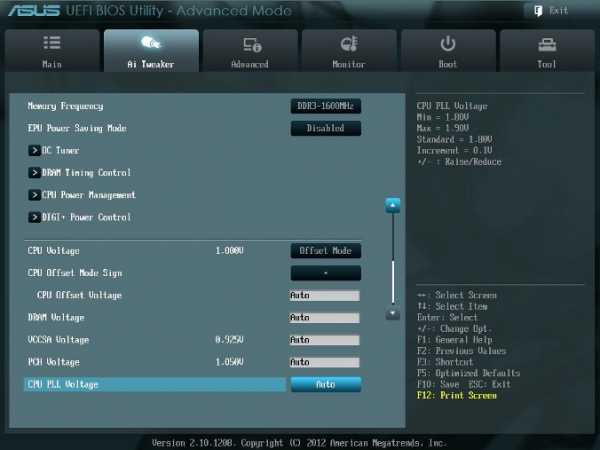 Рис. 8.
Рис. 8.
CPU Voltage
Есть два способа контролировать напряжения ядра процессора: Offset Mode (рис. 8) и Manual. Ручной режим обеспечивает всегда неизменяемый статический уровень напряжения на процессоре. Такой режим можно использовать кратковременно, при тестировании процессора. Режим Offset Mode позволяет процессору регулировать напряжение в зависимости от нагрузки и рабочей частоты. Режим Offset Mode предпочтителен для 24/7 систем, так как позволяет процессору снизить напряжение питания во время простоя компьютера, снижая потребляемую энергию и нагрев ядер.Уровень напряжения питания будет увеличиваться при увеличении коэффициента умножения (множителя) для процессора. Поэтому лучше всего начать с низкого коэффициента умножения, равного 41х (или 39х) и подъема его на один шаг с проверкой на устойчивость при каждом подъеме. Установите Offset Mode Sign в “+”, а CPU Offset Voltage в Auto. Загрузите процессор вычислениями с помощью программы LinX и проверьте с помощью CPU-Z напряжение процессора. Если уровень напряжения очень высок, то вы можете уменьшить напряжение путем применения отрицательного смещения в UEFI. Например, если наше полное напряжение питания при множителе 41х оказалась равным 1,35 В, то мы могли бы снизить его до 1,30 В, применяя отрицательное смещение с величиной 0,05 В.Имейте в виду, что уменьшение примерно на 0,05 В будет использоваться также для напряжения холостого хода (с малой нагрузкой). Например, если с настройками по умолчанию напряжение холостого хода процессора (при множителе, равном 16x) является 1,05 В, то вычитая 0,05 В получим примерно 1,0 В напряжения холостого хода. Поэтому, если уменьшать напряжение, используя слишком большие значения CPU Offset Voltage, наступит момент, когда напряжение холостого хода будет таким малым, что приведет к сбоям в работе компьютера.Если для надежности нужно добавить напряжение при полной нагрузке процессора, то используем “+” смещение и увеличение уровня напряжения. Отметим, что введенные как “+” так и “-” смещения не точно отрабатываются системой питания процессора. Шкалы соответствия нелинейные. Это одна из особенностей VID, заключающаяся в том, что она позволяет процессору просить разное напряжение в зависимости от рабочей частоты, тока и температуры. Например, при положительном CPU Offset Voltage 0,05 напряжение 1,35 В при нагрузке может увеличиваться только до 1,375 В.Из изложенного следует, что для неэкстремального разгона для множителей, примерно равных 41, лучше всего установить Offset Mode Sign в “+” и оставить параметр CPU Offset Voltage в Auto. Для процессоров Ivy Bridge, ожидается, что большинство образцов смогут работать на частотах 4,1 ГГц с воздушным охлаждением. Больший разгон возможен, хотя при полной загрузке процессора это приведет к повышению температуры процессора. Для контроля температуры запустите программу RealTemp.
DRAM Voltage
Устанавливаем напряжение на модулях памяти в соответствии с паспортными данными. Обычно это примерно 1,5 В. По умолчанию – Auto (рис. 8).
VCCSA Voltage
Параметр устанавливает напряжение для System Agent. Можно оставить на Auto для нашего разгона (рис. 8).
CPU PLL Voltage
Для нашего разгона – Auto (рис. 8). Обычные значения параметра находятся около 1,8 В. При увеличении этого напряжения можно увеличивать множитель процессора и увеличивать частоту работы памяти выше 2200 МГц, т.к. небольшое превышение напряжения относительно номинального может помочь стабильности системы.
PCH Voltage
Можно оставить значения по умолчанию (Auto) для небольшого разгона (рис. 8). На сегодняшний день не выявилось существенной связи между этим напряжением на чипе и другими напряжениями материнской платы.
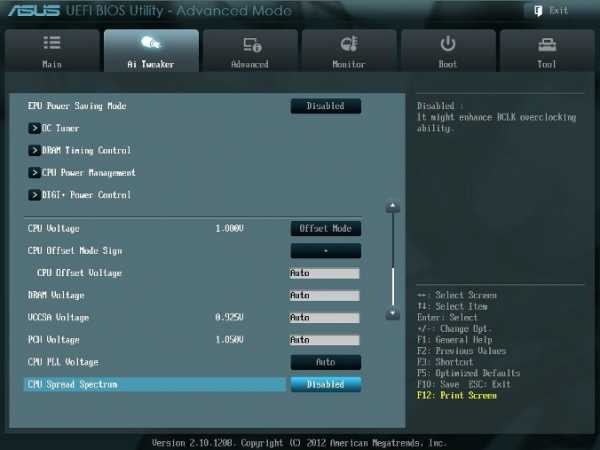 Рис. 9
Рис. 9
CPU Spread Spectrum
При включении опции (Enabled) осуществляется модуляция частоты ядра процессора, чтобы уменьшить величину пика в спектре излучаемого шума. Рекомендуется установить параметр в Disabled (рис. 9), т.к. при разгоне модуляция частоты может ухудшить стабильность системы.
Автору таким образом удалось установить множитель 41, что позволило ускорить моделирование с помощью MatLab.
Автор: nata16k8
Источник
www.pvsm.ru
Тюнинг и оптимизация NFS
В предыдущей статье шла речь о установке, настройке и монтировании NFS шары с параметрами по умолчанию. Сейчас можно немного улучшить производительность как со стороны сервера, так и клиентской части. Но хочу заметить, что в зависимости от конфигурации и оборудования те же параметры могут и ухудшить производительность NFS.
Конфигурация сервера:
- CPU: 16 cores (32 threads)
- RAM: 64GB
- Network: 4 x 1 Gbit
Улучшать будем в три этапа:
- Общее для клиента и сервера
- Серверная часть
- Клиентская часть
1 Общее для клиента и сервера
1.1 Параметры ядра
Первым делом подправим настройки ядра для улучшения производительности как с клиентской, так и с серверной стороны. Есть такая штука как буфер сокета. Такой буфер есть на входящие и исходящие запроси. Так как RPC запросов на запись и считывание может быть много, и если CPU или диск не успевает все обработать, то мы храним все запросы в маленькой очереди сокета, чтобы не потерялись. Из документации по ядру:
- rmem_default (The default setting of the socket receive buffer in bytes)
- rmem_max (The maximum receive socket buffer size in bytes)
- wmem_default (The default setting (in bytes) of the socket send buffer)
- wmem_max (The maximum send socket buffer size in bytes)
Размер буфера будем выставлять в соотношении 1 MiB на каждый 1 GB оперативной памяти. Нужные параметры выставляются следующим образом.
root@nfs:~# sysctl -w net.core.rmem_default=67108864 или root@nfs:~# echo 67108864 > /proc/sys/net/core/rmem_default root@nfs:~# sysctl -w net.core.rmem_max=67108864 или root@nfs:~# echo 67108864 > /proc/sys/net/core/rmem_max root@nfs:~# sysctl -w net.core.wmem_default=67108864 или root@nfs:~# echo 67108864 > /proc/sys/net/core/wmem_default root@nfs:~# sysctl -w net.core.wmem_max=67108864 или root@nfs:~# echo 67108864 > /proc/sys/net/core/wmem_maxТаким образом размер буфера сокетов обновиться в реальном времени (на лету). Чтобы параметры сохранились после ребута, нужно добавить их в автозагрузку.
root@nfs:~# cat /etc/sysctl.conf … net.core.wmem_max = 67108864 net.core.rmem_max = 67108864 net.core.wmem_default = 67108864 net.core.rmem_default = 67108864 …Также нужно увеличить общую очередь всех входящих пакетов, UDP и TCP буфер для всех сокетов. Из документации ядра:
Vector of 3 INTEGERs: min, pressure, max (in pages). Number of pages allowed for queueing by all UDP sockets.min: Below this number of pages UDP is not bothered about its memory appetite. When amount of memory allocated by UDP exceeds this number, UDP starts to moderate memory usage.pressure: This value was introduced to follow format of tcp_mem.max: Number of pages allowed for queueing by all UDP sockets.Defaults are calculated at boot time from amount of available memory.
Vector of 3 INTEGERs: min, pressure, max (in pages).min: below this number of pages TCP is not bothered about its memory appetite.pressure: when amount of memory allocated by TCP exceeds this number of pages, TCP moderates its memory consumption and enters memory pressure mode, which is exited when memory consumption falls under «min».max: number of pages allowed for queueing by all TCP sockets.Defaults are calculated at boot time from amount of available memory.
Maximum number of packets, queued on the INPUT side, when the interface receives packets faster than kernel can process them.
tcp_mem и udp_mem измеряется в страницах памяти. Размер одной страницы – 4096 байт. По умолчанию, он большой, но можно увеличить на 10-20%, а netdev_max_backlog можно увеличить в 3 раза.
root@nfs:~# sysctl -w net.ipv4.udp_mem="1549836 2066449 3099672" или root@nfs:~# echo “1549836 2066449 3099672” > /proc/sys/net/ipv4/udp_mem root@nfs:~# sysctl -w net.ipv4.tcp_mem="1549836 2066449 3099672" или root@nfs:~# echo “1549836 2066449 3099672” > /proc/sys/net/ipv4/tcp_mem root@nfs:~# sysctl -w net.core.netdev_max_backlog=3000 или root@nfs:~# echo 3000 > /proc/sys/net/core/netdev_max_backlogТ.е. min = 1549836 pages = 1549836 x 4096 byte = 6348128256 byte = ~5.9 GB.После, нужно добавить все в автозагрузку. После чего, мы должны получить следующею картину.
root@nfs:~# cat /etc/sysctl.conf … net.core.wmem_max = 67108864 net.core.rmem_max = 67108864 net.core.wmem_default = 67108864 net.core.rmem_default = 67108864 net.ipv4.udp_mem = "1549836 2066449 3099672" net.ipv4.tcp_mem = "1549836 2066449 3099672" net.core.netdev_max_backlog = 3000 …1.2 Сетевой стек
1.2.1 Ring buffer (Driver queue)
Рассмотрим схему сетевого стека, которую мы будем улучшать (рис. 1), чтобы понять, как вообще происходить передача данных через сетевую карту. Между IP стеком (IP stack) и контроллером сетевой карты располагается “очередь драйвера” (Driver queue). Что также называют FIFO ring buffer. В этой очереди хранятся указатели на упомянутые выше буферы сокетов ядра (SKB), которые в свою очередь уже хранят сами пакетные данные. В IP стеке в свою очередь храниться очередь IP пакетов. Аппаратный драйвер опустошает очередь IP стека и по шине данных отправляет информацию через NIC дальше. Driver queue – это простая first-in, first-out очередь где все запросы идут и обрабатываются последовательно (в принципе, что и должна делать сетевая карта быстро и просто). Но между IP стеком и этой очередью есть еще специальный слой для управления трафиком (Queueing discipline – Qdisc), а именно:
- классификация
- приоритетность
- рейт
Здесь как раз выставляются биты TOS. Тюнить его мы не будем, но это тоже возможно.
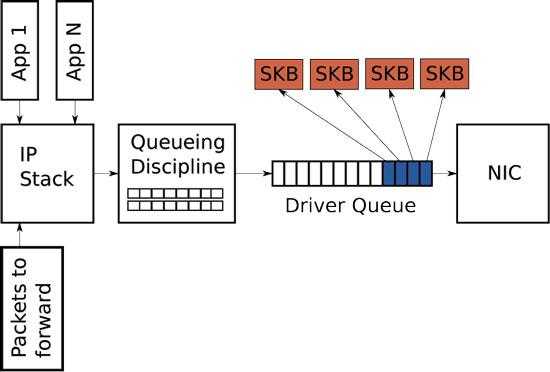
Рисунок 1 — Схема сетевого стека
В нашем случаи будет тюниться очередь драйвера. Его максимальный и поточный размер можно узнать следующим образом.
root@nfs:~# ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 256 RX Mini: 0 RX Jumbo: 0 TX: 256Это означает, что драйвер этой сетевой карты может держать в очереди не больше 4096 SKB-дескрипторов. Этот параметр нужно улучшать, если NIC драйвер не поддерживает BQL(Byte Queue Limits). BQL появился начиная с ядра 3.3 для автоматического вычисления размера очереди драйвера. BQL тюнить не надо, его максимальный лимит можно узнать следующим образом.
root@nfs:~# find /sys/ -name 'byte_queue_limits' root@nfs:~# cat cat /sys/devices/pci0000:00/0000:00:1c.0/0000:06:00.0/net/eth0/queues/tx-0/byte_queue_limits/limit_max 1879048192Как видно, это 1.8GB (этот параметр измеряется уже в байтах).Для случаев, когда нет поддержки BQL, очередь драйвера улучшается следующим способом.
root@nfs:~# ethtool -G eth0 tx 4096 root@nfs:~# ethtool -G eth2 tx 4096 root@nfs:~# ethtool -G eth3 tx 4096 root@nfs:~# ethtool -G eth5 tx 4096 root@nfs:~# ethtool -G eth0 rx 4096 root@nfs:~# ethtool -G eth2 rx 4096 root@nfs:~# ethtool -G eth3 rx 4096 root@nfs:~# ethtool -G eth5 rx 4096Тут было улучшено очередь для всех сетевых интерфейсов по входящему и исходящему трафику.
1.2.2 MTU
Как мы знаем, у сетевых карт есть максимальный размер передаваемого блока данных (MTU). По умолчанию он становит 1500 байт. Если на уровни приложений какой-то апликейшн отправляет пакет размером 5КB в буфер сокета, то ІР стеку этот пакет нужно будет разбить на 4 IP пакета и передать на сетевую карту через очередь драйвера (т.е. 1500 х 4 = 6КВ и 1КВ лишних данных). Чтобы избежать данного overhead-a в линуксе имплементировано:
- TCP segmentation offload (TSO)
- UDP fragmentation offload (UFO)
- Generic segmentation offload (GSO)
Посмотреть значение этих параметров можно так:
root@nfs:~# ethtool -k eth0 | grep -E 'tcp-segmentation-offload|udp-fragmentation-offload|generic-segmentation-offload' tcp-segmentation-offload: on udp-fragmentation-offload: off [fixed] generic-segmentation-offload: onВсе это позволяет ІР стеку создавать пакеты размер которых превышает MTU (IPv4 maximum = 65536 байт) и добавить их в очередь драйвера, где уже самой NIC карте предоставляется роль разбиения пакетов на нужный размер. И в этом случаи мы можем ей помочь, увеличив размер MTU используя Jumbo Frames до 9КВ.
root@nfs:~# ifconfig eth0 mtu 9000 root@nfs:~# ifconfig eth2 mtu 9000 root@nfs:~# ifconfig eth3 mtu 9000 root@nfs:~# ifconfig eth4 mtu 9000Данные команды увеличат размер MTU до 9000. Теперь проверяем новый размер MTU и также добавляем изменения в настройку интерфейсов.
root@nfs:~# netstat -i | awk '{print $1,$2}' Kernel Interface Iface MTU eth0 9000 eth2 9000 eth3 9000 eth5 9000 root@nfs:~# vim /etc/network/interfaces ... iface xxx inet static ... mtu 9000 ... ...Но хочу заметить, что если сервер соединен с клиентом через сетевой свитч/роутер, то Jambo frames должен также быть включен на сетевом оборудовании, иначе возникнут проблемы с сетью.
2 Серверная часть
Чисто серверная часть заключается в улучшении NFSd плис предыдущие все настройки ядра и сети. Исходя из Solaris NFS Server Performance and Tuning Guide for Sun Hardware количество nfsd демонов (потоков) должно быть равным:
- 2 на каждый активный клиентский процесс
- 16-32 на каждый серверный CPU
- 16 на 10 Мбит-ную или 160 на 100 Мбит-ную сеть
Добавить nfsd демонов можно следующими способами (20 nfsd/CPU).
root@sto:~# rpc.nfsd 640 root@sto:~# echo 640 > /proc/fs/nfsd/threads root@sto:~# vim /etc/default/nfs-kernel-server … RPCNFSDCOUNT=640 …Первые две команды добавят nfsd процессов на лету (в реальном времени) без перезагрузки nfsd демона. Последняя команда добавить конфигурацию для автостарта nfsd, чтобы применить эту настройку, нужно перезагрузить nfsd демон.
3 Клиентская часть
На клиентской стороне можно проводить манипуляцию с опциями монтирования плюс все настройки ядра и сети из пункта 1 этой статьи.В предыдущей статье мы уже проводили монтирование NFS шары с описанием опций. В данном случаи мы добавим только те опции, которые помогут улучшить производительность.
root@client:~# mount -o rw,soft,nfsvers=3,intr,bg,timeo=100,retrans=8,rsize=1048576,wsize=1048576 sto:/data01 /mnt/stoВсе эти флаги описаны в предыдущей статье. Если коротко, здесь мы монтируем NFS v3 шару в режиме soft с интервалом таймаута запросов в 10 секунд с 8-ю попытками подключения до сервера. Максимальный размер для NFS запросов на считывания и записи становит 1048576 (1MiB).Если используется Jambo Frames, то rsize и wsize можно поставить 9000 байт, и тогда каждый клиентский NFS запрос будет передаваться по сети без фрагментации.Хочу заметить, что даже если вы указали в опциях монтирования самый большой размер для запросов, то при монтировании, ядро само обрежет до максимального, который оно может поддерживать.
root@client:~# cat /proc/mounts | grep sto sto:/data01 /mnt/sto nfs rw,relatime,vers=3,rsize=65536,wsize=65536,namlen=255,soft,proto=tcp,timeo=100,retrans=8,sec=sys,mountaddr=sto,mountvers=3,mountport=47879,mountproto=udp,local_lock=none,addr=x.x.x.x 0 0 или root@client:~# nfsstat -mМанипуляции с timeo и retrains (увеличивать значения) нужно проводить если вы получаете ошибки вида:
kernel: nfs: server < system name > not responding, timed outИли видите, что retrans счетчик начал стремительно расти:
root@client:~# nfsstat -rc Client rpc stats: calls retrans authrefrsh 281447039 12930 281455555На этом все. В следующей статье пойдет речь о мониторинги и логировании в NFS.
sysadm.pp.ua
Настройка Network Bonding с LACP между CentOS Linux 7.2 и коммутатором Cisco 3560G
На серверах имеющих несколько сетевых интерфейсов каждый отдельно взятый интерфейс можно использовать под какую-то выделенную задачу, например отдельный интерфейс под трафик управления хостом и отдельный интерфейс под трафик периодического резервного копирования. Может возникнуть мысль о том, что такая конфигурация имеет свои плюсы, например, позволяет максимально жёстко разграничить утилизацию интерфейсов под особенности разных задач. Но на этом плюсы, пожалуй, и заканчиваются. Ибо при таком подходе может получиться так, что один интерфейс будет постоянно чем-то чрезмерно нагружен, а другой интерфейс будет периодически полностью простаивать. К тому же, в такой схеме каждый из физических интерфейсов будет выступать как конкретная сущность, при выходе из строя которой будет происходить остановка того или иного сетевого сервиса, жёстко связанного с этой сущностью. C точки зрения повышения доступности и балансировки нагрузки, более эффективными методом использования нескольких сетевых интерфейсов сервера является объединение этих интерфейсов в логические сущности с использованием технологий Network Bonding и Network Teaming.
В этой заметке на конкретном примере мы рассмотрим то, как с помощью технологии Network Bonding в ОС CentOS Linux 7.2 можно организовать объединение физических сетевых интерфейсов сервера в логический сетевой интерфейс (bond), а уже поверх него создать виртуальные сетевые интерфейсы под разные задачи и сетевые службы с изоляцией по разным VLAN. Агрегирование каналов между коммутатором и сервером будет выполняться с помощью протокола Link Aggregation Control Protocol (LACP) регламентированного документом IEEE 802.3ad. Использование LACP, с одной стороны, обеспечит высокую доступность агрегированного канала, так как выход из строя любого из линков между сервером и коммутатором не приведёт к потери доступности сетевых сервисов сервера, и с другой стороны, обеспечит равномерную балансировку нагрузки между физическими сетевыми интерфейсами сервера. Настройка в нашем примере будет выполняться как на стороне коммутатора (на примере коммутатора Cisco Catalyst WS-C3560G), так и на стороне Linux-сервера с двумя сетевыми интерфейсами (на примере сервера HP ProLiant DL360 G5 с контроллерами Broadcom NetXtreme II BCM5708/HP NC373i)
Настройка конфигурации LACP на коммутаторе Cisco
Активация механизмов LACP на коммутаторе Cisco сводится к созданию виртуальной группы портов channel-group и включению в эту группу нужных нам портов коммутатора.
Очищаем существующую конфигурацию портов коммутатора, которые будем включать в channel-group (в нашем примере это будут порты 21 и 22):
switch# configure terminal switch(config)# default interface range Gi0/21-22Создаём channel-group и включаем в неё нужные нам порты коммутатора, предварительно эти отключив порты:
switch(config)# interface range Gi0/21-22 switch(config-if-range)# shutdown switch(config-if-range)# channel-group 2 mode active Creating a port-channel interface Port-channel 2 switch(config-if-range)# no shutdown switch(config-if-range)# exitВносим изменения в свойства появившегося виртуального интерфейса Port-channel2:
switch(config)# interface Port-channel2 switch(config-if)# description LACP channel for KOM-AD01-VM32 switch(config-if)# switchport trunk encapsulation dot1q switch(config-if)# switchport trunk allowed vlan 1,2,4 switch(config-if)# switchport mode trunk switch(config-if)# exitИзменения в свойствах первого порта-участника channel-group вносим минимальные, так как основные параметры наследуются портом с виртуального интерфейса channel-group:
switch(config)# interface GigabitEthernet0/21 switch(config-if)# description LACP channel for KOM-AD01-VM32 (port enp3s0)switch(config-if)# channel-protocol lacp switch(config-if)# exitВносим изменения в свойства второго порта-участника channel-group:
switch(config)# interface GigabitEthernet0/22 switch(config-if)# description LACP channel for KOM-AD01-VM32 (port enp5s0) switch(config-if)# channel-protocol lacpНе забываем сохранить изменения:
switch(config-if)# end switch# writeПроверяем итоговую конфигурацию портов:
switch# show running-config ... interface Port-channel2 description LACP Channel for KOM-AD01-VM32 switchport trunk encapsulation dot1q switchport trunk allowed vlan 1,2,4 switchport mode trunk ... interface GigabitEthernet0/21 description LACP channel for KOM-AD01-VM32 (port enp3s0) switchport trunk encapsulation dot1q switchport trunk allowed vlan 1,2,4 switchport mode trunk channel-protocol lacp channel-group 2 mode active ... interface GigabitEthernet0/22 description LACP channel for KOM-AD01-VM32 (port enp5s0) switchport trunk encapsulation dot1q switchport trunk allowed vlan 1,2,4 switchport mode trunk channel-protocol lacp channel-group 2 mode active ...Проверяем статус подключения портов:
switch# show interfaces status... Gi0/21 LACP channel for K suspended trunk a-full a-1000 10/100/1000BaseTXGi0/22 LACP channel for K suspended trunk a-full a-1000 10/100/1000BaseTX... Po2 LACP channel for K notconnect unassigned auto auto ...До тех пор, пока на стороне нашего Linux-сервера не будет настроен LACP, статус портов будет отображаться как suspended/notconnect, а после настройки статус должен будет измениться на connected (это можно будет проверить позже):
switch# show interfaces status... Gi0/21 LACP channel for K connected trunk a-full a-1000 10/100/1000BaseTXGi0/22 LACP channel for K connected trunk a-full a-1000 10/100/1000BaseTX... Po2 LACP channel for K connected trunk a-full a-1000 ...Проверяем внутренний статус LACP:
switch# show lacp internal Flags: S - Device is requesting Slow LACPDUs F - Device is requesting Fast LACPDUs A - Device is in Active mode P - Device is in Passive mode ... Channel group 2 LACP port Admin Oper Port Port Port Flags State Priority Key Key Number State Gi0/21 SA susp 32768 0x2 0x2 0x15 0x7D Gi0/22 SA susp 32768 0x2 0x2 0x16 0x7D ...Здесь аналогично, до тех пор, пока на стороне нашего Linux-сервера не будет настроен LACP, статус LACP будет соответствующий, а после настройки статус должен будет измениться:
switch# show lacp internal ... Channel group 2 LACP port Admin Oper Port Port Port Flags State Priority Key Key Number State Gi0/21 SA bndl 32768 0x2 0x2 0x15 0x3D Gi0/22 SA bndl 32768 0x2 0x2 0x16 0x3D ...Теперь можем перейти к настройке Network Bonding с LACP на стороне Linux-сервера.
Настройка Network Bonding c LACP в CentOS Linux 7.2
Проверим наличие модуля поддержки bonding (команда должна отработать без ошибок):
# modinfo bondingВ ниже представленном примере мы рассмотрим сценарий настройки логического bond-интерфейса bond0 (master-интерфейс), членами которого будут два имеющихся в сервере физических интерфейса enp3s0 и enps5s0 (slave-интерфейсы). А затем на созданном bond-интерфейсе мы создадим дочерний VLAN-интерфейс, имеющий доступ к изолированной тегированной сети с определённым номером VLAN. Всю настройку мы будем выполнять путём прямой правки файлов интерфейсов.
Создадим файл с конфигурацией нового агрегирующего интерфейса bond0:
# nano /etc/sysconfig/network-scripts/ifcfg-bond0Наполним файл параметрами бонда bond0:
DEVICE=bond0 NAME=bond0 TYPE=Bond BONDING_MASTER=yesIPV6INIT=noMTU=9000ONBOOT=yesUSERCTL=noNM_CONTROLLED=no BOOTPROTO=none BONDING_OPTS="mode=802.3ad xmit_hash_policy=layer2+3 lacp_rate=1 miimon=100"Опции BONDING_OPTS можно передавать и через файл /etc/modprobe.d/bonding.conf, но вместо этого лучше использовать файлы ifcfg-bond*. Исключением здесь является лишь глобальный параметр max_bonds. Это замечание описано в документе Create a Channel Bonding Interface.
Получить информацию о всех возможных опциях BONDING_OPTS и вариантах их значений можно в документе Using Channel Bonding.
В нашем примере используется несколько опций:
- mode=802.3ad, который определяет режим работы bond-а (bonding policy). В нашем случае выбран режим с использованием протокола LACP. Этот режим для корректной работы должен поддерживаться и коммутатором, к которому подключаются сетевые интерфейсы bond-а.
- lacp_rate=fast, который заставляет bonding-интерфейс отсылать пакеты LACPDU ежесекундно, в то время как значение по умолчанию slow, которое определяет 30-секундный интервал.
- xmit_hash_policy=layer2+3, который определяет режим вычисления хешей при организации балансировки нагрузки между интерфейсами бонда. Эта опция используется только для режимов работы бонда (ранее описанный mode) поддерживающих балансировку нагрузки, таких как balance-xor и 802.3ad. Значение layer2+3 говорит о том, что для вычисления хешей будут использоваться как MAC адреса получателей/отправителей пакета, так и их IP адреса, если это возможно. Значение по умолчанию для этой опции – layer2, что определяет вычисление хеша только по MAC-адресам.
- miimon=100, который определяет количество миллисекунд для мониторинга состояния линка с помощью механизмов MII, который, к слову говоря, должен поддерживаться физическим сетевым контроллером. Значение опции miimon по умолчанию – 0, что значит, что данный функционал не используется.
Чтобы проверить то, может ли наш сетевой контроллер работать с MII, можно выполнить:
# ethtool enp3s0 | grep "Link detected:" Link detected: yesЗначение yes в данном случае говорит о поддержке MII.
Если вы используете режим active-backup bonding, то есть рекомендация настраивать дополнительную опцию bond-интерфейса: fail_over_mac=1. Как я понял, это нужно для того, чтобы использовать для bond в качестве основного MAC-адреса, MAC-адрес backup-интерфейса, что позволит сократить время потери соединений в процессе fail-over.
Создадим файл с конфигурацией slave-интерфейсов, то есть физических Ethernet-портов, которые будут участниками bond0 (файл скорее всего уже существует, так что просто отредактируем его под свою задачу):
# nano /etc/sysconfig/network-scripts/ifcfg-enp3s0Содержимое файла
DEVICE=enp3s0 NAME=bond0-slave0 TYPE=EthernetMTU=9000 BOOTPROTO=none ONBOOT=yesMASTER=bond0 SLAVE=yesUSERCTL=no NM_CONTROLLED=noВторой slave-интерфейс настраиваем по аналогии:
# nano /etc/sysconfig/network-scripts/ifcfg-enp5s0Параметры файла аналогичные за исключением параметров DEVICE и NAME
DEVICE=enp5s0 NAME=bond0-slave1 TYPE=EthernetMTU=9000 BOOTPROTO=none ONBOOT=yesMASTER=bond0 SLAVE=yesUSERCTL=noNM_CONTROLLED=noЕсли используется служба NetworkManager, то перезагрузим её конфигурацию с учётном созданных/изменённых файлов ifcfg-*:
# nmcli con reloadПерезапускаем slave-интерфейсы:
# ifdown enp3s0 && ifup enp3s0 # ifdown enp5s0 && ifup enp5s0Если отдельное отключение/включение интерфейсов приводит к ошибкам (это возможно в случае если ранее подключения контролировались службой NetworkManager), то перезапускаем сеть полностью:
# service network restartУбедимся в том, что созданные интерфейсы успешно запущены со статусом UP и заданными нами настройками, например обратим внимание на размер MTU.
# ip link show ... 2: enp3s0: mtu 9000 qdisc mq master bond0 state UP mode DEFAULT qlen 1000 link/ether 00:1f:28:0a:f7:f4 brd ff:ff:ff:ff:ff:ff 3: enp5s0: mtu 9000 qdisc mq master bond0 state UP mode DEFAULT qlen 1000 link/ether 00:1f:28:0a:f7:f4 brd ff:ff:ff:ff:ff:ff 4: bond0: mtu 9000 qdisc noqueue state UP mode DEFAULT link/ether 00:1f:28:0a:f7:f4 brd ff:ff:ff:ff:ff:ffИтак, bond создан и запущен в работу, и теперь переходим к созданию виртуальных интерфейсов с поддержкой VLAN поверх нашего bond-а.
Проверим наличие модуля поддержки VLAN (команда должна отработать без ошибок)
# modprobe 8021qПод каждый отдельный VLAN-интерфейс создаём конфигурационные файлы в каталоге /etc/sysconfig/network-scripts по типу ifcfg-bond<номер бонда>.<номер VLAN-а>. Например создадим конфигурационный файл для bond-интерфейса bond0 с VLAN 2
# nano /etc/sysconfig/network-scripts/ifcfg-bond0.2Содержимое файла:
DEVICE=bond0.2NAME=bond0-vlan2 BOOTPROTO=none ONBOOT=yes USERCTL=no NM_CONTROLLED=no VLAN=yesMTU=1500 IPV4_FAILURE_FATAL=yesIPV6INIT=no IPADDR=10.1.0.32 PREFIX=24GATEWAY=10.1.0.1DNS1=10.1.0.9DNS2=10.1.1.8DOMAIN=holding.comПопробуем поднять созданный VLAN-интерфейс или опять-же просто перезапускаем сеть:
# ifup ifcfg-bond0.2# service network restartЧтобы разнообразные сетевые службы, используемые на нашем сервере приняли во внимание изменение сетевой конфигурации, можно перезапустить их, либо просто перезагрузить сервер.
Убедимся в том, что VLAN-интерфейс поднялся с указанными нами настройками:
# ip link show ... 5: bond0.2@bond0: mtu 1500 qdisc noqueue state UP mode DEFAULT link/ether 00:1f:28:0a:f7:f4 brd ff:ff:ff:ff:ff:ffАналогичным образом мы можем создать на сервере столько выделенных виртуальных VLAN интерфейсов, сколько потребуется для разделения трафика между разными задачами и сетевыми службами исполняемыми на сервере.
Проверяем статус работы bond0:
# cat /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: IEEE 802.3ad Dynamic link aggregation Transmit Hash Policy: layer2+3 (2) MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 802.3ad info LACP rate: fast Min links: 0 Aggregator selection policy (ad_select): stable Active Aggregator Info: Aggregator ID: 1 Number of ports: 2 Actor Key: 9 Partner Key: 2 Partner Mac Address: 00:1c:f8:57:bd:50 Slave Interface: enp3s0 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:1f:28:0a:f7:f4 Slave queue ID: 0 Aggregator ID: 1 Actor Churn State: none Partner Churn State: none Actor Churned Count: 0 Partner Churned Count: 0 details actor lacp pdu: system priority: 65535 port key: 9 port priority: 255 port number: 1 port state: 63 details partner lacp pdu: system priority: 32768 oper key: 2 port priority: 32768 port number: 21 port state: 61 Slave Interface: enp5s0 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:1f:29:0a:f7:f8 Slave queue ID: 0 Aggregator ID: 1 Actor Churn State: none Partner Churn State: none Actor Churned Count: 0 Partner Churned Count: 0 details actor lacp pdu: system priority: 65535 port key: 9 port priority: 255 port number: 2 port state: 63 details partner lacp pdu: system priority: 32768 oper key: 2 port priority: 32768 port number: 22 port state: 61Если в секции 802.3ad info значение параметра Partner Mac Address не содержит MAC-адреса коммутатора, а вместо этого видно значение 00:00:00:00:00:00, это значит то, что обмен пакетами LACPDU с коммутатором по какой-то причине не выполняется (либо на стороне коммутатора неправильно настроен LACP, либо коммутатор вовсе его не поддерживает)
На этом этапе агрегированный LACP линк между коммутатором и сервером можно считать настроенным. На стороне коммутатора убедимся в том, что вывод ранее упомянутых команд изменился:
switch# show interfaces status switch# show lacp internalТеперь можно переходить к заключительному этапу – проверкам нашего LACP соединения на предмет устойчивости соединения при отказе любого из портов на стороне коммутатора/сервера а также на предмет корректности балансировки нагрузки.
Проверка высокой доступности соединения
Теперь попробуем проверить устойчивость нашего LACP-соединения. Для этого запустим с любой сторонней системы, например с рабочей станции администратора, ping IP-адреса bond-интерфейса сервера
ping -t 10.1.0.32Подключимся к коммутатору Cisco и выполним отключение одного из портов, входящих в группу channel-group, обеспечивающей со стороны коммутатора LACP-соединение.
switch# configure terminal switch(config)# int Gi0/21 switch(config-if)# shutdownУбедимся в том, что запущенная утилита ping не отражает факт потери пакетов. Если всё в порядке, включим отключенный порт коммутатора, а затем отключим второй порт входящий в группу channel-group:
switch(config-if)# no shutdown switch(config-if)# exit switch(config)# int Gi0/22 switch(config-if)# shutdown switch(config-if)# no shutdown switch(config-if)# endСнова проверим, что ping не имеет потерь пакетов. Если всё в порядке, включим отключенный порт коммутатора и будем считать, что наше LACP-соединение Cisco channel-group <-> Linux bond успешно отрабатывает ситуацию потери соединения на любом из интерфейсов коммутатора, входящих в channel-group. Аналогичную проверку можно выполнить и со стороны Linux сервера попеременно отключая интерфейсы входящие в bond:
# ifdown enp3s0 # ifup enp3s0 # ifdown enp5s0 # ifup enp5s0Здесь между включением первого интерфейса и отключением второго для чистоты эксперимента нужно сделать небольшую паузу (5-7 секунд), чтобы LACP-линк смог полностью перестроиться для того, чтобы не было потерь пакетов. Если же эту паузу не сделать, то несколько пакетов может таки потеряться, но потом соединение всё-же будет автоматически восстановлено.
Проверка балансировки нагрузки соединения
Чтобы проверить факт того, что трафик действительно распределяется по интерфейсам bond-а, воспользуемся немного более сложной процедурой тестирования, для которой используем три компьютера, то есть сам наш сервер KOM-AD01-VM32 (IP: 10.1.0.32) и любые два Linux-компьютера, например KOM-AD01-SRV01 (IP: 10.1.0.11) и KOM-AD01-SRV02 (IP: 10.1.0.12). Установим на все три компьютера две утилиты - iperf (для тестирования скорости) и nload (для отображения нагрузки интерфейсов в реальном времени).
Начнем с проверки входящего трафика.
Установим на проверяемом сервере KOM-AD01-VM32 утилиты iperf и nload а затем на время теста выключим брандмауэр (либо можете создать разрешающее правило для порта, который будет слушать запущенный серверный iperf, по умолчанию это TCP 5001). Запустим утилиту iperf в режиме сервера (с ключом -s), то есть ориентированную на приём трафика:
# yum -y install iperf nload# service firewalld stop# iperf -s------------------------------------------------------------Server listening on TCP port 5001TCP window size: 85.3 KByte (default)------------------------------------------------------------
Здесь же, но в отдельной консоли, запустим утилиту nload, которая в реальном времени будет показывать нам статистические значения нагрузки на интерфейсы. В качестве параметров укажем названия интерфейсов, за нагрузкой которых нужно следить:
# nload enp3s0 enp5s0Затем выполняем отсылку трафика с помощью iperf (в режиме клиента) с компьютеров KOM-AD01-SRV01 и KOM-AD01-SRV02 (запустим одинаковую команду одновременно на обоих этих компьютерах):
# iperf -c 10.1.0.32 -t 600 -i 2 -b 100mВ качестве параметров iperf укажем следующие значения:
- -c – работа в режиме клиента (отсылка трафика)
- 10.1.0.32 - IP адрес сервера, на который клиент iperf будет посылать трафик (KOM-AD01-VM32)
- -t 600 – время, в течение которого будет выполняться отсылка трафика (600 секунд)
- -i 2 - интервал в секундах для вывода статистической информации об отсылке трафика на экран (каждые 2 секунды)
- -b 100m – размер пропускной способности сети, которую будет пытаться задействовать iperf при отсылке трафика (в нашем случае 100 мегабит/с)
После того, как iperf в режиме клиента начнёт работу на обоих серверах, переходим на проверяемый сервер KOM-AD01-VM32 и наблюдаем за статистикой nload. На начальном экране увидим статистику по входящему и исходящему трафику по первому интерфейсу (enp3s0). Обращаем внимание на значения по входящему трафику:
Device enp3s0 (1/2): =========================================================================================== Incoming: ############################################################ Curr: 98.64 MBit/s ############################################################ Avg: 99.14 MBit/s ############################################################ Min: 0.00 Bit/s ############################################################ Max: 197.12 MBit/s ############################################################ Ttl: 120.64 GByte ...Чтобы увидеть статистику по следующему интерфейсу (enp5s0) просто нажмём Enter:
Device enp5s0 (2/2): =========================================================================================== Incoming: ############################################################ Curr: 97.93 MBit/s ############################################################ Avg: 97.97 MBit/s ############################################################ Min: 0.00 Bit/s ############################################################ Max: 196.68 MBit/s ############################################################ Ttl: 40.56 GByte ...Как видим, скорость на обоих интерфейсах распределена равномерно и равна примерно 100 мегабит/с, значит балансировка входящего трафика работает успешно.
***
Далее, по аналогичной методике, протестируем механизм балансировки нагрузки для трафика исходящего с нашего подопытного сервера KOM-AD01-VM32. Для этого iperf будет запускаться на компьютерах KOM-AD01-SRV01/KOM-AD01-SRV02 в режиме сервера, принимающего трафик. Запустим одинаковую команду на обоих этих компьютерах, не забывая при этом про необходимость открытия порта для сервера iperf:
# iperf -sА на компьютере KOM-AD01-VM32 утилиту iperf запускаем в режиме клиента, отправляющего трафик на компьютеры KOM-AD01-SRV01/KOM-AD01-SRV02, используя при этом запуск из двух разных консолей:
# iperf -c 10.1.0.11 -t 600 -i 2 -b 100m# iperf -c 10.1.0.12 -t 600 -i 2 -b 100mЗапускаем на компьютере KOM-AD01-VM32 третью консоль и наблюдаем за ситуацией в nload
# nload enp3s0 enp5s0На этот раз обращаем внимание на исходящий трафик на первом интерфейсе…
Device enp3s0 (1/2): ============================================================================================ ... Outgoing: ############################################################# Curr: 102.88 MBit/s ############################################################# Avg: 51.36 MBit/s ############################################################# Min: 0.00 Bit/s ############################################################# Max: 111.24 MBit/s ############################################################# Ttl: 1.53 GByte…и исходящий трафик на втором интерфейсе…
Device enp5s0 (2/2): ============================================================================================ ... Outgoing: ############################################################# Curr: 101.16 MBit/s ############################################################# Avg: 59.73 MBit/s ############################################################# Min: 5.14 kBit/s ############################################################# Max: 110.71 MBit/s ############################################################# Ttl: 1.89 GByteКак видим, трафик распределён по разным интерфейсам нашего bond-a, значит балансировка исходящего трафика работает успешно.
Если ранее на время теста отключался брандмауэр, то по окончанию теста не забываем включить его обратно:
# service firewalld startНа этом всё.
Дополнительные источники информации:
Поделиться ссылкой на эту запись:
Похожее
blog.it-kb.ru
Оптимизация заданий Apache Spark. Часть 1.
Изучаем методы оптимизации заданий Apache Spark, позволяющие добиться высокой эффективности.
Когда вы пишете код для Apache Spark и читаете документацию по API, вам встречаются такие термины, как преобразование (transformation), действие (action) и RDD (resilient distributed dataset, эластичный распределенный набор данных). Понимание Spark на данном уровне является жизненно важным для написания программ. Когда ваше приложение не работает, или когда вы обращаетесь к веб-интерфейсу, чтобы выяснить, почему ваше приложение выполняется так долго, вы также сталкиваетесь с новыми терминами, такими как задание (job), этап (stage) и задача (task). Понимание Spark на этом уровне является жизненно важным для написания хороших программ. Безусловно, я подразумеваю, что хорошие программы – это быстрые программы. Чтобы написать эффективную программу для Spark, крайне важно понимать базовую модель выполнения Spark.
Из этой статьи вы узнаете о том, как на самом деле программы Spark выполняются на кластере. Затем вы получите некоторые практические сведения о том, как написание эффективных программ взаимосвязано с моделью выполнения Spark.
Как Spark выполняет вашу программу?
Приложение Spark состоит из одного управляющего процесса, называемого драйвером (driver process), и набора исполняющих процессов, называемых исполнителями (executor process), которые рассредоточены по узлам кластера.
Драйвер обеспечивает высокоуровневое управление рабочим процессом. Исполнители обеспечивают выполнение работы в форме задач (task), а также хранение любых данных, которые пользователь хочет кэшировать. Драйвер и исполнители работают в течение всего процесса выполнения программы, при этом ресурсы для исполнителей выделяются динамически. Каждый исполнитель способен параллельно выполнять несколько задач. Развертывание этих процессов на кластере осуществляется менеджером кластера (YARN, Mesos или Spark Standalone), но драйвер и исполнители присутствуют в каждом приложении Spark.
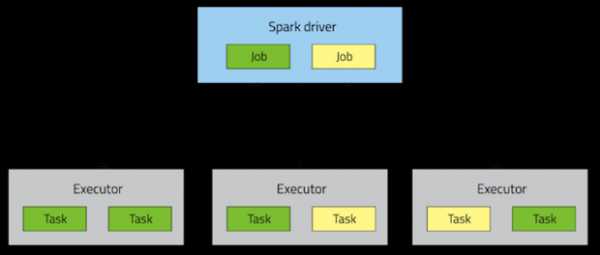
На верхней позиции в иерархии выполнения находятся задания. Вызов действия в приложении Spark инициирует запуск соответствующего задания. Чтобы определить, что собой представляет это задание, Spark анализирует граф RDDs, принимающих участие в этом действии, и формирует план выполнения. Этот план начинается с наиболее старых RDDs (не зависящих от других RDDs или ссылающихся на уже кэшированные данные) и заканчивается на последнем RDD, необходимом для получения результатов действия.
План выполнения объединяет преобразования (transformation) в этапы. Этап представляет собой совокупность задач, выполняющих один и тот же код на разных подмножествах данных. Каждый этап включает в себя последовательность преобразований, которые могут быть выполнены без перемешивания (shuffle) всего набора данных.
Что определяет, должны ли данные перемешиваться? Вспомним о том, что RDD содержит фиксированное количество разделов (partition), каждый из которых содержит некоторое количество записей (record). В случае RDDs, полученных в результате так называемых узких (narrow) преобразований, таких как отображение (map) и фильтрация (filter), записи, необходимые для вычисления записей в одном разделе, находятся в одном разделе в родительском RDD. Каждый объект зависит только от одного объекта в родителе. Такие операции, как coalesce, могут привести к тому, что задача будет работать с несколькими входными разделами, но преобразование по-прежнему будет считаться узким, потому что входные записи, используемые для вычисления любой выходной записи, по-прежнему могут находиться только в ограниченном подмножестве разделов.
Однако Spark также поддерживает преобразования с широкими (wide) зависимостями, такие как groupByKey и reduceByKey. В рамках таких зависимостей, данные, необходимые для вычисления записей в одном разделе, могут находиться в нескольких разделах родительского RDD. Все кортежи (tuple) с одинаковыми ключами (key) должны оказаться в одном разделе, обрабатываемом одной задачей. Чтобы реализовать эти операции, Spark должен выполнить перемешивание, перемещающее данные по кластеру и формирующее новый этап с новым набором разделов.
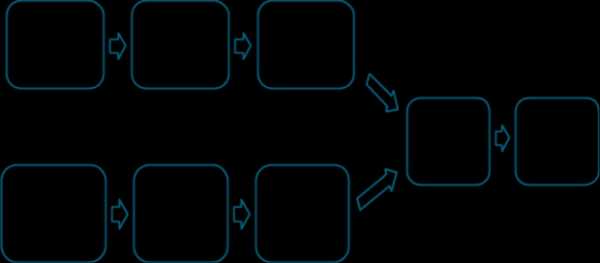
Для примера рассмотрим следующий код:
Этот код выполняет одно действие, основывающееся на последовательности преобразований RDD, полученного из текстового файла. Код будет выполнен в один этап, потому что ни один из результатов этих трех операций не зависит от данных, которые могут поступать из разделов, отличных от тех, из которых поступают их входные данные.
Для сравнения, следующий код определяет, сколько раз каждый символ встречается во всех словах, встречающихся в текстовом файле более чем 1 000 раз.
Этот процесс будет разделен на три этапа. Операции reduceByKey формируют границы этапов, потому что для вычисления их результатов необходимо заново разделить данные (repartition) на основе ключей.
Ниже представлена более сложная схема преобразования, включающая соединение (join) с множественными зависимостями.
Розовые рамки демонстрируют результирующую схему этапов выполнения.
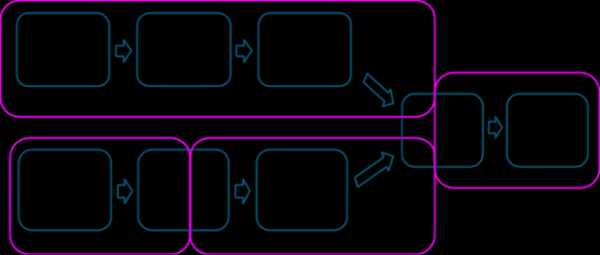
На границе каждого этапа данные записываются на диск задачами родительских (parent) этапов, а затем извлекаются через сеть задачами дочернего (child) этапа. Поскольку на границах этапов выполняются ресурсоемкие операции дискового и сетевого ввода/вывода, следует избегать границ этапов, когда это возможно. Количество разделов данных на родительском этапе может отличаться от количества разделов на дочернем этапе. Преобразования, которые могут формировать границу этапа, обычно принимают параметр numPartitions, определяющий, на какое количество разделов необходимо разделить данные на дочернем этапе.
Так же, как количество редукторов (reducer) является важным параметром при настройке заданий MapReduce, настройка количества разделов на границах этапов может существенно повлиять на производительность приложения. В дальнейшем мы глубже разберемся в том, как настроить это количество.
Выбор подходящих операторов
При реализации какой-либо программы для Spark, разработчику обычно доступны различные комплексы действий и преобразований, обеспечивающие одинаковые результаты. Однако не все они обеспечивают одинаковую производительность. Умение избегать распространенных ошибок и выбирать подходящие механизмы может существенно повысить производительность приложения. Несколько правил и рекомендаций помогут вам сделать правильный выбор.
В рамках работы над проблемой SPARK-5097 [ссылка] была начата стабилизация SchemaRDD, в результате чего оптимизатор Spark Catalyst будет открыт для программистов, использующих базовые API Spark. Как следствие, Spark получит возможность осуществлять выбор операторов на более высоком уровне. Когда SchemaRDD станет стабильным компонентом, пользователи будут избавлены от необходимости принимать некоторые из этих решений.
Основная цель при выборе набора операторов – уменьшение количества перемешиваний и объема перемешиваемых данных. Это объясняется тем, что перемешивания являются ресурсоемкими операциями, так как все перемешиваемые данные должны быть записаны на диск, а потом переданы по сети. Преобразования repartition, join, cogroup и любое из преобразований *By или *ByKey могут привести к перемешиваниям. Однако не все эти операции эквивалентны, и некоторые из самых распространенных ошибок, влияющих на производительность, которые допускают начинающие Spark-разработчики, возникают в результате неправильного выбора операции:
- Не используйте groupByKey, когда выполняете ассоциативную операцию свертки (associative reductive operation). Например, rdd.groupByKey().mapValues(_.sum) даст те же результаты, что и rdd.reduceByKey(_ + _). Тем не менее в первом случае весь набор данных будет передан по сети, а во втором – будут вычислены локальные суммы для каждого ключа в каждом разделе, после чего эти локальные суммы будут объединены в более крупные суммы после перемешивания.
- Не используйте reduceByKey, когда типы входного и выходного значений различны. Для примера рассмотрим преобразование, которое находит все уникальные строки, соответствующие каждому ключу. В качестве одного из вариантов можно использовать отображение, чтобы преобразовать каждый элемент в Set, а затем объединить все Set с помощью reduceByKey:
Этот код приводит к созданию массы ненужных объектов, потому что объект Set должен быть создан для каждой записи. Лучше использовать операцию aggregateByKey, выполняющую агрегацию на стороне отображения (map-side) более эффективно:
- Не используйте шаблон flatMap-join-groupBy. Когда два набора данных уже сгруппированы по ключу, и вы хотите соединить их, сохраняя сгруппированными, можно просто использовать когруппу (cogroup). Такой подход позволяет избежать накладных расходов, связанных с распаковкой (unpack) и повторной упаковкой (repack) групп.
Когда перемешивания не происходят
Также полезно знать о тех случаях, когда представленные выше преобразования не приводят к перемешиваниям. Spark не выполняет перемешивание, если в результате предыдущего преобразования данные уже были разделены в соответствии с тем же разделителем (partitioner).
Рассмотрим следующий код:
Поскольку разделитель не передается в reduceByKey, будет использован разделитель по умолчанию, в результате чего rdd1 и rdd2 будут разделены по хешу (hash-partition). Две операции reduceByKey приведут к двум перемешиваниям. Если RDDs имеют одинаковое количество разделов, тогда соединение не потребует дополнительного перемешивания. Поскольку RDDs разделены идентично, набор ключей в одном разделе rdd1 может появиться только в одном разделе rdd2. Таким образом, содержимое одного выходного раздела rdd3 будет зависеть только от содержимого одного раздела rdd1 и одного раздела rdd2, и третье перемешивание не потребуется.
Например, если someRdd имеет четыре раздела, someOtherRdd имеет два раздела, а обе операции reduceByKey используют три раздела, набор задач будет следующим:
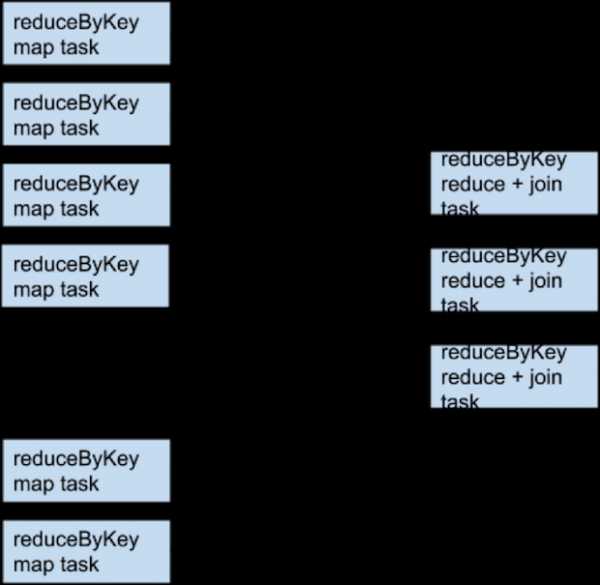
Что если rdd1 и rdd2 используют разные разделители или используют разделитель по умолчанию (по хешу) с разными количествами разделов? В этом случае только один RDD (тот, у которого наименьше количество разделов) должен быть заново перемешан для соединения.
Те же преобразования, те же входные данные, разное количество разделов:

В качестве одного из способов избежать перемешивания при соединении двух наборов данных можно воспользоваться преимуществами «транслируемых» переменных (broadcast variable). Если один из наборов данных достаточно мал, чтобы поместиться в памяти одного исполнителя, он может быть загружен в хеш-таблицу драйвера и затем «транслироваться» каждому исполнителю. После этого преобразование map может обращаться к хеш-таблице для выполнения поиска.
В каком случае будет лучше, если будет больше перемешиваний
Существует редкое исключение из правила минимизации количества перемешиваний. Дополнительное перемешивание может повысить производительность в том случае, если оно повышает уровень параллелизма. Например, если вы получаете данные в виде нескольких неделимых файлов, разделение, диктуемое InputFormat, может поместить большое количество записей в каждый раздел, в то же время не создав достаточное количество разделов, чтобы использовать все доступные ядра. В этом случае, осуществление нового разделения с большим количеством разделов (которое инициирует перемешивание) после загрузки данных позволит операциям, поступающим после него, более эффективно использовать процессоры кластера.
Другой пример данного исключения может возникнуть при использовании действий свертки (reduce) или агрегации (aggregate) для того, чтобы агрегировать данные в драйвер. При агрегации большого количества разделов, вычисления быстро могут стать узким местом для одного потока драйвера, объединяющего все результаты вместе. Чтобы уменьшить нагрузку на драйвер, сначала можно использовать reduceByKey или aggregateByKey, чтобы выполнить стадию распределенной агрегации, которая разделяет набор данных на меньшее количество разделов. Значения в каждом разделе параллельно объединяются друг с другом перед отправкой результатов драйверу для финальной стадии агрегации. Рассмотрите treeReduce и treeAggregate в качестве примеров того, как это можно реализовать. (Обратите внимание, в самой последней версии на момент написания (1.2) эти функции помечены, как API для разработчиков, но в рамках решения проблемы SPARK-5430 предлагается добавить их стабильные версии в ядро.)
Этот прием особенно полезен, когда агрегация уже сгруппирована по ключу. Для примера рассмотрим приложение, которое должно посчитать количество вхождений каждого слова в корпусе и передать результаты в драйвер в виде отображения. В качестве подхода, реализуемого с помощью агрегации, можно вычислить локальное отображение для каждого раздела, а затем объединить отображения в драйвере. В качестве альтернативного подхода, реализуемого с помощью aggregateByKey, можно выполнить подсчет полностью распределенным способом, а затем просто передать результаты драйверу с помощью collectAsMap.
Вторичная сортировка
Еще одной полезной возможностью является преобразование repartitionAndSortWithinPartitions. Данное преобразование передает сортировку механизму перемешивания, где большие объемы данных могут быть эффективно обработаны, и сортировка может быть объединена с другими операциями.
Например, Apache Hive использует это преобразование внутри своей реализации преобразования join. Оно также играет роль ключевого строительного блока в шаблоне вторичной сортировки (secondary sort), в рамках которого вы стремитесь сгруппировать записи по ключу, а затем, в процессе итераций по значениям, относящимся к ключу, вывести их в определенном порядке. Эта задача возникает в алгоритмах, которые группируют события по пользователю, а потом анализируют события для каждого пользователя, на основе последовательности возникновения этих событий во времени. Использование repartitionAndSortWithinPartitions для выполнения вторичной сортировки на текущий момент представляет некоторые сложности для пользователя, но в рамках решения проблемы SPARK-3655 предполагается существенное упрощение.
Заключение
Теперь вы должны хорошо понимать базовые подходы, позволяющие создавать высокопроизводительные программы Spark! Во второй части мы рассмотрим оптимизацию запросов ресурсов, параллелизма и структур данных.
По материалам: Cloudera
datareview.info