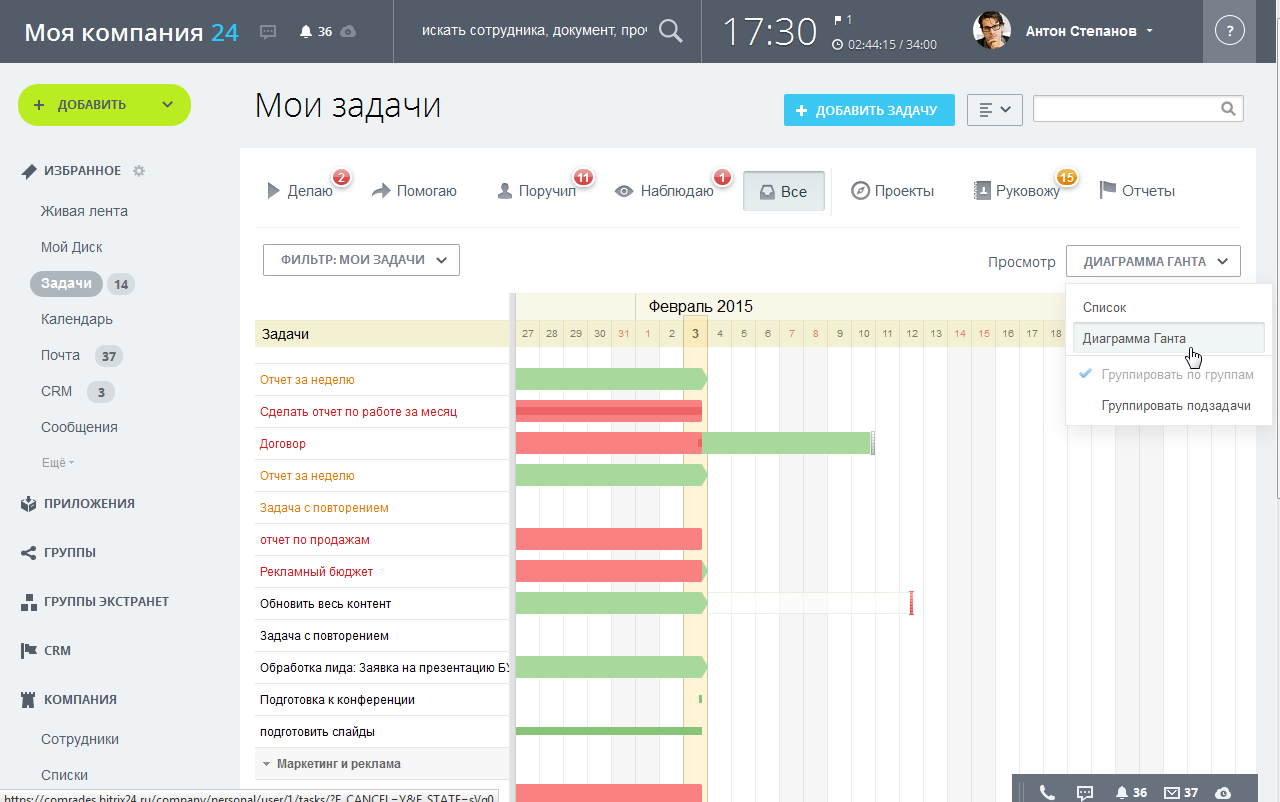
Куда ушли сайты со «средним» бюджетом, или как делать по 80 проектов в год с помощью Маркетплейса. Битрикс хабрахабр
Куда ушли сайты со «средним» бюджетом, или как делать по 80 проектов в год с помощью Маркетплейса
Что это за «средние сайты»? Произошло ли что-нибудь с этим сегментом в последнее время? Может быть, средние сайты никуда не делись?
Текст написан по мотивам выступления Романа Петрова (@romanpetrov), директора компании ITConstruct, на Партнерской конференции «1С-Битрикс». Мы работаем с клиентами из разных типов бизнеса: малого, среднего, крупного. Мы стараемся распределять заказы так, чтобы в случае проседания одного из сегментов у нас оставались средства в другом. Мы успешно реализуем энтерпрайз-проекты, но при этом ежегодно делаем много небольших и средних проектов. Например, за последний год их было около 80. Что такое «средний сегмент»?
- Интернет-магазин — 200—750 тыс. рублей, корпоративный сайт — 150—500 тыс. рублей
- Клиенты, заказывающие такие сайты — обязательно средний или малый бизнес
- От 3 до 9 месяцев работы от старта до запуска проекта
Что мы хотим, когда к нам приходит клиент?
- Работать долго и хорошо
- Чтобы клиент действительно мог потратить озвученный бюджет на наши услуги
- Чтобы реализация проекта не затягивалась
- Чтобы было как можно меньше рисков: у клиента уволился менеджер, ведущий проект; закончились деньги; «давайте вернёмся к этому через год, у нас годовое планирование», и так далее
- Чтобы потом клиент, которому мы разработали сайт, в дальнейшем пользовался нашими услугами по поддержке и продвижению
Описание характерной ситуации в среднем сегменте
У нас бывают клиенты, которым нужен сайт «для галочки». Но чаще всего клиенты из среднего сегмента уже приходят с пониманием, что сайт им нужен для решения какой-то задачи. Повышения продаж. Создания дилерского кабинета.Очевидно, что сайт должен хорошо работать на мобильных устройствах, быть адаптивным. Но не все понимают, что это стоит денег. Да и бюджет у клиента всё равно ограничен. Возникает конфликт интересов.
С одной стороны, мы хотим работать с этим клиентом. Он нам интересен. С другой стороны, смета (по задачам клиента) превышает его бюджет. Разработка индивидуального проекта требует значительно больших ресурсов, а следовательно, и стоит в несколько раз дороже, чем есть у клиента.
В качестве примера могу привести смету типового индивидуального проекта (2—3 млн. рублей). 75% — это затраты на проектирование, аналитику, дизайн и вёрстку. Если проект меньше (500—750 тыс. рублей), эти статьи займут около 80% бюджета. И за эти деньги получается красивый промо-сайт, а не интернет-магазин.
Но к нам клиент приходит не за промо-сайтом, а за средством решения бизнес-задач. Очень сложно объяснить, что решение, которое он хочет купить за 750 тыс., стоит 3 миллиона.
Что делать?
- Уйти в крупные проекты, в энтерпрайз. Но там вас не ждут.
- Можно уйти в низкий сегмент.
- Можно попробовать поднять цену в процессе работы. Почти все так пытаются сделать, но не у всех получается. При этом, у клиента будет ощущение, что его пытаются обмануть.
- Сделать первый проект в минус, чтобы получить клиента, а потом в течение двух-трёх лет зарабатывать на дополнительных работах и выйти в плюс. Но в среднем сегменте этот подход не работает: клиент чувствителен к цене, он редко заказывает дополнительные работы. Исключения редки
- Классический вариант, который мы и применяем — это разбить проект на этапы.
Как выбирает заказчик?
- По рекомендации. Это самое классное. Если заказчик к вам пришел по рекомендации, он вам уже верит
- По опыту/портфолио
- По личному общению. У вас может не быть рекомендаций. Но вы лично его убедите
- По соответствию его образу. Что это значит? Заказчик приходит к вам с представлением, каким должен быть сайт. Вы начинаете уточнять — оказывается, что его пожелания не стыкуются между собой. «То есть вот это вот должно работать. А как конкретно?» — «Ну вот тут человек оставляет заявку. А тут у нас заказ в «1С». — «А вот между этим что?» — «А между этим вы сделайте что-нибудь»
С этим ничего не поделать. С этим просто надо жить. Если мы не можем предложить клиентам среднего сегмента индивидуальный проект по той цене, которая их устраивает, то мы предлагаем им поэтапный проект.
Предлагаем мы его вот такими магическими фразами. Буквально с некоторыми вариациями, это скрипт продаж:
Юля. Вот вам нужен интернет-магазин. Но мы точно знаем, что вы поработаете с ним полгода, и появятся новые требования. Вам понадобится другое решение. А сейчас вы вложитесь в индивидуальную разработку и у вас деньги будут полгода стоять. Поэтому мы предлагаем сначала наработать опыт. А потом его учесть в полноценном индивидуальном сайте. Мы сейчас смотрим ваших конкурентов. Смотрим Машу, смотрим Дашу. У них вот такие сайты. Они красивые. Но как они внутри работают, приводят ли они клиентов, — мы не знаем. Потому что сейчас мы говорим о дизайне. А нужно отлаживать бизнес-процессы, склад, интеграцию с «1С».Мы вам советуем запуститься с сайтом на готовом решении. Оно начнет работать, приносить прибыль. При этом мы индивидуализируем готовое решение под ваш стиль. А в процессе работы сайта, по вашему желанию, его можно переработать под ваши требования и пожелания.
Вот у вас iPhone? И у меня iPhone. Глядите, ваш iPhone от моего отличается. У вас, во-первых, он в золоте, а у меня серебряный. А во-вторых, у вас чехол, а у меня нет. Вот видите, индивидуальный. С сайтом можно сделать тоже самое. Вы будете отличаться от Маши. А ваш сайт еще будет к тому же адаптивный. Выглядит это примерно вот так.
Мы обычно выбираем решения в Маркетплейсе из работ нескольких разработчиков. Они висят в лидерах продаж «1С-Битрикс». Если решение для нас незнакомое, то мы смотрим на два показателя:
- Как оно себя ведёт
- Аккуратно ли сделано
При поэтапном внедрении мы используем два подхода:
- Когда клиент готов платить совсем по чуть-чуть. Мы говорим: «Готовый комплект, установка готового решения, интеграция с 1С. А потом тебя ждут с распростертыми объятиями в техподдержке. Платишь за время, делаем всё, что скажешь. Хочешь снежок на сайте, будет снежок на сайте. Хочешь елочку, будет елочка».
- Когда клиент не слишком коммуникабелен. Мы говорим: «Вот вам менеджер проекта. Давайте список задач, будем оценивать мини-проекты. Либо вот вам менеджер проекта. Оплата по фактически затраченному времени. Делаем, обсуждаем консалтинг, программирование, дизайн, тестирование, все дела».
Подводные камни
Но вы можете столкнуться с рядом подводных камней, с которыми столкнулись мы. Есть компании, которые были партнёрами «1С-Битрикс» ещё в 2008-2010. Тогда продавали так. Приходит клиент, говорит: «Хочу форму обратной связи и интернет-магазин». Вы говорите: «Вот 1С-Битрикс. У него есть модуль формы обратной связи, интернет-магазин — 25 тыс.». Клиент: «Нормально». Развёртываем готовый продукт. А клиент говорит: «Всё не так. Надо по-другому, вы не говорили что это работает так». И это приводило к ненужным спорам, бесплатной работе или недовольству клиента.Готовое решение из Маркетплейса нужно продавать, не наступая на грабли завышенных ожиданий. То есть клиенту нужно показывать готовое решение и говорить: «Мы поставим это сюда. Вот тут есть SKU. Они будут вот так. У вас 1С?» — «Да» — «Это надо доработать. И вот это тоже, и вот это». То есть нужно работать, не создавая у клиента завышенных ожиданий. Потому что чудес не бывает.
Готовое решение — отличный вариант для старта. Но и готовые решения могут в конце концов потребовать большого объёма изменений и доработок. Вы можете столкнуться с тем, что придётся сказать клиенту: «Ты повзрослел. Теперь тебе нельзя использовать готовое. Пора создавать индивидуальное». Или: «Давай выберем другое».
Нельзя продавать функции по маркетинговому описанию. Продавайте то, что видите. Очень часто в маркетинговых описаниях что-то преувеличивают. Поэтому прежде чем продавать, изучите самостоятельно, как работает предлагаемый продукт.
И очень важный момент: в среднем сегменте дизайн всё равно важен. То есть клиент хочет, чтобы его сайт выглядел его сайтом. Поэтому на первом этапе мы говорим клиенту: «Вы купили сайт, давайте мы его наполним вашей информацией. Поставьте туда ваши товары. Напишите туда ваши новости. Ваши контакты. Поставьте ваш баннер, слайдер, чтобы сайт стал совсем ваш». Пусть клиент с ним сживётся. А когда он делает что-то руками, то прикипает к нему. И сам говорит, что так и хотел сделать.
Мы считаем, что средний сегмент не слишком уменьшился в размере. Просто рынок изменился, жизнь изменилась. Люди не готовы ждать по 7-9 месяцев, пока им сделают сайт. И делать сайты в «в лоб» для нас стало невыгодным. Потому что интернет-магазин — это три адаптивных состояния. В каждом из которых нужно делать до 40 страниц. Это очень большая работа. Поэтому мы делаем 80 сайтов в год на готовом решении. И половина из них потом «встают» на поддержку, на продвижение. И за год дают нам ту же прибыль, что и индивидуальный сайт среднего размера.
habr.com
Как мы создали «Открытые линии» в «Битрикс24» / Блог компании 1С-Битрикс / Хабр
Сегодня пользователи хотят общаться с компаниями не по электронной почте и телефону, а через любимые мессенджеры и аккаунты в социальных сетях.В ответ социальные сети и мессенджеры начали внедрять новый функционал. ВКонтакте и Facebook выкатили личные сообщения для групп и публичных страниц.
Telegram с его каналами и ботами превратился в платформу для публикаций и взаимодействия с аудиторией. В Viber появились публичные аккаунты.
Чтобы получить максимальный профит бизнесу нужно пользоваться всеми возможностями всех социальных площадок.
Так родились «Открытые линии» — новый инструмент для взаимодействия клиентов «Битрикс24» с конечными пользователями.
Схема работы «Открытых линий» несложная:
- Мы получаем все пользовательские сообщения из мессенджеров и социальных сетей
- Маршрутизируем их с помощью встроенного в «Битрикс24» мессенджера. Распределяем по операторам
- Клиенты отвечают на сообщения, а мы маршрутизируем ответы обратно менеджерам компаний, работающих на «Битрикс24»
А чтобы обеспечить стабильную работу в облачной и коробочной версиях «Битрикс24», мы создали централизованный сервер коннекторов. Он обрабатывает все потоки информации.
ВКонтакте
Следующий шаг мы проходили в тесном дуэте с разработчиками ВКонтакте. Нам удалось выстроить оптимальную схему работы с сервисом — теперь мы делали за пользователей кучу технических действий для подключения.Теперь этот API ВКонтакте могут использовать и другие сервисы.
Как теперь выглядит подключение «Открытых линий» для обычного пользователя:
- Авторизуетесь в VK.
- В разделе подключения выбираете нужную группу.
- Подтверждаете.
Выглядит просто, но лишь потому, что мы спрятали под капот всю «кухню» — порядка десяти операций, вместе с запросами на получение разных ключей.
Skype
А вот с Microsoft было сложно. К сожалению, они очень фокусируются на «олдскульных» айтишниках. Подключение к их бот-фреймворку вышло сложным. Сейчас для этого нужно пройти хоррор-квест:- Установить приложение.
- Завести аккаунт.
- В Skype взять один ключ.
- В «Битрикс 24» — другой.
- Подключить.
Viber
Эту интеграцию мы делали одной из первых. Постоянно общались с разработчиками мессенджера. И вообще держали руку «на пульсе». Сейчас «Открытые линии» можно подключить из «Битрикс24» или из мобильного приложения Viber.Telegram
У Telegram простое API — подключение получилось простым. И несмотря на все блокировки, сейчас все работает.Нам приходится самостоятельно раз в 15 минут «опрашивать» его и определять новые сообщения. Причём API разрешает получать не сами сообщения, а только комментарии к постам. Также есть ограничение на количество ответов в час.
Внешние системы — это живые организмы, в которых постоянно что-то меняется. В API соцсетей и мессенджеров вносятся какие-то изменения, часто возникают какие-то ошибки с «той» стороны.
Пример. Во ВКонтакте сломалась кодировка в названиях товаров, эту проблему они решали в течение года. Instagram просто никого не предупредил об отключении ряда функций API — мы постфактум узнали о том, что какие-то возможности перестали работать. Нам пришлось искать решения в авральном режиме.
После успешной интеграции соцсети или мессенджера расслабляться нельзя. Нам постоянно приходится отслеживать корректность обработки входящих сообщений.
Сервер коннекторов
В основе архитектуры «Открытых линий» лежит сервер коннекторов. Это единая точка входа в схеме обмена сообщениями между внутренним мессенджером «Битрикс24» и внешними мессенджерами и соцсетями.В «Открытых линиях» существует три вида входящих каналов:
- Внешние, которые работают через сервер очередей.
- Онлайн-чат, который работает на клиентском портале. Код виджета мы берём с портала клиента. И речи о недоставке сообщений в данном случае не идёт — если портал «лежит», виджет чата просто не будет отображаться.
- Нетворк — канал, который позволяет создавать «Открытую линию» и находить среди других порталов «Битрикс24», в том числе коробочных. Это особенно актуально для наших партнеров, которые хотят организовывать чаты поддержки для своих компаний-клиентов. Такие чаты работают через бот-платформы «Битрикс24» и не используют сервер коннекторов — все операции происходят внутри нашей платформы.
Сервер находится в облаке и доступен 24/7. Он принимает сообщения пользователей без праздников и выходных. У клиента с коробочной версией «Битрикс24» портал может быть временно недоступен: упал сервер или проблемы с интернетом. В таких случаях сообщения от пользователей могли теряться.
Эту проблему решает облачный сервер коннекторов.
Во-первых, он маршрутизирует сообщения непосредственно порталам-адресатам. Если какой-то портал недоступен, сервер коннекторов в течение суток накапливает сообщения для этого портала. И пытается доставить их на портал.
Мы посчитали — 24 часов достаточно, чтобы исправить любые неполадки и перезапустить портал коробочной версии. Мы сделали сильный акцент на том, что порядок сообщений не поменяется. Весь контент будет доставлен именно в том порядке, в котором его писали. Пользовательские сообщения, пусть и с задержкой, но будут доставлены.
У всех внешних систем свои форматы сообщений, со своими наборами данных. Где-то можно обмениваться эмодзи, картинками и прочими файлами. А где-то доступен лишь текст с очень ограниченным набором возможностей.
Сервер коннекторов:
- Приводит все входящие сообщения к универсальному формату, который понимают порталы.
- Шифрует данные и подписывает их лицензионным ключом.
- Передаёт их на порталы.
После унификации формата сообщения попадают в очередь. Из нее они разлетаются по адресатам.
Соцсети могут генерировать сообщения с внушительной частотой, но не все клиентские порталы могут похвастаться мощным «железом». На той же машине могут параллельно выполняться другие задачи.
И если сообщения будут идти «валом» — есть вероятность дублирования сессий. Чтобы этого не происходило, сообщения передаются каждому порталу в один поток, пакетами и с небольшой задержкой.
Сейчас очередь крутится на сервере коннекторов, но у нас уже готов отдельный масштабируемый сервер. Он поддерживает очереди разных типов:
- Параллельная в несколько потоков.
- Последовательная в один поток.
- Гарантированная. Много попыток.
- Негарантированная. Одна попытка.
Настройка и обработка сообщений
Мы постарались сделать подключение и настройку «Открытых линий» как можно проще.«Битрикс24» используют самые разные компании, от крупных представителей IT-бизнеса до индивидуальных предпринимателей, торгующих автозапчастями. Даже айтишнику, занимающемуся администрированием, проще сделать несколько кликов. А не изучать документацию, прописывать ключи и конфиги.
В «Открытых линиях» есть ряд настроек очереди операторов, рабочего времени, работы с CRM, различных чат-трекеров и форм.
Система учитывает, начался ли рабочий день у конкретного оператора, находится ли он онлайн или офлайн, и ряд других параметров.
Для обработки сообщений операторы используют либо приложение «Битрикс24», либо встроенный мессенджер. Там есть дополнительные инструменты управления: принять, пропустить, отклонить, завершить.
После завершения переписки с пользователем система может автоматически попросить его поставить оценку.
habr.com
Архитектура Битрикс24 — взгляд изнутри / Блог компании 1С-Битрикс / Хабр
12 апреля мы запустили большой новый проект — «Битрикс24»: социальный интранет, SaaS-сервис, объединяющий в себе классические инструменты командной работы (календари, задачи, CRM, работа с документами) и социальные коммуникации («лайки», социальный поиск, мгновенные сообщения и многое другое).
Первый прототип этого сервиса был запущен еще в феврале прошлого года. На одном сервере, без каких-либо особенных возможностей для масштабирования, без резервирования на уровне датацентра… :) Только концепт.
Этой публикацией мы откроем серию постов, в которых хотели бы рассказать вам, что было сделано за год разработки, какой получилась итоговая архитектура проекта; что мы делаем для того, чтобы обеспечить настоящие «24» часа работы проекта в сутки; какие изменения пришлось сделать в платформе разработки «1С-Битрикс»; особенности работы в облаке Amazon и многое другое.
Очень хотим, чтобы наш опыт оказался полезен для всех разработчиков, которые только планируют запускать или уже эксплуатируют и поддерживают крупные веб-проекты и сервисы.
* * *
Итак, первый пост — об архитектуре проекта в целом. Поехали! В процессе разработки самой идеи «Битрикс24» мы сформулировали для себя несколько бизнес-задач:
- С самого начала мы предполагали, что первый тариф на «Битрикс24» будет бесплатным.
- Это значит, что себестоимость такого бесплатного аккаунта для нас должна быть очень низкой.
- Наш проект — это бизнес-приложение, и значит нагрузка на него будет очень неравномерной: больше днем, меньше ночью. В идеале — хорошо бы уметь масштабироваться (в обе стороны) и в каждый момент времени использовать ровно столько ресурсов, сколько нужно.
- При этом — для любого бизнес-приложения крайне важна надежность: постоянная доступность данных и их сохранность.
- Мы стартовали сразу на нескольких рынках: Россия, США, Германия.
Эти бизнес-требования в итоге сформировали два больших «фронта» работ: формирование масштабируемой отказоустойчивой (забегая немного вперед — «облачной») платформы разработки и выбор технологической платформы для инфраструктуры проекта.
Платформа разработки «1С-Битрикс»
Традиционное устройство веб-приложений очень плохо масштабируется и резервируется. В лучшем случае — мы можем разнести по разным серверам само приложение, кэш и базу. Можем как-то масштабировать веб (но при этом должны будем решить вопрос синхронизации данных на веб-серверах). Кэш и база масштабируются уже хуже. А о распределенном гео-кластере (для резервирования на уровне датацентров) речь вообще не идет.
Огромным шагом в развитии платформы «1С-Битрикс» стало появление модуля «Веб-кластер» в версии 10.0 весной прошлого года.
Мы подробно писали о нем на Хабре. Кратко повторю основные возможности:
- Вертикальный шардинг (вынесение отдельных модулей на отдельные серверы MySQL)
- Репликация MySQL и балансирование нагрузки между серверами на уровне ядра платформы
- Распределенный кеш данных (memcached)
- Непрерывность сессий между веб-серверами (хранение сессий в базе данных)
- Кластеризация веб-сервера
В итоге мы получили возможность представить наш проект в виде веб-кластера взаимозаменяемых серверов. Все выглядело очень и очень неплохо: при увеличении посещаемости можно было быстро добавить в кластер новые серверы; в случае выхода из строя одного или нескольких серверов кластера все продолжало работать на оставшихся серверах, система продолжала беспрерывно обслуживать клиентов.
Но до идеала было еще далеко, оставались «узкие» места:
- Не был до конца решен вопрос синхронизации файлов на разных веб-серверах. На собственном сайте мы использовали csync2, он очень неплохо себя зарекомендовал. Однако на больших объемах данных мы просто не успевали бы передавать изменения по всем серверам.
- Выход из строя master-сервера в репликации MySQL означал какие-то ручные или полуавтоматические операции по переводу одного из slave'ов в режим master'а. Это требовало времени, а значит мы не могли гарантировать бесперебойную работу сервиса.
- slave'ы позволяют распределить нагрузку на базу на чтение, а master все равно остается один. Это значит, что запись остается узким местом в работе базы.
- Как показал наш собственный печальный опыт, молнии попадают в датаценты и могут их полностью вывести из строя. Значит, нужно резервировать не только отдельные серверы, но и целиком датацентр.
В платформе «1С-Битрикс» версии 11.0, вышедшей осенью 2011 года, мы решили и эти задачи. Поддержка облачных файловых хранилищ решила проблему синхронизации статического контента, а реализация поддержки master-master репликации в MySQL позволила строить географически распределенные веб-кластеры.
И мы вплотную подошли ко второй большой задаче…
Платформа для разворачивания инфраструктуры
Если честно, выбор был не очень сложным. :)
«Облако» или не «облако» — такой вопрос даже не стоял. :)
Собственное или арендуемое оборудование требует достаточно серьезных вложений в инфраструктуру на старте проекта. Масштабировать физические «железки» достаточно сложно (долго и дорого). Администрировать (особенно в разных ДЦ) — неудобно.
Поэтому — «облако»!
Какое именно? Мы выбрали Amazon AWS.
Все наши сайты работают в Амазоне достаточно давно. Нам нравится то, что есть множество уже готовых сервисов, которые можно просто брать и использовать в своем проекте, а не изобретать собственные велосипеды: облачное хранилище S3, Elastic Load Balancing, CloudWatch, AutoScaling и многое другое.
В очень упрощенном виде вся архитектура «Битрикс24» выглядит примерно так:
Web – автоматическое масштабирование
Приложение (веб) масштабируется у нас не вертикально (увеличение мощности сервера), а горизонтально (добавляем новые машины).
Для этого мы используем связку Elastic Load Balancing + CloudWatch + Auto Scaling. Все клиентские запросы (HTTP и HTTPS) поступают на один или несколько балансировщиков Amazon (ELB). Рост и снижение нагрузки мониторим через CloudWatch. Есть две интересные метрики – состояние нод EC2 (% CPU Utilization) и балансировщика (время latency – в секундах).
Мы в качестве основной характеристики используем данные о загрузке машин, так как latency может варьироваться не только из-за реальной нагрузки, но и по каким-то иным причинам: сетевые задержки, ошибки в приложении и т.п. В таком случае возможны «ложные» срабатывания, и тогда мы крайне неэффективно будем добавлять новые машины.
Сейчас в итоге автоматически стартуют новые машины, если средняя утилизация CPU (в терминах Амазона) превышает 60%, и автоматически останавливаются и выводятся из эксплуатации, если средняя нагрузка менее 30%.
Мы достаточно долго экспериментировали с этими пороговыми значениями и сейчас считаем их оптимальными. Если верхний порог ставить больше (например, 70-80%), то начинается общая деградация системы – пользователям работать некомфортно (долго загружаются страницы). Нижний порог меньше — система балансировки становится не очень эффективной, машины долго могут работать вхолостую.
Статический контент пользователей сервиса
В описанной выше схеме веб-ноды по сути становятся «расходным материалом». Они могут в любой момент стартовать и в любой момент гаситься. А это значит, что никакого пользовательского контента на них быть не должно.
Именно поэтому при создании каждого нового портала в «Битрикс24» для него создается персональный аккаунт в Амазоне для хранение данных в S3. Тем самым данные каждого портала полностью изолированы друг от друга.
При этом само хранилище S3 очень надежно. Сам Амазон подробно описывает его устройство (и, в принципе, нет поводов им не верить).
Данные в S3 реплицируются в несколько точек. При этом – в территориально распределенные точки (разные датацентры).
Каждое из устройств хранилища мониторится и быстро заменяется в случае тех или иных сбоев.
Когда вы загружаете новые файлы в хранилище, ответ об успешной загрузке вы получите только тогда, когда файл будет полностью сохранен в нескольких разных точках.
Обычно данные реплицируются в три и более устройств – для обеспечения отказоустойчивости даже в случае выхода из строя двух из них.
Иными словами, с надежностью – все хорошо. Тот же Амазон, например, говорит о том, что их архитектура S3 устроена таким образом, что они готовы обеспечить доступность на уровне двух девяток после запятой. А вероятность потери данных – одна миллиардная процента.
Два датацентра и master-master репликация
Весь проект сейчас размещается в двух датацентрах. Мы решаем этим сразу две задачи: во-первых, распределяем нагрузку (сейчас российские пользователи работают в одном ДЦ, а американские и европейские — в другом), а во-вторых, резервируем все сервисы — в случае выхода из строя одного из ДЦ, мы просто переключаем траффик на другой.
Чуть-чуть подробнее — как это все устроено.
База в каждом ДЦ является мастером относительно слейва во втором ДЦ и одновременно слейвом — относительно мастера.
Важные настройки в MySQL для реализации этого механизма — auto_increment_increment и auto_increment_offset. Они задают смещения значений для полей auto_increment — для того, чтобы избежать дублирования записей. Грубо говоря, в одном мастере — только четные ID, в другом — только нечетные.
Каждый портал (все зарегистрированные в нем сотрудники), заведенный в «Битрикс24» в каждый конкретный момент времени работает только с одним ДЦ и одной базой. Переключение на другой ДЦ осуществляется только в случае какого-либо сбоя.
Базы в разных датацентрах синхронны, но при этом независимы друг от друга: потеря связности между датацентрами может составлять часы, данные синхронизируются после восстановления.
Надежность, надежность, надежность
Один из важнейших приоритетов в «Битрикс24» – постоянная доступность сервиса и его отказоустойчивость.
Помните простую схему сервиса? В итоге (все равно упрощенно, но тем не менее :)) она выглядит примерно так:
В случае аварии на одной или нескольких веб-нодах Load Balancing определяет вышедшие из строя машины и, исходя из заданных параметров группы балансировки (минимально необходимое количество запущенных машин), автоматически восстанавливается нужное количество инстансов.
Если теряется связность между датацентрами, то каждый датацентр продолжает обслуживать свой сегмент клиентов. После восстановления коннективити, данные в базах автоматически синхронизируются.
Если же выходит из строя полностью датацентр, или же, например, происходит сбой на базе, то весь траффик автоматически переключается в работающий датацентр.
Если это вызывает повышенную нагрузку на машины, то CloudWatch определяет возросшую утилизацию CPU и добавляет нужное количество машин уже в одном датацентре в соответствие с правилами для AutoScaling.
При этом у нас приостанавливается мастер-мастер репликация. После проведения нужных работ (восстановительных — в случае аварии, или плановых — мы, например, точно по такой же схеме в какой-то момент осуществили переход со стандартного MySQL на Percona Server — при этом без какого-либо downtime'а для пользователей сервиса), включаем базу в работу и восстанавливаем репликацию.
Если все прошло штатно, траффик снова распределяется на оба датацентра. Если при этом средняя нагрузка стала ниже порогового значения, то лишние машины, которые мы поднимали для обслуживания возросшей нагрузки, автоматически гасятся.
* * *
Этот первый пост я постарался сделать «легким», обзорным. :) Если бы вместил все то, чем хочется поделиться, в один текст и рассказал обо всем нашем опыте сразу, то получилось бы слишком много букв. :)
Мне кажется более логичным сделать серию тематических постов. Темы которые, мы уже готовим:
- Нюансы Амазона: неочевидные лимиты, разные режимы работы балансировщиков, работа с образами AMI
- Специфика веб-нод: механизмы обновления ПО, Apache/не Apache, безопасность и изоляция пользователей
- MySQL: почему Percona, особенности master-master, репликация большого объема данных, нюансы работы query cache, шардинг
- Бэкапы данных и главное — их восстановление
- Мониторинг тысяч объектов, как не заспамить себя алертами, автоматизируем реакцию на уведомления
Что наиболее интересно для вас? Можно провести спонтанное голосование и отмечать прямо в комментариях. :)
Ну и конечно — пробуйте сам «Битрикс24»! Первый тариф — бесплатный. Если его лимитов или функционала не хватит — можно будет перейти на старшие тарифы. :)
Подключайтесь — и работайте с удовольствием!
habr.com
подводные камни и непростые решения / Блог компании 1С-Битрикс / Хабр
Эта публикация написана по материалам выступления AlexSerbul на осенней конференции BigData Conference.Большие данные — тема модная и востребованная. Но многих по-прежнему отпугивает избыток теоретических рассуждений и некоторый недостаток практических рекомендаций. В этом посте я хочу отчасти заполнить этот пробел и рассказать об использовании параллельных алгоритмов для обработки больших данных на примере кластеризации товарного каталога из 10 млн позиций. К сожалению, когда у вас много данных, то придётся «изобретать» классический алгоритм заново, чтобы он работал параллельно с помощью MapReduce. И это — большая проблема.
Какой есть выход? Ради экономии времени и денег можно конечно попытаться найти библиотеку, которая позволит реализовать алгоритм параллельной кластеризации. На Java-платформе что-то конечно есть: умирающий Apache Mahout и развивающийся Apache Spark MLlib. К сожалению, Mahout поддерживает мало алгоритмов под MapReduce — большинство из них последовательны.
Обещающий горы Spark MLlib пока тоже не богат на алгоритмы кластеризации. А с нашими объёмами дело еще хуже — вот что предлагается:
- K-means
- Gaussian mixture
- Power iteration clustering (PIC)
- Latent Dirichlet allocation (LDA)
- Streaming k-means
Итак, нам нужно кластеризовать каталог из 10 млн товарных позиций. Зачем это нужно? Дело в том, что наши пользователи могут использовать в своих интернет-магазинах рекомендательную систему. А её работа основана на анализе агрегированного каталога товаров всех сайтов, работающих на нашей платформе. Допустим, в одном из магазинов покупателю порекомендовали выбрать топор, чтобы тёщу зарубить (да, это корпоративный блог, но без шуток про бигдату и математику говорить просто нельзя — все заснут). Система об этом узнает, проанализирует и в другом магазине порекомендует тому же покупателю баян, чтобы он играл и радовался. То есть первая задача, решаемая с помощью кластеризации, — передача интереса.
Вторая задача: обеспечить создание корректных логических связей товаров для увеличения сопутствующих продаж. Например, если пользователь купил фотоаппарат, то система порекомендует к нему аккумулятор и карту памяти. То есть нам нужно собрать в кластеры похожие товары, и в разных магазинах работать уже на уровне кластеров.
Как было отмечено выше, наша база товаров состоит из каталогов нескольких десятков тысяч интернет-магазинов, работающих на платформе «1С-Битрикс». Пользователи вводят туда текстовые описания разной длины, кто-то добавляет марки товаров, модели, производителей. Составить непротиворечивую точную единую систему сбора и классификации всех товаров из десятка тысяч магазинов было бы дорого, долго и тяжело. А мы хотели найти способ, как быстро склеить похожие товары между собой и заметно повысить качество коллаборативной фильтрации. Ведь если система хорошо знает покупателя, то неважно, какими конкретными товарами и их марками он интересуется, система всегда найдёт, что ему предложить.
Выбор инструментария
В первую очередь необходимо было выбрать систему хранения, подходящую для работы с «большими» данными. Я немного повторюсь, но это полезно для закрепления материала. Для себя мы выделили четыре «лагеря» баз данных:- SQL на MapReduce: Hive, Pig, Spark SQL. Загрузите в РСУБД один миллиард строк и выполните агрегацию данных — станет понятно, что этот класс систем хранения «не очень» подходит для данной задачи. Поэтому, интуитивно, можно попробовать использовать SQL через MapReduce (что и сделал когда-то Facebook). Очевидные минусы тут — скорость выполнения коротких запросов.
- SQL на MPP (massive parallel processing): Impala, Presto, Amazon RedShift, Vertica. Представители этого лагеря утверждают, что SQL через MapReduce – это тупиковый путь, поэтому нужно, фактически, на каждой ноде, где хранятся данные, поднимать драйвер, который будет быстро обращаться к этим данным. Но многие из перечисленных систем страдают от нестабильности.
- NoSQL: Cassandra, HBase, Amazon DynamoDB. Третий лагерь говорит: BigData — это NoSQL. Но мы же понимаем, что NoSQL — это, фактически, набор «memcached-серверов», объединённых в кольцевую структуру, которые могут быстро выполнить запрос типа «взять по ключу значение и вернуть ответ». Ещё могут вернуть отсортированный в оперативной памяти по ключу набор данных. Это почти всё — забудьте про JOINS.
- Классика: MySQL, MS SQL, Oracle и т.д. Монстры не сдаются и утверждают, что всё вышеперечисленное — фигня, горе от ума, и реляционные базы прекрасно работают с BigData. Кто-то предлагает фрактальные деревья (https://en.wikipedia.org/wiki/TokuDB), кто-то — кластеры. Монстры ведь тоже жить хотят.
- Spark MLlib (Scala/Java/Python/R) — когда много данных.
- scikit-learn.org (Python) — когда мало данных.
- R — вызывает противоречивые чувства по причине жуткой кривизны реализации (доверь программирование математикам и статистам), но готовых решений много, а недавняя интеграция со Spark очень радует.
В итоге мы остановились на SparkMLlib, поскольку там, как показалось, есть надежные параллельные алгоритмы кластеризации.
Поиск алгоритма кластеризации
Нам нужно было сначала придумать, каким образом объединять в кластроиды текстовые описания товаров (названия и краткие описания). Обработка текстов на естественных языках — это отдельная огромная область Computer Science, включающая в себя и машинное обучение и Information retrieval и лингвистику и даже (тадам!) Deep Learning.Когда данных для кластеризации десятки, сотни, тысячи — подойдет практически любой классический алгоритм, даже иерархической кластеризации. Проблема в том, что алгоритмическая сложность иерархической кластеризации равна примерно O(N3). То есть надо ждать «миллиарды лет», пока он отработает на нашем объёме данных, на огромном кластере. А ограничиваться обработкой лишь какой-то выборки было нельзя. Поэтому иерархическая кластеризация в лоб нам не подошла.
Потом мы обратились к «бородатому» алгоритму K-means:
Это очень простой, хорошо изученный и распространённый алгоритм. Однако и он работает на больших данных очень медленно: алгоритмическая сложность равна примерно О(nkdi). При n = 10 000 000 (количество товаров), k = 1 000 000 (ожидаемое количество кластеров), d = <1 000 000 (видов слов, размерность вектора), i = 100 (примерное количество итераций), О = 1021 операций. Для сравнения, возраст Земли составляет 1,4*1017 секунд.
Алгоритм C-means хоть и позволяет сделать нечёткую кластеризацию, но тоже работает на наших объёмах медленно, как и спектральная факторизация. По этой же причине нам не подошли DBSCAN и вероятностные модели.
Чтобы осуществить кластеризацию, мы решили на первом этапе превратить текст в векторы. Вектор — это некая точка в многомерном пространстве, скопления которых и будут искомыми кластерами.
Нам нужно было кластеризовать описания товаров, состоящие из 2-10 слов. Самое простое, классическое решение в лоб или в глаз — bag of words. Раз у нас есть каталог, то мы можем определить и словарь. В результате, у нас получился корпус размером примерно миллион слов. После стемминга их осталось около 500 тыс. Отбросили высокочастотные и низкочастотные слова. Конечно, можно было использовать tf/idf, но решили не усложнять.
Какие есть недостатки у этого подхода? Получившийся огромный вектор дорого потом обсчитывать, сравнивая его похожесть с другими. Ведь что представляет собой кластеризация? Это процесс поиска схожих между собой векторов. А когда они размером по 500 тыс., поиск занимает очень много времени, поэтому надо научиться их сжимать. Для этого можно использовать Kernel hack, хэшируя слова не в 500 тыс. атрибутов, а в 100 тыс. Хороший, рабочий инструмент, но могут возникать коллизии. Мы его не стали использовать.
И напоследок расскажу ещё об одной технологии, которую мы отбросили, но сейчас всерьёз подумываем начать её использовать. Это Word2Vec, методика статистической обработки текста путем сжатия размерности текстовых векторов двуслойной нейронной сетью, разработанная в Google. По сути, это развитие старых добрых вечных статистических N-gram моделей текста, только используется skip-gram вариация.
Первая задача, которая красиво решается с помощью Word2Vec: уменьшение размерности за счёт «матричной факторизации» (в кавычках специально, т.к. никаких матриц там нет, но эффект очень похож). То есть, получается, например, не 500 тыс. атрибутов, а всего лишь 100. Когда встречаются похожие «по контексту» слова, система считает их «синонимами» (с натяжкой конечно, кофе и чай могут объединиться). Получается, что точки этих похожих слов в многомерном пространстве начинают совпадать, то есть близкие по значению слова кластеризуются в общее облако. Скажем, «кофе» и «чай» будут близкими по значению словами, ведь они часто встречаются в контексте вместе. Благодаря библиотеке Word2Wec можно уменьшить размер векторов, а сами они получаются более осмысленными.
Этой теме много лет: Latent semantic indexing и её вариации через PCA/SVD изучили хорошо, да и решение в лоб через кластеризацию колонок или строк матрицы term2document, по сути, даст похожий результат — только делать это придётся очень долго.
Весьма вероятно, что мы всё же начнём применять Word2Vec. К слову, её использование также позволяет находить опечатки и играться с векторной алгеброй предложений и слов.
«Я построю свой лунапарк!..»
В итоге, после всех долгих поисков по научным публикациям, мы написали свой вариант k-Means — Clustering by Bootstrap Averaging для Spark.По сути, это иерархический k-Means, делающий предварительный послойный сэмплинг данных. На обработку 10 млн товаров ушло достаточно разумное время, часы, хотя и потребовалось задействовать кучу серверов. Но результат не устроил, т.к. часть текстовых данных кластеризовать не удалось — носки клеились с самолетами. Метод работал, но очень грубо и неточно.
Оставалась надежда на старые, но подзабытые сейчас вероятностные методики поиска дубликатов или «почти дубликатов» — locality-sensitive hashing.
Вариант метода, описанный тут , требовал использования преобразованных из текста векторов одинакового размера, для дальнейшего «раскидывания» их по хэш-функциям. И мы взяли MinHash.
MinHash — технология сжатия векторов большой размерности в маленький вектор с сохранением из взаимной Jaccard-похожести. Как она работает? У нас есть некоторое количество векторов или наборов множеств, и мы определяем набор хэш-функций, через которые прогоняем каждый вектор/множество.
Определяем, например, 50 хэш-функций. Потом каждую хэш-функцию прогоняем по вектору/множеству, определяем минимальное значение хэш-функции, и получаем число, которое записываем в N-позицию нового сжатого вектора. Делаем это 50 раз.
Pr[ hmin(A) = hmin(B) ] = J(A, B)
Таким образом мы решили задачу сжатия измерений и приведения векторов к единому количеству измерений.
Text shingling
Я совсем забыл рассказать, что мы отказались от векторизации текстов в лоб, т.к. названия и краткие описания товаров создавали чрезвычайно разряженные вектора, страдающие от «проклятья размерности».Названия товаров обычно были примерно такого вида и размера:«Штаны красные махровые в полоску» «Красные полосатые штаны»
Эти две фразы разнятся по набору слов, по их количеству и местоположению. Кроме того, люди делают опечатки при наборе текста. Поэтому сравнивать слова нельзя даже после стемминга, ведь все тексты будут математически непохожи, хотя по смыслу они близки.
В подобной ситуации часто используется алгоритм шинглов (shingle, чешуйки, черепица). Мы представляем текст в виде шинглов, кусков.
{«штан», «таны», «аны », «ны к», «ы кра», «крас», …}
И при сравнении множества кусочков выясняется, что два текста разных текста могут вдруг обрести схожесть друг с другом. Мы долго экспериментировали с обработкой текста, и по нашему опыту, только так и можно сравнивать короткие текстовые описания в нашем товарном каталоге. Этот способ используется и для определения похожих статей, научных работ, с целью обнаружения плагиата.
Повторюсь ещё раз: мы отказались от сильно разреженных текстовых векторов, заменили каждый текст на множество (set) шинглов, а затем привели их к единому размеру с помощью MinHash.
Векторизация
В результате мы решили задачу векторизации каталога следующим образом. С помощью MinHash-сигнатуры получили векторы небольшого размера от 100 до 500 (размер выбирается одинаковым для всех векторов). Теперь их нужно сравнить каждый с каждым, чтобы сформировать кластеры. В лоб, как мы уже знаем, это очень долго. А благодаря алгоритму LSH (Locality-Sensitive Hashing) задача решилась в один проход.Идея в том, что похожие объекты, тексты, векторы коллизируют в один набор хэш-фукций, в один bucket. И потом остаётся пройти по ним и собрать похожие элементы. После кластеризации получается миллион bucket’ов, каждый из которых и будет кластером.
Кластеризация
Традиционно используют несколько bands — наборов хэш-функций. Но мы ещё больше упростили задачу — оставили всего один band. Допустим, берутся первые 40 элементов вектора и заносятся в хэш-таблицу. А дальше туда попадают элементы, которые имеют такой же кусок сначала. Вот и всё! Для начала — прекрасно. Если нужна большая точность, то можно работать с группой bands, но тогда на финальной части алгоритма придётся дольше собирать из них взаимно похожие объекты.После первой же итерации мы получили неплохие результаты: у нас склеились почти все дубли и почти все похожие товары. Оценивали визуально. А для дальнейшего уменьшения количества микрокластеров мы предварительно убрали часто встречающиеся и редко встречающиеся слова.
Теперь у нас всего за два-три часа на 8 spot-серверах кластеризуется 10 млн. товаров в примерно один миллион кластеров. Фактически, в один проход, потому что band лишь один. Поэкспериментировав с настройками, мы получили достаточно адекватные кластеры: яхты, автомобили, колбаса и т.д., уже без глупостей вроде «топор + самолет». И теперь эта сжатая кластерная модель используется для улучшения точности работы системы персональных рекомендаций.
Итоги
В коллаборативных алгоритмах мы стали работать уже не с конкретными товарами, а с кластерами. Появился новый товар, мы нашли кластер, положили его туда. И обратный процесс — рекомендуем кластер, затем выбираем из него самый популярный товар и возвращаем его пользователю. Использование кластерного каталога в разы улучшило точность рекомендаций (измеряем recall текущей модели и за месяц ранее). И это всего лишь за счёт сжатия данных (названий) и объединения их по смыслу. Поэтому хочу посоветовать вам — ищите простые решения ваших задач, связанных с большими данными. Не пытайтесь что-то усложнять. Я верю в то, что всегда можно найти простое, эффективное решение, которое за 10% усилий решит 90% задач! Всем удачи и успехов в работе с большими данными!habr.com
11 «рецептов приготовления» MySQL в Битрикс24 / Блог компании 1С-Битрикс / Хабр
Проектируя, разрабатывая и запуская наш новый большой проект — «Битрикс24», мы не только хотели сделать по-настоящему классный сервис для командной работы (к тому же еще и бесплатный — до 12 пользователей), но еще и собрать и накопить опыт по эксплуатации облачных веб-сервисов, «прокачать» свою компетенцию в разработке высоконагруженных отказоустойчивых проектов и — самое главное — поделиться этими знаниями как с нашими партнерами, так и со всеми веб-разработчиками, кому близка тема «хайлоада». :)
Конечно, в одной статье (и даже не в одной) невозможно описать универсальный «рецепт», который бы подошел абсолютно для всех проектов: для кого-то важнее производительность (иногда — даже в ущерб надежности), для кого-то — наоборот, отказоустойчивость превыше всего, где-то много маленьких таблиц, где-то — большой объем данных…
Мы постарались описать те «изюминки», которые не раз помогали нам в работе в решении тех или иных практических задач. Надеемся, они окажутся полезными и для вас. :) Начнем по порядку.
Мы не раз уже говорили и писали о том, что «Битрикс24» развернут в Амазоне. И раз мы так любим и активно используем различные облачные сервисы, первый же вопрос…
1. Почему не используем RDS?
Amazon Relational Database Service (Amazon RDS) — облачная база данных. Есть поддержка MS SQL, Oracle и — что было интересно нам — MySQL.
Долго присматривались, хотели использовать в своем проекте… В итоге отказались от этой идеи. Несколько ключевых причин:
- Во-первых, система недостаточно гибкая и прозрачная. Например, вы не получаете полноценного root-доступа к базе. А это значит, что какие-то специфичные (конкретно для вашего проекта) настройки, возможно, не получится сделать.
- Есть риск долгого даунтайма в случае какой-либо аварии. И практика показывает, что риск этот вполне реален. Да, чаще страдают те базы, которые расположены только в одной зоне, и для обеспечения отказоустойчивости можно использовать так называемые Multi-AZ DB Instances. Но — о них далее...
- При использовании Multi-AZ DB Instances для базы постоянно пишется standby бэкап в другую AZ (Availability Zone), и в случае аварии в первой зоне происходит автоматическое переключение на другую. Но в этом случае один инстанс с базой стоит ровно в два раза дороже. При этом пользователь эффективно использует ресурсы только одной машины (в отличие от схемы с «мастер-мастер» репликацией, о которой мы недавно писали).
2. Master-Slave? Нет, Master-Master!
Стандартная схема репликации в MySQL «Master-Slave» давно и успешно применяется на многих проектах и решает несколько задач: масштабирование нагрузки (только на чтение) — перераспределение запросов (SELECT'ов) на слейвы, отказоустойчивость.
Но решает — не полностью.
1. Хочется масштабировать и запись. 2. Хочется иметь надежный failover и продолжать работу автоматически в случае каких-либо аварий (в master-slave в случае аварии на мастере нужно один из слейвов в ручном или полу-автоматическом режиме переключить в роль мастера).
Чтобы решить эти задачи, мы используем «мастер-мастер» репликацию. Не буду сейчас повторяться, этой технике у нас недавно был посвящен отдельный пост на Хабре.
3. MySQL? Нет, Percona Server!
Первые несколько месяцев (на прототипах, в процессе разработки, в начале закрытого бета-тестирования сервиса) мы работали на стандартном MySQL. И чем дольше работали, тем больше присматривались к различным форкам. Самими интересными, на наш взгляд, были Percona Server и MariaDB.
Выбрали мы в итоге Перкону — конечно, из-за похожего «перевернутого» логотипа. ;)
… и нескольких фич, которые оказались крайне важными для нас:
- Percona Server оптимизирован для работы с медленными дисками. И это очень актуально для «облака» — диски там почти всегда традиционно медленнее (к сожалению), чем обычные диски в «железном» сервере. Проблему неплохо решает организация софтверного рейда (мы используем RAID-10), но и оптимизация со стороны серверного ПО — только в плюс.
- Рестарт базы (при большом объеме данных) — дорогая долгая операция. В Перконе есть ряд фич, которые позволяют делать рестарт гораздо быстрее — Fast Shut-Down, Buffer Pool Pre-Load. Последняя позволяет сохранять состояние буфер-пула при рестарте и за счет этого получать «прогретую» базу сразу после старта (а не тратить на это долгие часы).
- Множество счетчиков и расширенных отчетов (по пользователям, по таблицам, расширенный вывод SHOW ENGINE INNODB STATUS и т.п.), что очень помогает находить, например, самых «грузящих» систему клиентов.
- XtraDB Storage Engine — обратно совместим со стандартным InnoDB, при этом гораздо лучше оптимизирован для хайлоад проектов.
Важный момент — переход со стандартного MySQL на Percona Server вообще не потребовал изменения какого-либо кода или логики приложения.
А, вот, сам процесс «переезда» был достаточно интересным. И благодаря использованию схемы с «мастер-мастер» репликацией, прошел совершенно незаметно для наших пользователей. Даунтайма просто не было.
Схема переезда была такой:
- «Нулевой» шаг — подняли тестовый стенд их снэпшота машины с базой с реальными данными. И на нем стали отлаживать конфигурацию для стабильной работы. Ну и, конечно, подбирать специфичные для Перконы опции в конфигурационном файле.
- Получив стабильную конфигурацию, переключили весь траффик на один ДЦ, а базу без нагрузки выключили из репликации.
- На этой базе осуществили переход на Percona Server.
- Включили базу в репликацию (стандартный MySQL и Percona Server совместимы).
- Дождались синхронизации данных.
- После этого проделали ту же процедуру со второй базой.
4. MyISAM? InnoDB?
Тут все просто.
- На долгих запросах в MyISAM лочится вся таблица. В InnoDB — только те строки, с которыми работаем. Соответственно, в InnoDB долгие запросы в меньшей степени влияют на другие запросы и не отражаются на работе пользователей.
- На больших объемах данных и при высокой нагрузке таблицы MyISAM «ломаются». Это — известный факт. В нашем сервисе это недопустимо.
- Ну, и раз уж у нас есть «улучшенный» InnoDB — XtraDB, конечно, мы будем использовать именно этот storage engine. :)
Переходим от архитектурных вопросов к более практическим. :)
5. Все ли данные нужно реплицировать? Нет, не все.
Почти в любом проекте есть некритичные для потери или восстанавливаемые данные. В том числе — и в базе данных.
В нашем случае такими данными были сессии. Что было плохого в том, что реплицировалось все подряд?
- В таблицах сессий наряду с SELECT'ами много операций записи (INSERT, UPDATE, DELETE). Это значит, что мы даем лишнюю нагрузку на slave базу. Ту нагрузку, которую можно избежать.
- Кроме того, при достаточно большом значении query_cache_size мы столкнулись с тем, что активная работа с этими таблицами и их участие в репликации приводят к тому, что многие треды «подвисают» в состоянии «waiting for query cache lock» (видно в SHOW PROCESSLIST). Далее это чревато повышенной нагрузкой на CPU и общей деградацией производительности.
Как исключать? Есть разные способы.
1. На уровне приложения в том коннекте, где идет работа с таблицами, которые мы хотим исключить из репликации, выполняем:
SET sql_log_bin = 0; 2. Более простой и понятный способ — указать исключение в конфигурационном файле MySQL.replicate-wild-ignore-table = %.b_sec_session Такая конструкция исключает из репликации таблицы b_sec_session во всех базах.Все немножко более сложно в том случае, если вам нужна более сложная логика. Например, не реплицировать таблицы table во всех базах, кроме базы db.
В таком случае вам придется немного порисовать схемки наподобие тех, которые дает MySQL, чтобы составить правильную комбинацию опций — фильтров.
6. Тип репликации.Много споров вызывает вопрос, использовать ли STATEMENT-based или ROW-based репликацию. И тот, и другой вариант обладают и плюсами, и минусами.
По умолчанию в MySQL (Percona) 5.5 используется STATEMENT-based репликация.
На нашем приложении в такой конфигурации мы регулярно видели в логах строки: «Statement may not be safe to log in statement format».
Кроме того, сравнение двух баз в мастер-мастер репликации показывало, что могут появляться расхождения в данных. Это, конечно, было недопустимо.
В MySQL есть интересное решение, которое нас полностью устроило — использовать MIXED формат бинлога:
binlog-format = mixed В этом случае по умолчанию репликация идет в режиме STATEMENT и переключается в ROW как раз в случае таких небезопасных операций.7. Репликация сломалась. Что делать?
Репликация иногда все-таки ломается. Особенно страшно (поначалу :)) это звучит при работе с «мастер-мастер».
На самом деле, ничего страшного нет. Правда. :)
В первую очередь нужно помнить о том, что описанная схема «мастер-мастер» репликации — это на самом деле просто две обычные «master-slave» репликации. Да, с некоторыми нюансами, но большинство практик, используемых в стандартной схеме, работают и здесь.
Самая простая (и самая часто случающаяся) проблема — ошибка вида «1062 Error 'Duplicate entry'».
Причины могут быть разными. Например, мы в случае какой-либо аварии с базой переключаем траффик на другой ДЦ. Если запрос уже был выполнен в ДЦ 1, но не успел среплицироваться в ДЦ 2 и был выполнен там повторно — да, получим именно такую ошибку.
Лечится выполнением вот таких команд на слейве:
STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; START SLAVE; Тем самым пропускаем лишний запрос. Далее смотрим состояние репликации:SHOW SLAVE STATUS\G Если требуется, повторяем процедуру.* * *
Да, мы сейчас детально рассматриваем самый простой вариант. Все бывает значительно хуже — рассыпается файловая система, бьются файлы и т.п.
Универсального рецепта «как все починить» нет. Но всегда важно помнить следующее:
- Не паниковать.
- Видеть состояние слейва с помощью SHOW SLAVE STATUS\G.
- Видеть состояние мастера с помощью SHOW MASTER STATUS.
- Всегда вести лог (log-error = /var/log/mysqld.log) — в нем очень много полезной информации. Например, данные о том, до какой позиции слейв дочитал бинлог мастера. Очень помогает при авариях.
- Если все совсем сломалось — подниматься из бэкапа.
Что же делать, если в схеме с двумя мастерами все-таки что-то пошло не так (например, во время аварии в Амазоне несколько дней назад у нас необратимо повредились файловые системы на нескольких серверах)?
Решение «в лоб» — перелить данные из одного сервера на другой и запустить репликацию с нуля — слишком долго.
В Амазоне мы используем механизмы снэпшотов дисков и создание образов (AMI) целых машин. Это позволяет очень быстро развернуть полную копию нужного сервера — например, по состоянию на несколько часов назад.
Если мы просто развернем машину из бэкапа, мы получим интересный эффект: мы начнем читать данные из бинлогов «живого» мастера (с момента, когда создавался бэкап), но прочитаем лишь половину их, так как по умолчанию записи с сервера с тем же server-id (из «будущего» относительно времени бэкапа) реплицироваться не будут. Это делается для того, чтобы избежать «зацикливаний» в «мастер-мастер».
Поступаем так:
1. Весь траффик идет на «живой» ДЦ. На тот сервер, который мы восстанавливаем нагрузки нет. 2. На сервере, поднятом из бэкапа, сразу останавливаем mysqld и вписываем в конфиг:
skip-slave-start replicate-same-server-id #log-slave-updates = 1 ; комментируем! 3. Запускаем mysqld и стартуем репликацию. 4. После того, как данные синхронизированы, возвращаем конфиг в исходное состояние:#skip-slave-start #replicate-same-server-id log-slave-updates = 1 5. Так как у нас — «мастер-мастер», нам нужно запустить репликацию и в обратную сторону. Останавливаем репликацию на том сервере, который мы восстанавливали, и выполняем:SHOW MASTER STATUS; Если репликацию не остановим, данные будут меняться. 6. Стартуем с нужной позиции репликацию на первом (живом) сервере:STOP SLAVE; CHANGE MASTER TO MASTER_LOG_FILE='...', MASTER_LOG_POS = ...; START SLAVE; Вписываем данные, полученные в пункте 5. 7. Стартуем репликацию и на втором сервере.9. Где баланс между производительностью и надежностью репликации?
Есть много опций в MySQL / Percona, которые позволяют кардинально повысить надежность и сохранность данных в случае, например, внезапных ребутов. Практически все они столь же кардинально снижают быстродействие системы.
Мы для себя нашли баланс в такой комбинации опций:
sync_binlog = 1 sync_master_info = 0 sync_relay_log = 0 sync_relay_log_info = 0 innodb-flush-log-at-trx-commit = 2 Бинлог для нас критически важен, поэтому sync_binlog = 1. Но при этом бинлоги хранятся на отдельном диске в системе, поэтому запись на этот диск не снижает производительность системы в целом.10. Как вообще оценивать производительность системы?
Если у нас есть большие «тяжелые» запросы, то, конечно, мы банально ориентируемся на время их выполнения.
Чаще же (и в нашем случае — именно так) система обрабатывает много-много мелких запросов.
Конечно, можно использовать различные синтетические тесты для оценки производительности системы. И некоторую оценку они дадут. Но ведь хочется иметь какие-то реальные показатели (желательно — в цифрах :)), которые можно было бы применять «в бою».
В Percona Server есть замечательный инструмент:
SELECT * FROM INFORMATION_SCHEMA.QUERY_RESPONSE_TIME;+----------------+-------+----------------+ | time | count | total | +----------------+-------+----------------+ | 0.000001 | 0 | 0.000000 | | 0.000010 | 6555 | 0.024024 | | 0.000100 | 56132 | 2.326873 | | 0.001000 | 23165 | 6.686421 | | 0.010000 | 9755 | 39.737027 | | 0.100000 | 1437 | 40.831493 | | 1.000000 | 141 | 31.785571 | | 10.000000 | 9 | 17.891514 | | 100.000000 | 0 | 0.000000 | | 1000.000000 | 0 | 0.000000 | | 10000.000000 | 0 | 0.000000 | | 100000.000000 | 0 | 0.000000 | | 1000000.000000 | 0 | 0.000000 | | TOO LONG | 0 | TOO LONG | +----------------+-------+----------------+ 14 rows in set (0.00 sec) Такая гистограмма распределения времени выполнения запросов очень хорошо помогает оценивать общее состояние системы.Например, мы для себя определили некий критический порог — не более 5% запросов (от общего числа) с временем выполнения более 0.01 сек.
Чтобы отслеживать это состояние в динамике, написали простой плагин к Munin'у, который как раз и рисует график по данному соотношению. Очень удобно, и — главное — это живая понятная метрика.
11. Сбалансированность по памяти.
Настройки MySQL должны быть такими, чтобы потребление памяти было сбалансировано!
Вроде, простое и понятное правило, но о нем часто забывают. Каюсь, сами пару раз (в начале, на прототипе :)) получили OOM (Out of memory) и — как следствие — «убитый» операционной системой процесс mysqld.
В идеале — процесс mysqld должен работать так, чтобы полностью помещаться в оперативной памяти и не оперировать свопом.
Обязательно — все процессы системы должны помещаться в память+swap.
Зачастую подсчеты, сколько памяти может потребить mysqld, оказываются для многих неочевидными.
Формула примерно такова:
- Размер глобальных буферов: key_buffer_size + tmp_table_size + innodb_buffer_pool_size + innodb_additional_mem_pool_size + innodb_log_buffer_size + query_cache_size
- Размер буфера для одного коннекта: read_buffer_size + read_rnd_buffer_size + sort_buffer_size + thread_stack + join_buffer_size
- Максимально возможное использование памяти: глобальные буферы + буферы подключений * максимальное число коннектов
* * *
Спасибо, что дочитали до этого места! :)
Мы рассмотрели лишь некоторую часть практических вопросов и приемов, которые мы используем в работе «Битрикс24». В том числе благодаря им, сервис растет и развивается.
Надеемся, что наш опыт поможет и вам в создании и развитии ваших проектов.
И уже сейчас видно, что объема одной статьи совершенно недостаточно. В ближайшее время постараемся продолжить тему использования MySQL в больших проектах, поделимся новыми рецептами и опишем наиболее интересные и востребованные темы более подробно.
habr.com
Персонализация» / Блог компании 1С-Битрикс / Хабр
В сентябре этого года в Киеве прошла конференция, посвящённая большим данным — BigData Conference. По старой традиции, мы публикуем в нашем блоге некоторые материалы, представленные на конференции. И начинаем с доклада Александра Демидова.Сейчас очень многие интернет-магазины осознали, что одной из главных задач для них является повышение собственной эффективности. Возьмем два магазина, каждый из которых привлек по 10 тыс. посетителей, но один сделал 100 продаж, а другой 200. Вроде бы, аудитория одинаковая, но второй магазин работает в два раза эффективнее.
Тема обработки данных, обработки моделей посетителей магазинов актуальна и важна. Как вообще работают традиционные модели, в которых все связи устанавливаются вручную? Мы составляем соответствие товаров в каталоге, составляем связки с аксессуарами, и так далее. Но, как говорит расхожая шутка:
Невозможно предусмотреть подобную связь и продать покупателю что-то совершенно несвязанное с искомым. Но зато следующей женщине, которая ищет зеленое пальто, мы можем порекомендовать ту самую красную сумку на основании похожей модели поведения предыдущего посетителя.
Такой подход очень ярко иллюстрирует случай, связанный с ритейлинговой сетью Target. Однажды к ним пришел разъяренный посетитель и позвал менеджера. Оказалось, что интернет-магазин в своей рассылке несовершеннолетней дочери этого самого посетителя прислал предложение для беременных. Отец был крайне возмущен этим фактом: «Что вы вытворяете? Она несовершеннолетняя, какая она беременная?». Поругался и ушел. Через пару недель выяснилось, что девушка на самом деле беременна. Причем интернет-магазин узнал об этом раньше ее самой на основе анализа ее предпочтений: заказанные ею товары были сопоставлены с моделями других посетительниц, которые действовали примерно по тем же сценариям.
Результат работы аналитических алгоритмов для многих выглядит как магия. Естественно, многие проекты хотят внедрить у себя подобную аналитику. Но на рынке мало игроков с достаточно большой аудиторией, чтобы можно было действительно что-то посчитать и спрогнозировать. В основном, это поисковики, соцсети, крупные порталы и интернет-магазины.
Наши первые шаги в использовании больших данных
Когда мы задумались о внедрении анализа больших данных в наши продукты, то задали себе три ключевых вопроса:- Наберется ли у нас достаточно данных?
- Как мы их будем обрабатывать? У нас нет в штате математиков, мы не обладаем достаточной компетенцией по работе с «большими данными».
- Как это всё внедрять в существующие продукты?
В итоге мы организовали в рамках проекта внутренний стартап. Поскольку мы не знали, с какого конца браться, решили начать с решения мелкой задачи: как собирать и хранить данные. Этот маленький прототип был нарисован за 30-40 минут:
Существует термин MVP — minimum viable product, продукт с минимальным функционалом. Мы решили начать собирать технические метрики, скорость загрузки страниц у посетителей, и предоставлять пользователям аналитику по скорости работы их проекта. Это еще не имело отношения ни к персонализации, ни к BigData, но позволяло нам научиться обрабатывать всю аудиторию всех посетителей.
В JavaScript существует инструмент под названием Navigation Timing API, который позволяет собирать на стороне клиента данные по скорости страницы, продолжительности DNS resolve, передачи данных по сети, работы на Backend’е, отрисовки страницы. Всё это можно разбивать на самые разные метрики и потом выдавать аналитику.
Мы прикинули, сколько примерно магазинов работает на нашей платформе, сколько данных нам надо будет собирать. Потенциально это десятки тысяч сайтов, десятки миллионов хитов в день, 1000-1500 запросов на запись данных в секунду. Информации очень много, куда ее сохранять, чтобы потом с ней работать? И как обеспечить для пользователя максимальную скорость работы аналитического сервиса? То есть наш JS-счетчик не только обязан очень быстро давать ответ, но и не должен замедлять скорость загрузки страницы.
Запись и хранение данных
Наши продукты в основном построены на PHP и MySQL. Первым желанием было просто сохранять всю статистику в MySQL или в любой другой реляционной базе данных. Но даже без тестов и экспериментов мы поняли, что это тупиковый вариант. В какой-то момент нам просто не хватит производительности либо при записи, либо при выборке данных. А любой сбой на стороне этой базы приведет к тому, что, либо сервис будет работать крайне медленно, либо вообще окажется неработоспособен.Рассмотрели разные NoSQL-решения. Поскольку у нас большая инфраструктура развернута в Amazon, то в первую очередь обратили внимание на DynamoDB. У этого продукта есть некоторое количество преимуществ и недостатков по сравнению с реляционными базами. При записи и масштабировании DynamoDB работает лучше и быстрее, но какие-то сложные выборки делать будет гораздо сложнее. Также есть вопросы с консистентностью данных. Да, она обеспечивается, но, когда вам надо будет постоянно выбирать какие-то данные, не факт, что вы всегда выберете актуальные.
В итоге мы стали использовать DynamoDB для агрегации и последующей выдачи информации пользователям, но не как хранилище для сырых данных.
Рассматривали колоночные базы данных, которые работают уже не со строками, а с колонками. Но из-за низкой производительности при записи пришлось их отвергнуть.
Выбирая походящее решение, мы обсудили самые разные подходы, начиная с записи текстового лога :) и заканчивая сервисами очередей ZeroMQ, Rabbit MQ и т.п. Однако в итоге выбрали совсем другой вариант.
Kinesis
Так совпало, что к тому моменту Amazon разработал сервис Kinesis, который как нельзя лучше подошел для первичного сбора данных. Он представляет собой своеобразный большой высокопроизводительный буфер, куда можно писать всё, что угодно. Он очень быстро принимает данные и рапортует об успешной записи. Затем можно в фоновом режиме спокойно работать с информацией: делать выборки, фильтровать, агрегировать и т.д.Судя по представленным Amazon данным, Kinesis должен был легко справиться с нашей нагрузкой. Но оставался ряд вопросов. Например, конечный пользователь — посетитель сайта — не мог писать данные напрямую в Kinesis; для работы с сервисом необходимо «подписывать» запросы, используя относительно сложный механизм авторизации в Amazon Web Services v. 4. Поэтому необходимо было решить, как сделать так, чтобы Frontend отправлял данные в Kinesis.
Рассматривали следующие варианты:
- Написать на чистом nginx некую конфигурацию, которая будет проксировать в Kinesis. Не получалось, логика слишком сложная.
- Nginx в виде Frontend + PHP-Backend. Выходило сложно и дорого по ресурсам, потому что при таком количестве запросов любой Backend рано или поздно перестанет справляться, его надо будет горизонтально масштабировать. А мы еще не знаем, взлетит ли проект.
- Nginx + свой модуль на С/С++. Долго и сложно с точки зрения разработки.
- Nginx + ngx_http_perl_module. Вариант с модулем, блокирующим запросы. То есть запрос, который пришел в этом треде блокирует обработку других запросов. Здесь те же недостатки, что и с использованием какого-либо Backend’a. К тому же в документации к nginx было прямо сказано: «Модуль экспериментальный, поэтому возможно все».
- Nginx + ngx_lua. На тот момент мы еще не сталкивались с Lua, но этот модуль показался любопытным. Нужный вам кусок кода, пишется прямо в конфиг nginx на языке, чем-то похожем на JavaScript, либо выносится в отдельный файл. Таким образом можно реализовать самую странную, неординарную логику, которая вам нужна.
Lua
Язык очень гибкий, позволяет обрабатывать и запрос, и ответ. Может встраиваться во все фазы обработки запроса в nginx на уровне рерайта, логирования. На нем можно писать любые подзапросы, причем неблокирующие, с помощью некоторых методов. Существует куча дополнительных модулей для работы с MySQL, с криптующими библиотеками, и так далее.За два-три дня мы изучили функции Lua, нашли нужные библиотеки и написали прототип.
На первом нагрузочном тесте, конечно же… всё упало. Пришлось настроить Linux под большие нагрузки — оптимизировать сетевой стек. Эта процедура описана во многих документах, но почему-то не делается по умолчанию. Основной проблемой оказалась нехватка портов для исходящих соединений с Kinesis.
/etc/sysctl.conf (man sysctl) # диапазон портов исходящих коннектов net.ipv4.ip_local_port_range=1024 65535 # повторное использование TIME_WAIT сокетов net.ipv4.tcp_tw_reuse=1 # время пребывания сокета в FIN_WAIT_2 net.ipv4.tcp_fin_timeout=15 # размер таблиц файрволла net.netfilter.nf_conntrack_max=1048576 # длина очереди входящих пакетов на интерфейсе net.core.netdev_max_backlog=50000 # количество возможных подключений к сокету net.core.somaxconn=81920 # не посылать syncookies на SYN запросы net.ipv4.tcp_syncookies=0Мы расширили диапазон, настроили тайм-ауты. Если вы используете встроенный firewall, типа Iptables, то нужно увеличить для него размер таблиц, иначе они очень быстро переполнятся при таком количестве запросов. Заодно надо скорректировать размеры всяких бэклогов для сетевого интерфейса и для TCP-стека в самой системе.
После этого всё успешно заработало. Система стала исправно обрабатывать 1000 запросов в секунду, и для этого нам хватило одной виртуальной машины.
В какой-то момент мы всё-таки уперлись в потолок и стали получать ошибки “connect() to [...] failed (99: Cannot assign requested address) while connecting to upstream”, хотя ресурсы системы еще не были исчерпаны. По LA нагрузка была близка к нулю, памяти достаточно, процессор далек от перегрузки, но во что-то уперлись.
Решить проблему удалось путем настройки в nginx keepalive-соединений.
upstream kinesis { server kinesis.eu-west-1.amazonaws.com:443; keepalive 1024; } proxy_pass https://kinesis/; proxy_http_version 1.1; proxy_set_header Connection "";Машина с двумя виртуальными ядрами и четырьмя гигабайтами памяти легко обрабатывает 1000 запросов в секунду. Если нам надо больше, то либо добавляем ресурсов этой машине, либо масштабируем горизонтально и ставим за любым балансировщиком 2, 3, 5 таких машин. Решение получается простое и дешевое. Но главное, что мы можем собирать и сохранять любые данные и в любом количестве.
На создание прототипа, собирающего до 70 млн хитов в сутки, ушла примерно неделя. Готовый сервис «Скорость сайтов» для всех клиентов «1С-Битрикс: Управление сайтом» был создан за один месяц усилиями трёх человек. Система не влияет на скорость отображения сайтов, имеет внутреннее администрирование. Стоимость услуг Kinesis — 250 долларов в месяц. Если бы мы делали всё на собственном железе, писали полностью свое решение на любом хранилище, то получилось бы гораздо дороже с точки зрения обслуживания и администрирования. И гораздо менее надежно.
Рекомендации и персонализации
Общую схему системы можно представить следующим образом:Она должна регистрировать события, сохранять, выполнять какую-то обработку и что-то отдавать клиентам.
Мы создали прототип, теперь надо перейти от технических метрик к оценке бизнес-процессов. По сути, нам неважно, что мы собираем. Можно передавать что угодно:
- Куки
- Хэш-лицензии
- Домен
- Категорию, ID и название товара
- ID рекомендации
Хиты можно классифицировать по видам событий. Что нам интересно с точки зрения магазина?
Все технические метрики мы можем собирать и привязывать уже к бизнес-метрикам и последующей аналитике, которая нам потребуется. Но что делать с этим данными, как их обрабатывать?
Пара слов о том, как работают системы рекомендации.
Ключевой механизм, который позволяет рекомендовать посетителям какие-то товары, это механизм коллаборативной фильтрации. Существует несколько алгоритмов. Самый простой — соответствие user-user. Мы сопоставляем профили двух пользователей, и на основании действий первого из них можем прогнозировать для другого пользователя, который выполняет похожие действия, что в следующий момент ему понадобится тот же товар, который заказывал первый пользователь. Это наиболее простая и логически понятная модель. Но она имеет некоторые минусы.
- Во-первых, очень мало пользователей с одинаковыми профилями.
- Во-вторых, модель не очень устойчивая. Пользователи смотрят самые разные товары, матрицы соответствий постоянно меняются.
- Если мы охватываем всю аудиторию наших интернет-магазинов, то это десятки миллионов посетителей. И чтобы найти соответствия по всем пользователям, нам нужно перемножить эту матрицу саму на себя. А перемножение таких миллионных матриц — это нетривиальная задача с точки зрения алгоритмов и инструментов, которые мы будем использовать.
Есть еще один подход — content based-рекомендации. Анализируются разделы и товары, которыми интересовался пользователь, и его поисковые запросы, после чего выстраивается вектор пользователя. И в качестве подсказок предлагаются те товары, чьи векторы оказываются ближе всего к вектору пользователя.
Можно не выбирать какой-то один алгоритм, а использовать их все, комбинируя друг с другом. Какие есть для этого инструменты:
- • MapReduce. Если до конца в нем разобраться, то использование не вызовет затруднений. Но если вы будете «плавать» в теории, то сложности гарантированы.
- • Spark. Работает гораздо быстрее по сравнению с традиционным MapReduce, потому что все структуры хранит в памяти, и может использовать их повторно. Также он гораздо гибче, в нем удобнее делать сложные выборки и агрегации.
Если вы программируете на Java, то работа со Spark не вызовет особых затруднений. Здесь используется реляционная алгебра, распределенные коллекции, цепочки обработки.
Архитектура нашего проекта
Мы считываем данные из Kinesis с помощью простых воркеров, написанных на PHP. Почему PHP? Просто потому, что он нам привычнее, и нам так удобнее. Хотя у Amazon есть SDK для работы с их сервисами практически для всех популярных языков. Затем делаем первичную фильтрацию хитов: убираем многочисленные хиты поисковых ботов и т.п. Далее отправляем ту статистику, которую можем сразу отдавать в онлайне, в Dynamo DB.
Основной массив данных для последующей обработки, для построения моделей в Spark'е и т.д. мы сохраняем в S3 (вместо традиционного HDFS мы используем хранилище Амазона). Последующей математикой, алгоритмами коллаборативной фильтрации и машинного обучения занимается наш кластер рекомендаций, построенный на базе Apache Mahout.
- Для обработки данных мы используем Apache Hadoop/MapReduce, Apache Spark, Dynamo DB (NoSQL).
- Для математических расчетов задействуется Apache Mahout, а масштабная обработка умножения матриц делается с использованием парадигмы MapReduce.
- Данные обрабатываются на динамических вычислительных кластерах в облаке Amazon.
- Хранение осуществляется в объектном Amazon S3 и частично — в NoSQL DynamoDB.
К тому же вся система получается гораздо дешевле. Все наши терабайты данных выгоднее положить в S3, чем поднять отдельные сервера с дисковыми хранилищами, заботиться о бэкапе и т.д. Гораздо проще и дешевле поднять Kinesis как готовый сервис, начать его использовать буквально в считанные минуты или часы, чем настраивать инфраструктуру, администрировать ее, и решать какие-то низкоуровневые задачи по обслуживанию.
Для разработчика интернет-магазина, который работает на нашей платформе, всё это выглядит как некий сервис. Для работы с этим сервисом используется набор API, с помощью которых можно получить полезную статистику и персональные рекомендации для каждого посетителя.
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=recommend&uid=#кука#&count=3&aid=#хэш_лицензии#
- uid — кука пользователя.
- aid — хэш лицензии.
- сount — число рекомендаций.
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=simitems&aid=#хэш_лицензии#&eid=#id_товара#&count=3&type=combined&uid=#кука#
- uid – кука пользователя.
- aid – хэш лицензии.
- eid – ID товара
- type — view|order|combined
- сount – размер выдачи.
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=sim_domain_items&aid=#хэш_лицензии#&domain=#домен#&count=50&type=combined&uid=#кука#
- uid – кука пользователя.
- aid – хэш лицензии.
- domain – домен сайта.
- type — view|order|combined
- сount – размер выдачи.
При построении модели пользователя учитывается вся статистика его просмотров, а не только текущая сессия. Причем все модели деперсонализированы, то есть каждый посетитель существует в системе только в виде безликого ID. Это позволяет сохранить конфиденциальность.
Мы не делим посетителей в зависимости от магазинов, которые они посещают. У нас единая база данных, и каждому посетителю присваивается единый идентификатор, по каким бы магазинам он ни ходил. В этом одно из главных преимуществ нашего сервиса, потому что маленькие магазины не имеют достаточно большой статистики, позволяющей достоверно прогнозировать поведение пользователей. А благодаря нашей единой базе данных даже магазин с 10 посещениями в день получает возможность с высокой вероятностью успеха порекомендовать товары, которые будут интересны именно этому посетителю.
Данные могут устаревать, так что при построении пользовательской модели мы не будем учитывать статистику годовой давности, например. Учитываются только данные за последний месяц.
Практические примеры
Как выглядят на сайте предлагаемые нами инструменты?Блок персональных рекомендаций, который может быть на главной странице. Он индивидуален для каждого посетителя сайта.
Его можно отображать и в карточке конкретного товара:
Пример блока рекомендуемых товаров:
Блоки можно комбинировать, ища наиболее эффективно сочетание.
Заказы, проданные по персональной рекомендации, отмечаются в админке.
Сотруднику, обрабатывающему заказы, можно в админке сразу выводить список товаров, которые можно порекомендовать покупателю при оформлении.
В отличие от наших инструментов, у сторонних сервисов рекомендаций есть важный недостаток — достаточно маленькая аудитория. Для использования этих сервисов нужно вставить счетчик и виджет для отображения рекомендаций. В то время как наш инструментарий очень тесно интегрирован с платформой, и позволяет дорабатывать выдаваемые посетителям рекомендации. Например, владелец магазина может отсортировать рекомендации по цене или наличию; подмешать в выдачу другие товары.
Метрики качества
Возникает главный вопрос: насколько эффективно работает всё вышеописанное? Как вообще измерить эффективность?- Мы вычисляем отношение просмотров по рекомендациям к общему количеству просмотров.
- Также измеряем количество заказов, сделанных по рекомендации, и общее количество заказов.
- Проводим измерения по state-машинам пользователей. У нас есть матрица с моделями поведения за период в три недели, мы даем по ним какие-то рекомендации. Затем оцениваем состояние, например, через неделю, и сравниваем размещенные заказы с теми рекомендациями, которые мы могли бы дать в будущем. Если они совпадают, то мы рекомендуем правильно. Если не совпадают, надо подкручивать или совсем менять алгоритмы.
- А/В тесты. Можно просто разделить посетителей интернет-магазина на группы: одной показать товары без персональных рекомендаций, другой — с рекомендациями, и оценить разницу в продажах.
По нашим данным, рост конверсии у нас составляет от 10 до 35%. Даже 10% — это огромный показатель для интернет-магазина с точки зрения инвестирования. Вместо того, чтобы вбухивать больше денег в рекламу и привлечение, пользователи эффективнее работают со своей аудиторией.
Но почему такой большой разброс по росту конверсии? Это зависит от:
- разнообразия ассортимента,
- тематики,
- общего количества товаров на сайте,
- специфики аудитории,
- связок товаров.
Другие сферы применения
Где еще можно применять подобный инструментарий, помимо интернет-магазинов? Практически в любом интернет-проекте, который хочет увеличить аудиторию. Ведь товарной единицей может быть не только нечто материальное. Товаром может быть статья, любой текстовый материал, цифровой продукт, услуга, что угодно.- Мобильные операторы, сервис-провайдеры: выявление клиентов, готовых уйти.
- Банковский сектор: продажа допуслуг.
- Контентные проекты.
- CRM.
- Триггерные рассылки.
Статистика проекта BigData: Персонализация
На данный момент на нашей платформе работает 17 тыс. магазинов, система обсчитывает порядка 440 млн событий в месяц. Общий товарный каталог содержит около 18 млн наименований. Доля заказов по рекомендации от общего количества заказов: 9–37%.Как видите, данных очень много, и они не лежат мертвым грузом, а работают и приносят пользу. Для работающих на нашей платформе магазинов этот сервис сейчас бесплатен. У нас открытый API, который можно модифицировать на стороне Backend’a и выдавать более гибкие рекомендации конкретным посетителям.
habr.com
незаметная CRM, которая работает за вас / Блог компании 1С-Битрикс / Хабр
Совсем недавно вышло очередное обновление Битрикс24. Оно касается по большей части CRM, получения лидов и омниканальности. Конечно, хотелось о нём рассказать, но получалось как-то сухо, нужно было опробовать его в боевых условиях и уже рассмотреть реальные кейсы. Мы накатили обновление у одного из наших старых клиентов чуть раньше, чем остальным, и попросили руководителя отдела продаж и сисадмина рассказать о том, как они используют CRM в Битрикс24, поделиться мнением о самых последних изменениях в системе. Рассказ вышел живым, сегодня мы публикуем его почти полностью, с некоторыми нашими примечаниями.Итак, сегодня в эфире — тотальное обновление CRM в Битрикс24: все лиды собираются в CRM без участия менеджера,1С-трекер подтягивает данные о продажах из всех источников, онлайн-чат работает на сайте (для всех пользователей станет доступен осенью — прим. Битрикс24) и опять-таки моментально всё передаёт в систему. Грань между онлайном и оффлайном стирается — в игру вступает незаметная CRM и мощная сеть коммуникаций, из которой ни один лид не уйдёт живым необработанным. И, конечно же, омниканальность — возможность через CRM коммуницировать с клиентом из любого источника, без переключений на каналы, потерянных лидов и сообщений.
Клиентская база: собрать и сохранить
Начну с того, что меня порадовало в первую очередь. Не хочу писать штампами, скажу, как вижу: новый Битрикс24 тянет лиды из всех возможных источников. Конечно, в пресс-релизах это можно назвать интеллектуальным взаимодействием со всеми каналами, но это не передаст и части сути. Только подумайте: сам (!) тянет лиды, собирает их, заносит в CRM — и уже не важно, в каком часовом поясе или стране обратились в компанию. То есть ты больше не теряешь ни одного сообщения. И у тебя работает незаметная CRM. Примерно как-то так я и представлял автоматизацию.Захват и сохранение лидов, а также фиксация всех обращений клиентов теперь обеспечиваются новой функциональностью Битрикс24 «Открытые линии».Открытые линии собирают сообщения клиентов из ВКонтакте, Facebook, Telegram и Skype (WhatsApp и другие мессенджеры — в планах), распределяют сообщения по очереди и перенаправляют свободным сотрудникам, находящимся на рабочем месте. Идентификация клиента проводится в CRM, там же фиксируется вся переписка. В открытых линиях доступна вся статистика по работе с сообщениями от клиентов, анализируется степень их удовлетворённости. Ни одно сообщение не потеряется. Кстати, один из каналов открытых линий — это онлайн-чат для сайта, который интегрируется с CRM (для всех пользователей станет доступен осенью). Практика показывает, что это распространённый способ общения потенциальных клиентов с компанией.
Мы работаем в сфере, где конкуренция достаточно высокая. А чем она выше, тем дороже обходится привлечение и удержание каждого нашего клиента. Нам важно не только провести клиента через все этапы продажи, но и сохранить его для дальнейшего взаимодействия, например, допродаж. Примерно с такими, в общем-то, тривиальными целями мы и внедрили Битрикс24 ещё пару лет назад. За это время он сильно изменился, но последнее обновление — это вот просто wow. Как мы работали до этого июня?- Создаётся лид — пока ещё не клиент, но уже лицо/компания, проявившие интерес к продукту или услуге. Фиксируются информация по нему, в том числе статус, возможная сумма сделки, источник. При заведении лида статусу и источнику нужно уделить особое внимание — в дальнейшем по эти двум параметрам можно анализировать эффективность каналов привлечения клиентов.
- После взаимодействия с лидом в случае положительного результата на его основании можно создать контакт и компанию — так появляется новый элемент клиентской базы. Ему можно высылать коммерческие предложения, ставить по нему задачи, совершать сделки.
- После завершения сделки клиент остаётся в базе и с ним нужно продолжать работать — совершать допродажи, предлагать комплиментарные товары и услуги. Дело в том, что такой клиент уже нисколько не стОит в плане привлечения, а вот его удержание может принести дополнительный доход.
То, что сейчас назвали открытыми линиями, ещё и экономит время сотрудников — им больше не нужно пересказывать друг другу содержание общения или переспрашивать, что же ответить клиенту: к коммуникации можно подключить ещё одного сотрудника (в том числе скрытого) или переадресовать клиента более компетентным в конкретном вопросе коллегам (например, в ходе презентации товара менеджер по продажам может переадресовать технический вопрос инженеру).
Работа в CRM: высокие ставки на большие продажи
CRM сейчас что только ни делают, но для нашей компании её основное назначение — решение текущих задач, которые приведут к повышению объёма продаж. Наш Битрикс24 сосредоточен именно на этом. В большинстве компаний, и наша не исключение, сценарий обработки клиента такой: лид — квалификация лида — потенциальный клиент — переговоры — сделка — допродажа. Без фиксации достоверной и точной информации по каждому этапу перейти на следующий труднее. И клиенты часто отваливаются на каком-то из этапов из-за того, что менеджер что-то забыл, например, выслать КП, перезвонить или вообще потерял заявку. А вот Битрикс24 не даёт это сделать — там вся цепочка автоматизирована, и менеджер ведёт клиента по заранее заданной схеме.Вот давайте возьмём нашего менеджера Настю и посмотрим, как она работает. Заходим в Битрикс24 и видим, что поступили обращения из Facebook, есть регистрация с сайта и вопрос из ВКонтакте. Это Настино направление и поэтому она должна взять обращения в работу. Что самое интересное, у нас ни она, ни другие менеджеры не имеют доступа к социальным сетям и Телеграму — это работа SMM-менеджера и в неё никто не вникает. А ему, в свою очередь, не интересны запросы на продажи — он периодически их мониторил и присылал пачками, просроченные и актуальные. Сейчас проблема решена. Кстати, ВКонтакте обращение из Приморского края, у нас разница +7 часов, ответить на него мы не могли, и оно запросто бы утонуло в других сообщениях нашего паблика.Далее Настя связалась с этими лидами, зафиксированы звонки и один чат. В итоге двое запросили прайс, пошли дальше по воронке. Один из них после знакомства с прайсом попросил счёт, другой — пока общается о скидках, у него большая партия. То есть фактически мы имеет двух горячих клиентов. А что бы было, если бы им ответили не сразу, а дней через пять, когда в конце недели пиарщик посмотрел бы сообщения в социальных сетях? Никто не даст гарантию, что за это время лид не попадёт к проворному конкуренту.
Кстати, об оперативности — лично меня очень порадовал чат на сайте, у него хорошая конверсия, около 10%, потому что это уже живое общение, пользователь обращается мотивированно. Создали онлайн-чат в Битрикс24 и повесили его на сайт. В принципе, чат другого разработчика стоял у нас и раньше, но менеджер в лучшем случае успевал через 5 минут ответить, и это считалось хорошо. Ну, бывает, отвлекся, куча посторонних дел, не получается всё время отдельный сервис мониторить. А вот с Битрикс24 всё как-то по-другому работает. Сидит сотрудник, разбирает заявки, а тут ему в чатик падает сообщение от клиента: «А у вас доставка по всей России?». Менеджер тут же реагирует и никуда не переключаясь отвечает: «Ну конечно. Прямо до вашего поселка Перепелкино доставим. Курьером». Дальше он делает КП, выставляет счёт клиенту. И всё это парой кликов, т.к. Битрикс24 уже создал лид по этому клиенту, занёс все доступные данные.
Для тех, кто ещё не знаком с CRM в Битрикс24, перечислим основные функции.- Учитываются все лиды, которые затем трансформируются в клиентов. Фиксируется источник лида, его интерес, потребность, контакты.
- В дальнейших отношениях с клиентами в CRM отслеживаются заказы и оплаты, выставляются счета и коммерческие предложения, т.е. проводятся сделки. Кстати, о счетах. Онлайн-платежи проникли во все сферы коммерции и нашей команде кажется логичным их использование в CRM — теперь можно не отправлять счет в формате PDF, достаточно отправить ссылку на документ. Для каждого счёта системой генерится индивидуальная ссылка: вы просто отправляете её клиенту, а он оплачивает счет через подключенные платежные системы.
- Происходят коммуникации с клиентом. Причём теперь, кроме традиционных виртуальной АТС и личного кабинета клиента, в Битрикс24 добавлены возможности общения через чат на сайте и механизм открытых линий. Система нацелена на то, чтобы каждый звонок поступал нужному менеджеру или перенаправлялся на его мобильный телефон. При этом вместе со звонком поднимается карточка клиента — менеджер видит профиль и ведёт предметные переговоры на актуальных данных.
- Работа менеджеров автоматизируется с помощью бизнес-процессов. В Битрикс24 включён визуальный редактор процессов, в котором можно легко создавать цепочки исполнения задач, выбирая нужные элементы. Это удобный и понятный конструктор, не требующий особых знаний. Однако, если вы ходите назначить в логике процесса исполнение скрипта на PHP, это тоже очень просто — вы встраиваете кусок кода прямо в блок.
- Осуществляется контроль и планирование с помощью инструментов задач и календаря. Прямо из CRM можно ставить задачи с привязкой к клиентам и контактам, планировать встречи и звонки. Таким образом, сотрудники не забудут ни об одном взаимодействии.
- Строится отчётность по итогам периода. Уже отходят в прошлое времена, когда отчёты были лишь красивой картинкой для начальства или партнёров. В Битрикс24 ими могут пользоваться все. Это важный инструмент анализа проделанной работы, подведения итогов и планирования. В частности, в новой версии Битрикс24 изменилась воронка продаж — любимый отчёт коммерческой службы и дирекции, наглядный, простой и при этом информативный. Теперь это мультиворонки, которые строятся по разным продуктам с разным типом продаж.
- Ведётся переписка. В новой версии каждый сотрудник может подключить свой почтовый ящик к email-трекеру и фиксировать историю переписки с клиентами в CRM. Трекер распознаёт новые входящие и исходящие контакты и автоматически сохраняет их как лиды. Таким образом, вся информация аккумулируется в CRM.
- Используются веб-формы — ещё одна новинка в Битрикс24, которая понравится не только владельцам интернет-магазинов (для них это просто must have), но и всем, кто хочет собирать лиды с сайтов и лендингов. И вновь — не нужно быть программистом, чтобы создавать формы: покупки, обратной связи, анкеты клиента, заявки на кредит, регистрации на сайте, предзаказ и т.д. Цепочка простая: выбираете набор полей для формы из сущностей CRM — загружаете форму на сайт — результаты заполнения автоматически сохраняются в CRM, ответственный менеджер получает уведомления. Есть возможность создания форм с оплатой. Приятная и полезная штука — формы можно просматривать с помощью аналитики форм в Яндекс.Метрике, а значит, всегда есть возможность оценить результат и внести коррективы.
- Работает мобильная версия CRM, интерфейс которой полностью обновлён, стал удобнее и дружелюбнее к пользователю. Прямо во время разговора можно создавать сделку, добавлять товары или услуги, выставлять счета. На случай, если вы боитесь что-то забыть, все разговоры автоматически записываются и сохраняются в CRM — вернувшись в офис, вы можете их прослушать повторно.
Интеграции для полной автоматизации
Для более полного охвата бизнеса и комплексной автоматизации CRM-система должна уметь интегрироваться со сторонними приложениями. Это позволит собирать ещё более точную информацию и выстраивать настоящую омниканальность, которая особенно важна в ритейле и сервисе. Битрикс24 поддерживает интеграции и позволяет создавать новые с помощью API.Интеграции мы обсудили с сисадмином той же компании. Он и сеть администрирует, и скрипты пишет, и занимается вопросами информационной безопасности — в общем, тянет на себе инфраструктуру.
Интеграция с сайтом
Наш сайт работает на платформе «1С-Битрикс» — это была заказная разработка, но сейчас развиваю и администрирую его я. Продажники радуются, что вот уже как несколько недель все запросы с сайта (лиды) автоматически прогружаются в CRM, им не нужно собирать и добавлять их вручную. У нас на сайте есть форма обратной связи, отдельная анкета-опросник, можно подписаться на рассылку и вот теперь чат Битрикс24, раньше был другой. Все, кто взаимодействует с формами, сразу попадают в CRM.Кстати, если ваш сайт работает на другой платформе, можно использовать веб-формы, из которых информация и будет попадать в CRM.Интеграция CRM с интернет-магазином
Установите связь CRM с вашим интернет-магазином (если он работает на платформе «1С-Битрикс»). Ваши менеджеры смогут обрабатывать заказы, полученные в интернет-магазине, непосредственно в CRM. Учет и анализ информации о клиентах поможет увеличить объём повторных продаж. Если платформа другая или даже сайта нет вовсе, формы всё равно можно использовать — они создаются из вашего Битрикс24 с адресом, оканчивающимся на .bitrix24.ru и доступны на публичной страничке.Интеграция с 1С
Благодаря интеграции с «1С» в вашей CRM всегда актуальный каталог товаров. Менеджеры CRM всегда в курсе прохождения оплаты по счетам, и им не нужно беспокоить бухгалтера. Ещё одно бесплатное обновление для всех тарифов «Битрикс24»: с помощью 1С-трекера можно фиксировать в CRM не только онлайн, но и традиционные продажи, используя информацию из 1С, оффлайн продажи попадают в CRM. Например, магазин бытовой техники продал утюг оффлайн, сведения о продаже поступили в 1С, оттуда автоматически перенеслись в CRM. То есть данные о реализации из всех источников незаметно попадают в CRM. Это как раз та самая омниканальность, когда вы можете собирать данные из всех каналов продаж и строить информативную и точную аналитику.Маркетплейс
Заодно мы поговорили с сисадмином о меркетплейсе и его опыте в нём.В магазине приложений Битрикс24 можно найти всё: конструктор документов, проверку контрагентов, различные почтовые сервисы, календари, курсы валют, звонилки, карты, скрипты звонков, складские программы, саппорт, коннекторы для многих популярных у бизнеса приложений и много чего ещё. Что-то платно, что-то бесплатно. Маркетплейс создаёт почти безграничные возможности для работы с Битрикс24 — его точно стоит полистать, тем более, что все приложения разделены на категории и вы можете найти только то, что нужно для вашей деятельности. Мне нравится. Своё пока не размещал, но думаю, не за горами.
По состоянию на 2016 год российский рынок предлагает огромное количество CRM. При этом большая часть программ не соответствуют этому названию, поскольку либо примитивны и не содержат и трети функций, либо масштабны и представляют собой уже почти ERP-системы. Битрикс24 подошёл к вопросу иначе: мы сделали CRM модулем комплексной корпоративной социальной сети и даже назвали её «незаметная CRM» — просто потому, что клиент ставится в центр бизнеса, но отношения с ним развиваются во взаимосвязи со всеми другими отношениями. Это удобно бизнесу, это понятно сотрудникам, это обеспечивает удовлетворённость клиента.habr.com